Clear Sky Science · zh
常规血液检查与机器学习识别高度近视并发症
为什么一项简单的血液检查可能有助于挽救视力
许多人知道高度近视意味着需要更厚的眼镜,但较少有人意识到它也可能在不知不觉中损害眼球本身,导致白内障、青光眼、视网膜脱离等问题,最终可能造成永久性视力丧失。检测这些并发症所需的设备——专用眼底相机和扫描仪——价格昂贵且分布不均,尤其在大型医院以外地区更是稀缺。本研究探索了一个意想不到的替代方法:利用常规血液检查的结果,结合机器学习,来筛查高度近视人群中可能在症状出现很久之前就已出现严重眼部并发症的人。
从常见眼病到无声的威胁
高度近视,通常指非常强的近视,正变得越来越普遍。除了远视模糊外,近视会使眼球拉伸变薄,从而增加白内障、青光眼、黄斑损伤和视网膜脱离的风险。如果能早期发现,部分病变可以被延缓或治疗,但许多高度近视者并未定期接受专科眼科检查。诸如光学相干断层扫描等高级成像工具能提供眼部的详细图像,然而这些设备成本高昂、需要专业人员操作,并在许多地区难以获得。因此,许多危险的眼部变化在视力已严重受损前并未被发现。
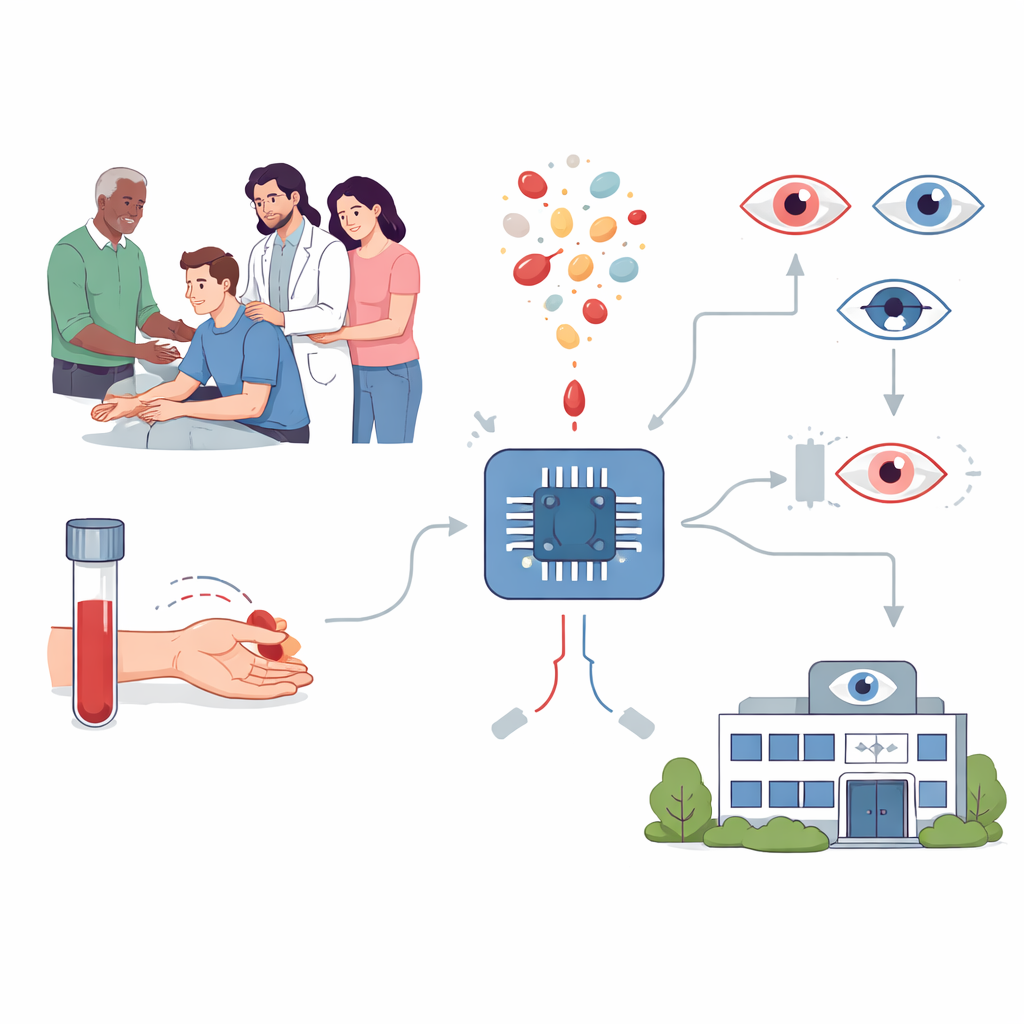
在日常血检中寻找线索
研究人员问:常规体检中已收集的信息是否有助于识别风险。常规血液检查价格低廉、可及性高,日常用于监测总体健康。早期研究提示某些反映炎症、代谢和凝血状态的血液指标与眼病有关。本研究团队收集了来自中国五家医院逾1万名高度近视患者的数据。有些人未出现其他问题;另一些则发生了五类主要并发症之一:白内障、黄斑退化、视网膜下异常新生血管、青光眼或视网膜脱离。对每位患者,61项常见化验值——包括各类白细胞、血脂指标和凝血参数——被输入多种机器学习算法,以判断血液模式能否将有并发症者与无并发症者区分开来。
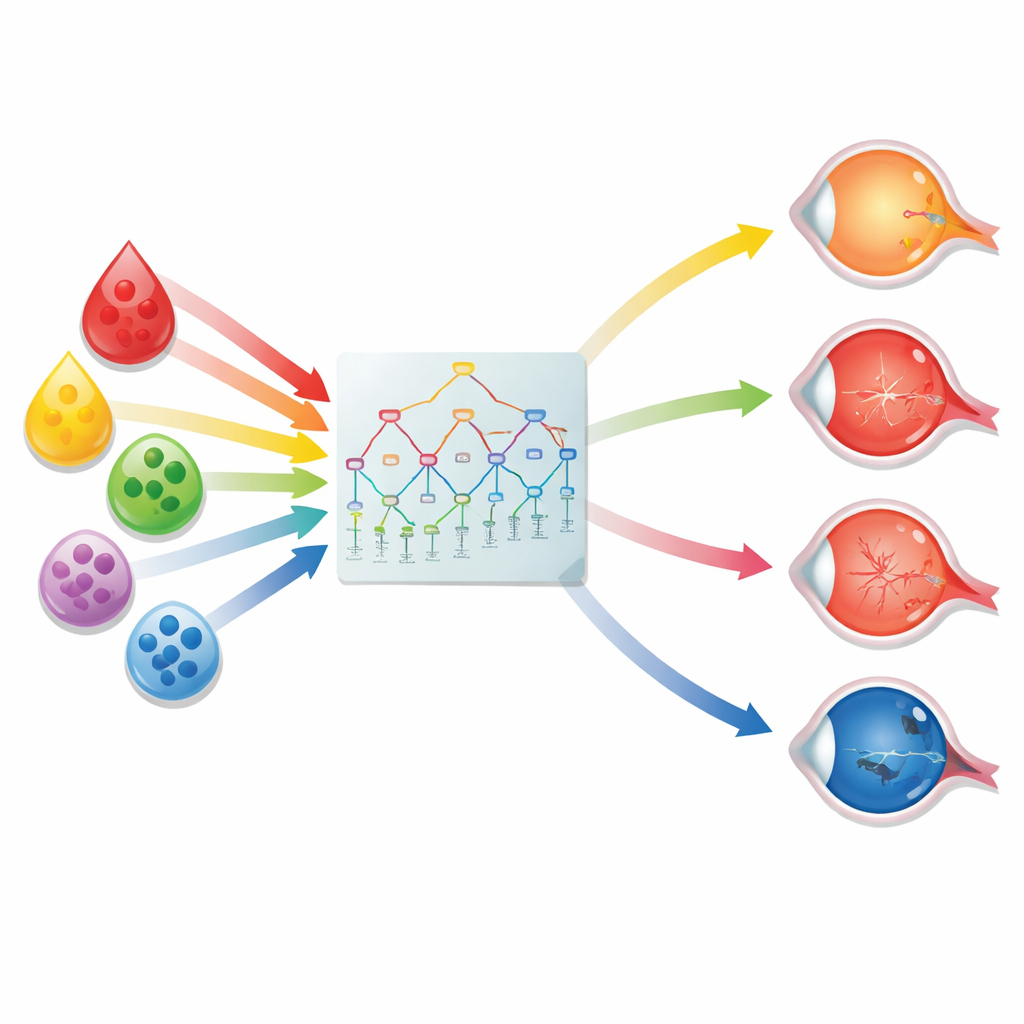
用于眼部风险的九个数字指纹
