Clear Sky Science · sv
En högprecisionskatalog över jordskred i Kina baserad på nyhetstextgruvdrift med stor språkmodell
Varför denna jordskredskarta är viktig
Jordskred dödar tusentals människor och förstör bostäder, vägar och jordbruksmark varje år, ändå kan grundläggande fakta om när och var de inträffar vara förvånansvärt svåra att finna. Denna studie bygger en detaljerad katalog med mer än tusen jordskred över fastlandskina genom att lära ett datorsystem att läsa årsvis av nyhetsrapporter. Resultatet är en offentlig datamängd som kan hjälpa till att förbättra varningssystem, vägleda säkrare byggande och stödja smartare katastrofplanering.
Från spridda berättelser till en nationell bild
Hittills har Kina endast haft partiella register över jordskred. Officiella bulletiner räknade hur många händelser som inträffade varje år eller i varje provins men innehöll sällan exakta platser eller tider. Internationella kataloger fokuserade främst på de största eller dödligaste händelserna globalt och missade ofta lokala rapporter på kinesiska. Detta lämnade forskare utan en tydlig, finfördelad bild av jordskred i landet, vilket försvårade bedömningar av var sluttningar är farligast eller hur risken förändras över tid.
Låta datorer läsa nyheterna
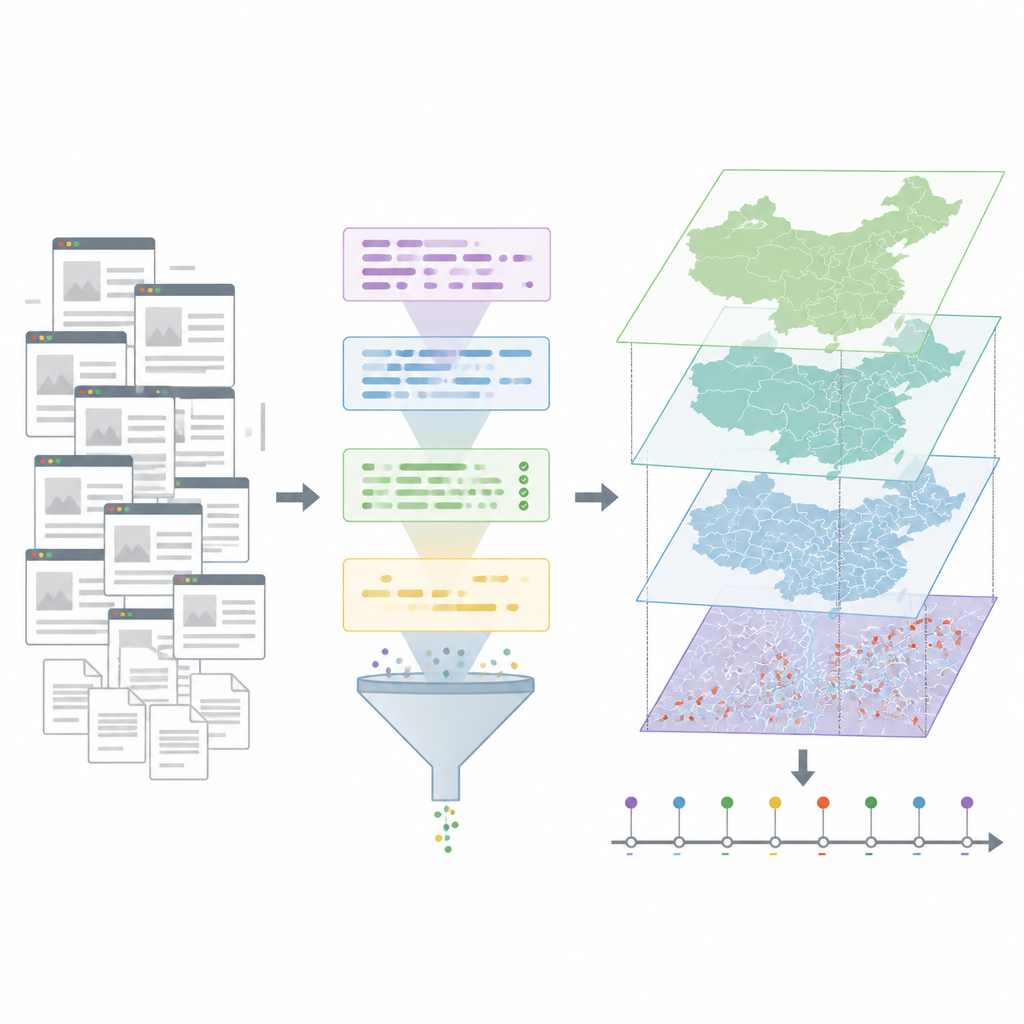
Författarna vände sig till China News Network, en stor nationell nyhetssajt som publicerar reportage dygnet runt från hela landet. De skrapade mer än 33 000 artiklar som nämnde ordet ”jordskred” från 2008 till 2024, och filtrerade sedan bort artiklar som använde termen som metafor, till exempel i samband med ett val eller ett börsras. Därefter använde de en stor språkmodell, en typ av avancerad artificiell intelligens tränad på enorma mängder text, för att plocka ut nyckelfakta från varje verklig katastrofrapport. För varje händelse försökte systemet identifiera när den inträffade, platsen, vad som utlöste den och hur många som dödades, skadades eller saknades.
