Clear Sky Science · zh
来自459种昆虫的声音数据集,用于生物声学机器学习
聆听隐秘的昆虫世界
自然界的“小多数”发出的许多声音并非来自鸟类或蛙类,而是来自昆虫:蟋蟀的鸣叫、螽斯的摩擦声以及蝉的嗡鸣。随着科学家们竞相弄清昆虫种群是否在全球范围内崩溃,这些声音可能提供关键线索。但要把全球范围内的咔哒声与嗡鸣转化为可用的数据,需要能“用耳朵”识别昆虫物种的计算机——这一点一直受制于缺乏合适的训练数据。本研究介绍了一个大型、精心策划的昆虫录音集合,旨在释放这一潜力。
昆虫鸣声为何重要
昆虫对生态系统至关重要,但证据表明许多物种在减少。传统监测——用陷阱捕捉或目视普查——速度慢、耗时且只能覆盖世界多样性的一小部分。声音提供了另一种途径。许多螽斯、蟋蟀和蝉会发出具有物种特异性的鸣声,这些鸣声传播范围广,可以用小型、廉价的录音设备捕捉。如果计算机能可靠地将这些鸣声与物种匹配,科学家乃至公民科学家就能以最小干扰在大陆尺度上监测昆虫多样性。
构建全球声音库
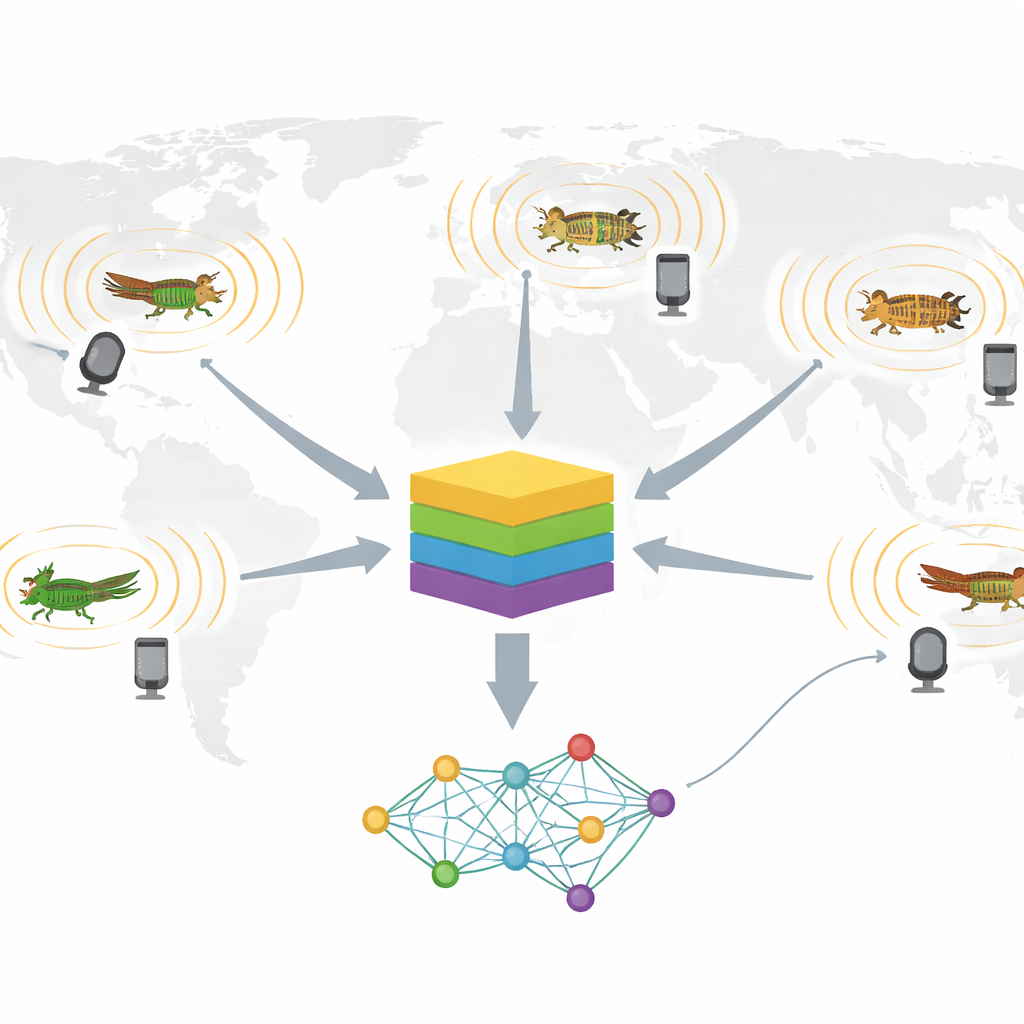
作者们组建了一个名为 InsectSet459 的新数据集,包含26,298个音频文件——约9.5天的声音,来自459种昆虫。大多数属于两个高度鸣叫的类群:直翅目(螽斯、蟋蟀及其亲缘种)和蝉科。研究团队并未自行录制这些昆虫,而是利用了三个主要的开放平台:xeno-canto、iNaturalist 和 BioAcoustica。这些网站托管着来自专家和公民科学家的带物种标签的录音,是丰富的原始素材来源。研究者只下载了经确认物种鉴定且具有开放许可的录音,并在尽可能保留声学多样性的前提下对文件进行了标准化和裁剪。
清理噪声
仅仅收集数千条录音还不够;机器学习数据集还必须避免隐藏的陷阱。团队进行了大量“去重”操作,删除了相同音频文件的重复上传,即便这些文件出现在不同用户名或不同平台上。他们限制每个物种的录音来自不同的时间和地点,将过长的文件裁剪为两分钟片段,转换不常见的格式,并确保每个物种至少有十个独立录音。与许多音频数据集不同,他们没有强制把所有文件统一到单一采样率。昆虫通常发出高频甚至超声的叫声,因此保留原始录音率——从8到500千赫不等——能够保存那些可能被丢失的重要细节。