在众多测试的算法中,一类称为随机森林的模型表现尤为出色。值得注意的是,模型并不需要全部61项检测值。经过谨慎的特征筛选,仅有九项常规测量指标——主要是某些免疫细胞(嗜酸细胞和嗜碱细胞及其占比)、血小板、尿酸,以及甘油三酯和载脂蛋白B等血脂——几乎保留了全部的预测能力。这些标志物与已知的炎症、血脂和凝血如何促成高度近视相关眼损伤的机制相一致。仅用这九个数值,模型在原始医院队列中就能非常准确地区分无并发症与有并发症的高度近视患者,并且在另两家医院的外部验证中性能依然稳健。
从计算模型到现实世界筛查
为评估该方法在日常临床中的可行性,研究人员将九项指标的模型嵌入了一个简单的网络应用,临床医生可在抽血时使用。在一项包括4500多名高度近视者的前瞻性医院研究中,该工具将部分人标为高风险,另一部分标为低风险。随后这些患者接受详细眼部检查时,被标为高风险的人更可能确实存在并发症,而模型漏诊的病例相对较少。研究团队随后将该模型推广到社区,从超过30万名参加常规体检的成年人中识别出近1900名高度近视者并应用该工具。在被模型判定为高风险且同意进一步眼检的人群中,约有三分之二至四分之三被确诊为严重并发症——显著高于无差别转诊时的预期命中率。
这对患者和卫生系统意味着什么
该研究表明,将标准血液常规与经过精心训练的算法结合,可以作为高度近视人群危险性眼病的早期预警系统。这并不取代专科的眼部成像或检查,而是帮助决定谁最需要优先获得稀缺的眼科资源。在眼科设备和专科医生有限的环境中,这种基于血液的分诊工具可使人群筛查更可行且更具成本效益,既能更早发现许多病例,又能避免不必要的转诊。如果在更多国家得到验证并在降低漏诊与误报方面进一步优化,这种方法有望成为一种可扩展的、利用已有常规检测来保护视力的策略。
引用: Li, S., Ren, J., Wang, F. et al. Routine blood tests and machine learning identify complications in high myopia. Nat Commun 17, 3930 (2026). https://doi.org/10.1038/s41467-026-70891-5
关键词: 高度近视, 视力筛查, 机器学习, 血液生物标志物, 眼部并发症