Clear Sky Science · nl
Een dataset met insectengeluiden van 459 soorten voor bioakoestische machine learning
Luisteren naar de verborgen wereld van insecten
Veel van de geluiden van de natuur’s “kleine meerderheid” komen niet van vogels of kikkers, maar van insecten: tjirpende krekels, raspende sprinkhanen en zoemende cicaden. Terwijl wetenschappers haasten om te begrijpen of insectenpopulaties wereldwijd in elkaar storten, kunnen deze geluiden cruciale aanwijzingen geven. Maar een wereldwijd koor van klikken en gezoem omzetten in harde data vereist computers die insectensoorten op gehoor kunnen herkennen—iets wat is tegengehouden door een gebrek aan geschikte trainingsdata. Deze studie introduceert een grote, zorgvuldig samengestelde verzameling insectopnames die dat potentieel moet ontsluiten.
Waarom insectenzangen ertoe doen
Insecten zijn essentieel voor ecosystemen, maar er zijn aanwijzingen dat veel soorten afnemen. Traditionele monitoring—insecten vangen in vallen of visuele tellingen—is traag, arbeidsintensief en dekt slechts een fractie van ’s werelds diversiteit. Geluid biedt een alternatieve route. Veel sprinkhanen, krekels en cicaden produceren soortspecifieke liedjes die ver reiken en vastgelegd kunnen worden met kleine, goedkope recorders. Als computers deze liedjes betrouwbaar aan soorten kunnen koppelen, kunnen wetenschappers en zelfs burgerwetenschappers de insectendiversiteit over continenten monitoren met minimale verstoring.
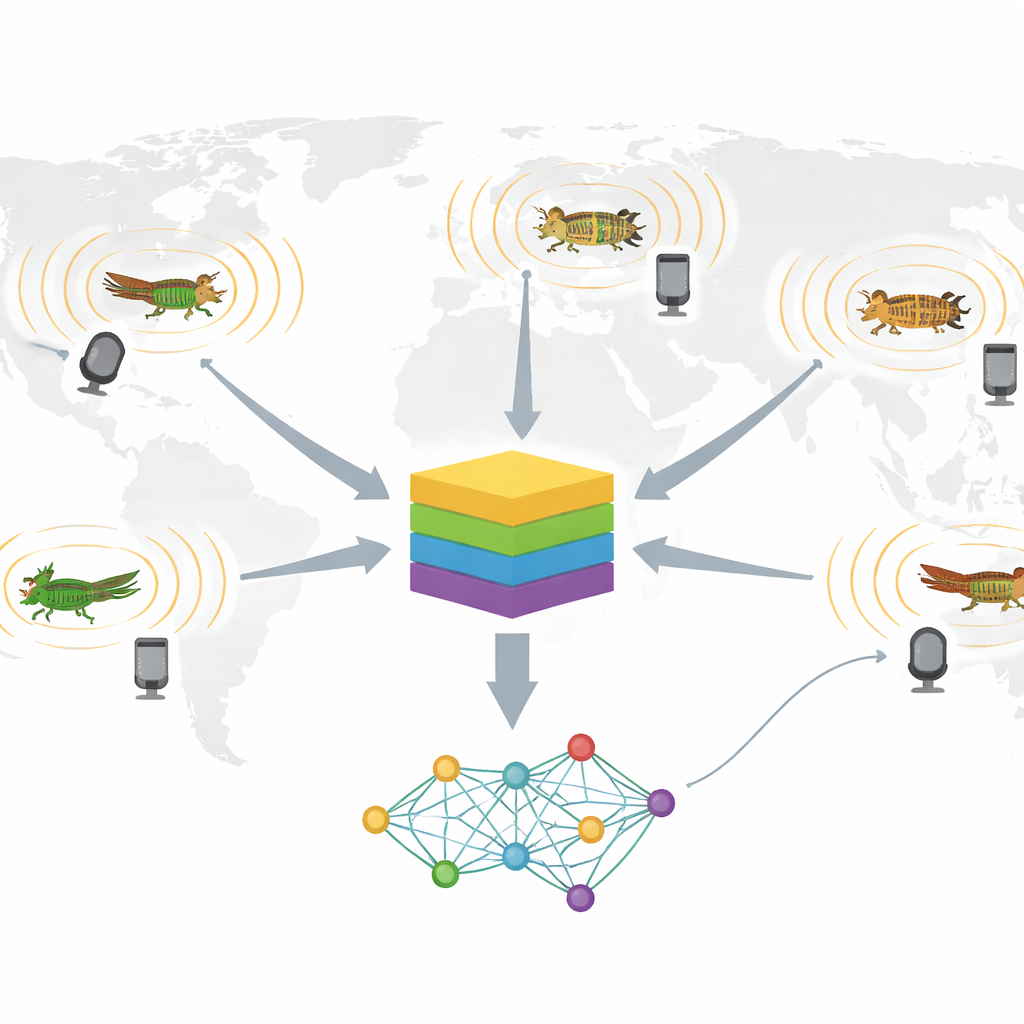
Een wereldwijde geluidbibliotheek opbouwen
