Clear Sky Science · zh
基于大语言模型的新闻文本挖掘构建的中国高精度滑坡事件目录
为何这张滑坡图很重要
滑坡每年造成数千人死亡并摧毁房屋、道路与农田,但关于滑坡何时何地发生的基本事实却常常难以获得。本研究通过教计算机系统阅读多年的新闻报道,构建了覆盖中国大陆的一千多起滑坡的详尽目录。该公开数据集可用于改善预警系统、指导更安全的建设并支持更明智的灾害规划。
从零散报道到全国全景
此前,中国关于滑坡的记录仍不完整。官方通报通常统计每年或各省发生的事件数量,但很少包含精确的时间或位置。国际目录多聚焦全球范围内最大或最致命的事件,经常遗漏中文的地方性报道。因此,研究人员缺乏一幅清晰且精细的全国滑坡图谱,这也使得判断哪些坡面最危险或风险如何随时间变化变得困难。
让计算机“读”新闻
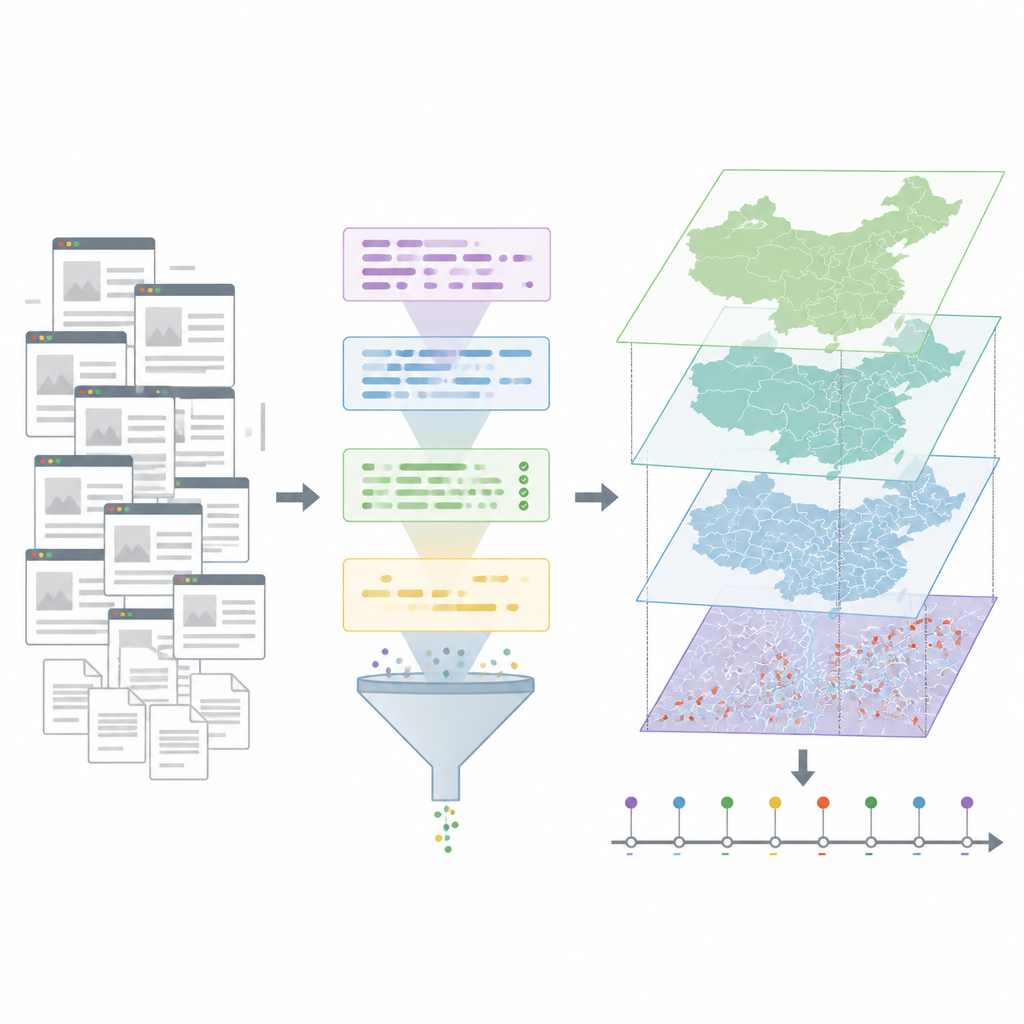
作者利用中国新闻网这一覆盖全国的重要新闻网站,抓取了2008年至2024年间超过33,000篇提及“滑坡”的文章,先排除了将该词作比喻使用的报道(如选举或市场崩溃)。接着,他们用一种在海量文本上训练的先进人工智能——大语言模型,从每条真实灾情报道中抽取关键事实。对每一起事件,系统尝试识别发生时间、地点、触发因素以及死亡、受伤或失踪人数。
清理、核验并将事件标注到地图上
原始AI输出并非完美,团队因此加入了多重核验环节。他们删除了缺乏明确时间或地点信息的记录,并剔除了仅给出省级等宽泛区域但无有用细节的报道。对于多篇报道描述同一灾害的常见问题,他们通过比较事件在时间上的接近程度和地点描述的相似性来合并可能的重复项。剩余记录均由人工专家复核并纠正错误。为将文字化的地名转为地图坐标,作者采用了在线制图服务与自定义规则选择最佳匹配,并对可疑案例再次进行人工检查。
新目录揭示了什么
最终数据集中包含1,582起具有罕见精确度的滑坡事件。约一半事件的日期精确到小时甚至分钟,超过80%定位在村级或具体地点(如路堑或山坡)。多数记录的滑坡由强降雨引发,尤其集中在华南地区;与地震相关的事件则在青藏高原东缘附近聚集。与两大全球滑坡数据库相比,该新目录在相同时期内收录的中国事件约为其两倍半,并且在时间和空间上的定位更为精确。
用AI读取新闻有多可靠
为检验准确性,团队将AI提取的记录与知名灾害的官方报告及详细的地方地质调查进行了比对。结果显示,系统在提取诸如滑坡发生的时间、地点和触发因素等基本细节方面表现很出色,但在统计死亡、受伤和失踪人数上可靠性较低,因为这些数字在救援过程中常有变化。总体来看,新闻报道在时间与位置上与政府来源高度一致,证实它们是构建此类目录的可信基础。
对未来安全的意义
对非专业读者而言,核心信息是:计算机现在能够梳理多年新闻报道,生成清晰、详尽的危险坡面失稳地图。该中国滑坡目录并非每一起事件的完整记录,尤其是那些在媒体上几乎无痕的小型事件,而且伤亡数字应谨慎对待。尽管如此,它在时间和位置上的高精度使其成为科学家测试预警模型、规划者决策道路与城镇布局以及官员应对未来暴雨和地震的重要工具。
引用: Zhao, B., Zhang, L., Liu, Z. et al. A high-precision catalogue of landslide events in China based on news text mining with large language model. Sci Data 13, 722 (2026). https://doi.org/10.1038/s41597-026-07066-w
关键词: 滑坡目录, 中国灾害, 新闻文本挖掘, 大语言模型, 灾害风险数据