Rensa, kontrollera och fästa händelser på kartan
Rå AI‑utdata är inte perfekt, så teamet lade till flera kontrollnivåer. De tog bort poster utan tydlig tids- eller platsinformation och släppte rapporter som endast namngav en vid region, som en provins, utan användbar detalj. De hanterade också det vanliga problemet med flera artiklar som rapporterade samma katastrof genom att jämföra hur nära händelserna var i tid och hur lika deras platsbeskrivningar var, för att sedan slå ihop sannolika dubbletter. Mänskliga experter granskade alla återstående poster och rättade fel. För att omvandla skrivna platsnamn till kartkoordinater använde författarna en onlinekarttjänst och egna regler för att välja bästa träff, följt av manuella kontroller för tvivelaktiga fall.
Vad den nya katalogen avslöjar
Den slutliga datamängden innehåller 1 582 jordskred med ovanligt preciserad information. Ungefär hälften av händelserna är daterade till exakt timme eller till och med minut, och mer än 80 procent är lokaliserade i byskala eller till en specifik plats såsom ett vägskär eller en sluttning. De flesta registrerade jordskred utlösts av kraftigt regn, särskilt i södra Kina, medan jordbävningsrelaterade händelser samlas nära den östra kanten av Tibetanska högplatån. Jämfört med två vida använda globala jordskreddatabaser innehåller denna nya katalog ungefär två och en halv gånger fler händelser i Kina under samma år och lokaliserar dem mer precist i både tid och rum.
Hur tillförlitlig är AI som läser nyheterna
För att testa noggrannheten jämförde teamet sina AI‑extraherade poster med officiella rapporter om välkända katastrofer och med detaljerade lokala geologiska undersökningar. De fann att systemet var mycket bra på att plocka ut grundläggande detaljer som när och var ett jordskred inträffade och vad som utlöst det, men mindre tillförlitligt när det gällde att räkna döda, skadade och saknade personer, vilket ofta förändras medan insatser pågår. Sammantaget stämde nyhetsrapporternas information väl överens med myndighetskällor vad gäller tidpunkt och plats, vilket bekräftar att de är en trovärdig grund för att bygga en sådan katalog.
Vad detta betyder för framtida säkerhet
För icke‑specialister är huvudbudskapet att datorer nu kan sålla igenom års nyhetsbevakning för att skapa tydliga, detaljerade kartor över var farliga sluttningar har gått sönder. Denna kinesiska jordskredskatalog är inte en fullständig förteckning över varje händelse, särskilt inte små som lämnade litet spår i medierna, och siffror över offer bör hanteras med försiktighet. Ändå gör dess exakta tidpunkter och platser den till ett kraftfullt verktyg för forskare som testar varningsmodeller, för planerare som bestämmer var vägar och samhällen bör byggas, och för beslutsfattare som förbereder sig för framtida stormar och jordbävningar.
Citering: Zhao, B., Zhang, L., Liu, Z. et al. A high-precision catalogue of landslide events in China based on news text mining with large language model. Sci Data 13, 722 (2026). https://doi.org/10.1038/s41597-026-07066-w
Nyckelord: jordskredskatalog, Kina faror, nyhetstextgruvdrift, stor språkmodell, katastrofriskdata