De auteurs stelden een nieuwe dataset samen genaamd InsectSet459, met 26.298 audiobestanden—ongeveer 9,5 dagen aan geluid—van 459 insectensoorten. De meeste behoren tot twee sterk vocale groepen: Orthoptera (sprinkhanen, krekels en aanverwanten) en Cicadidae (cicaden). In plaats van zelf de insecten op te nemen, putte het team uit drie grote open platforms: xeno-canto, iNaturalist en BioAcoustica. Deze websites hosten soort-gelabelde opnames van zowel experts als burgerwetenschappers wereldwijd en vormen hierdoor rijke bronnen van ruwe data. De onderzoekers downloadden alleen opnames met bevestigde soortidentificaties en open licenties, en standaardiseerden en knipten de bestanden terwijl ze zoveel mogelijk akoestische diversiteit behielden.
Het geluid opschonen
Alleen duizenden opnames verzamelen is niet genoeg; een machine-learningdataset moet ook verborgen valkuilen vermijden. Het team voerde uitgebreide “deduplicatie” uit, waarbij herhaalde uploads van hetzelfde audiobestand werden verwijderd, zelfs wanneer ze onder verschillende gebruikersnamen of op verschillende platforms verschenen. Ze beperkten elke soort tot opnames van verschillende tijden en plaatsen, knipten lange bestanden tot segmenten van twee minuten, converteerden ongewone formaten en zorgden dat elke soort minstens tien afzonderlijke opnames had. In tegenstelling tot veel audiodatasets besloten ze niet alle bestanden naar één samplefrequentie te dwingen. Insecten produceren vaak hoogfrequente of zelfs ultrasone roepen, dus het behouden van de oorspronkelijke opnamesnelheden—variërend van 8 tot 500 kilohertz—bewaart belangrijke details die anders verloren zouden kunnen gaan.
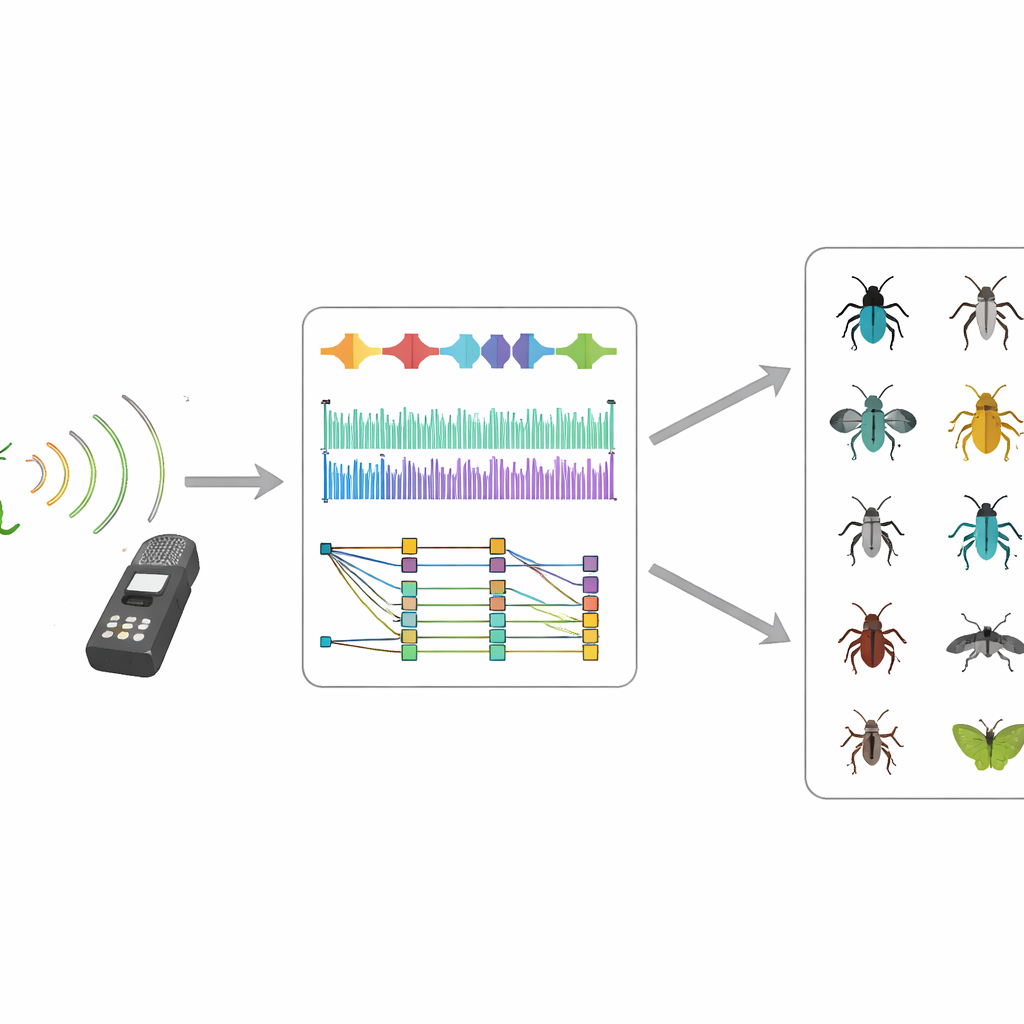
De data op de proef stellen
Om aan te tonen dat InsectSet459 daadwerkelijk nuttig is voor automatische herkenning, trainden de auteurs twee state-of-the-art deep learning-modellen die oorspronkelijk ontwikkeld zijn voor geluid- en afbeeldingtaken. Beide modellen zetten de audio om in beeldachtige