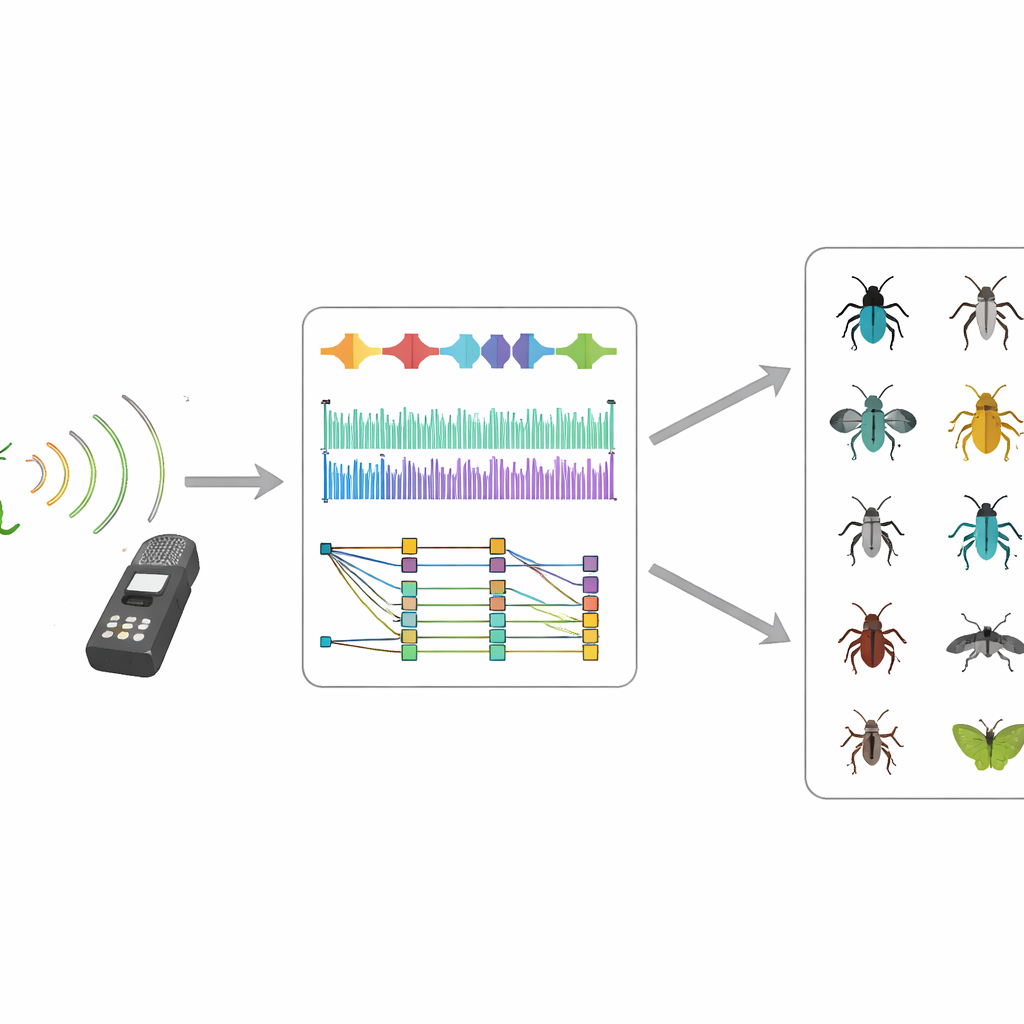
检验数据的效用
为了证明 InsectSet459 对自动识别确有用处,作者训练了两种最先进的深度学习模型,这些模型最初用于声音和图像任务。两种模型都将音频转换为类似图片的表示,展示随时间和频率变化的声能,然后学习将这些模式与物种关联。在未见过的录音上测试时,它们能以中等程度的成功率区分物种:在一种平衡漏报与误报的严格衡量下得分约57%,而简单准确率超过70%。对于录音数量多的物种,表现特别强劲——常常超过80%。对于仅有少量样本的物种,以及那些鸣声位于模型特征强调的频率范围之外的物种,性能则急剧下降。
未来的意义
尽管这些早期模型还远非完美,尤其是对稀有物种和极高频率发声者,但结果表明,一个单一、精心策划的数据集已经可以为数百种昆虫提供有用的自动识别能力。InsectSet459 意在成为基础:一个现实而具有挑战性的测试平台,用于试验新的声音表示方法、处理多重采样率以及应对自然不均衡的数据。随着研究人员改进算法——可能纳入超声信息、更好的数据增强以及区域特定的微调——该数据集可能有助于把夜间的鸣唱和嗡鸣转化为一个灵敏的全球昆虫生物多样性监测系统。
引用: Faiß, M., Ghani, B. & Stowell, D. A dataset of insect sounds from 459 species for bioacoustic machine learning. Sci Data 13, 499 (2026). https://doi.org/10.1038/s41597-026-07123-4
关键词: 昆虫生物声学, 生物多样性监测, 机器学习, 声学数据集, 公民科学