representaties van geluidsenergie over tijd en frequentie, en leerden deze patronen aan soorten te koppelen. Getest op niet eerder geziene opnames, onderscheidden ze soorten met een matig succes in het algemeen: ongeveer 57% volgens een strikte maatstaf die gemiste detecties en valse alarmen in balans houdt, en meer dan 70% eenvoudige nauwkeurigheid. De prestaties waren vooral sterk—vaak boven 80%—voor soorten met veel opnames. Ze daalden scherp voor soorten die slechts door een paar voorbeelden werden vertegenwoordigd, en voor soorten waarvan de roepen buiten het frequentiebereik vielen dat in de kenmerken van de modellen werd benadrukt.
Wat dit betekent voor de toekomst
Hoewel deze vroege modellen verre van perfect zijn, vooral voor zeldzame soorten en zeer hoogfrequente roepers, laten de resultaten zien dat één enkele, goed samengestelde dataset al nuttige automatische herkenning van honderden insectensoorten kan aandrijven. InsectSet459 is bedoeld als fundament: een realistische, uitdagende testomgeving om te experimenteren met nieuwe manieren om geluid te representeren, om te gaan met meerdere samplefrequenties en met van nature onevenwichtige data. Naarmate onderzoekers algoritmen verfijnen—mogelijk met opname van ultrasone informatie, betere data-augmentatie en regiogebaseerde fijnafstemming—kan deze dataset helpen het nachtelijke koor van tjirpjes en gezoem om te zetten in een gevoelig, wereldwijd monitoringssysteem voor insectenbiodiversiteit.
Bronvermelding: Faiß, M., Ghani, B. & Stowell, D. A dataset of insect sounds from 459 species for bioacoustic machine learning. Sci Data 13, 499 (2026). https://doi.org/10.1038/s41597-026-07123-4
Trefwoorden: insecten bioakoestiek, biodiversiteitsmonitoring, machine learning, akoestische datasets, burgerwetenschap