Clear Sky Science · zh
通过大肠杆菌表达的非天然蛋白进行数据存储与检索
将数据转为蛋白为何重要
我们的手机、传感器和在线活动正在产生海量信息,而如今的硬盘和磁带可能无法永远跟上速度。该研究探索了一个截然不同的想法:将数字数据存储到实验室合成的蛋白质中,这些蛋白可以由常见细菌生产。作者表明,这些定制蛋白能承载信息、在苛刻环境下比 DNA 更加耐受,甚至支持诸如选择性访问和秘密“锁定”信息等高级功能。
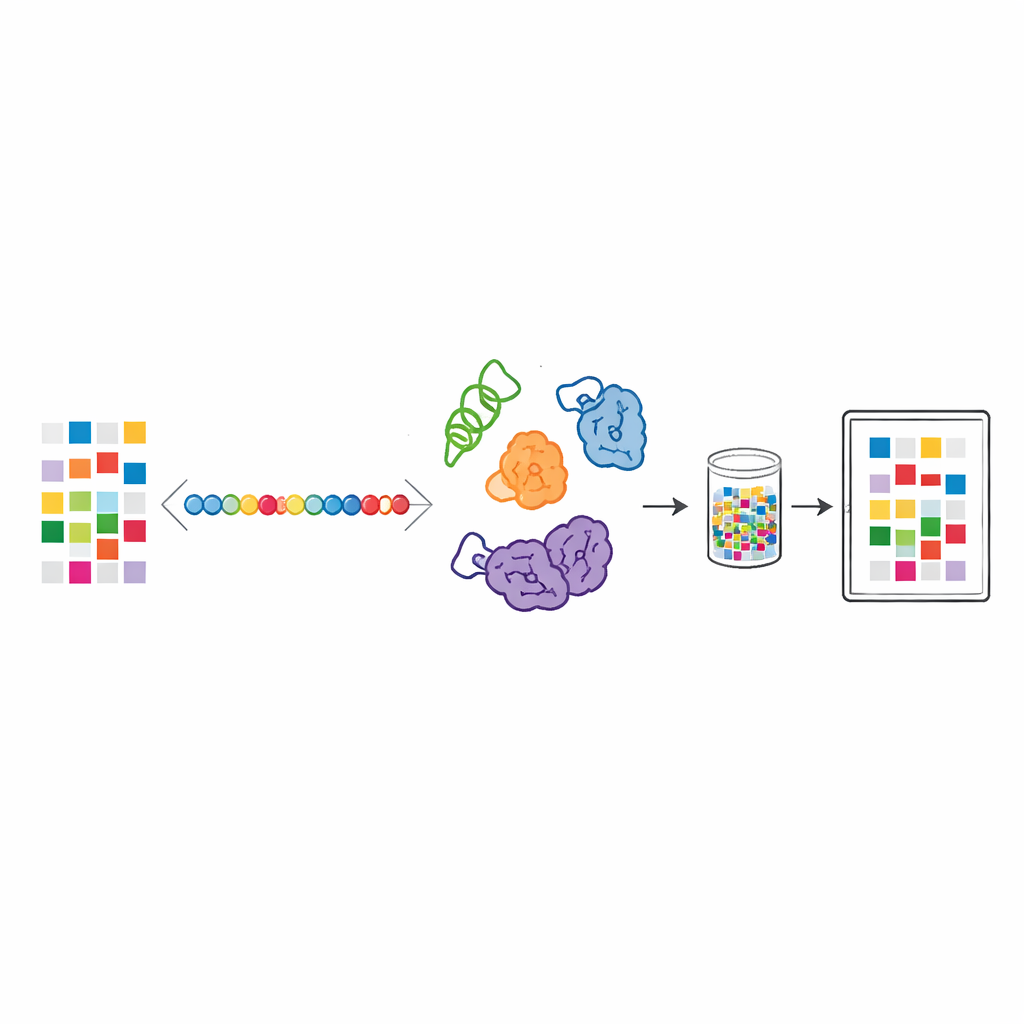
从二进制到构建模块的链条
任何数字文件归根结底都是一长串的0和1。研究人员首先将这些比特转换为氨基酸序列——氨基酸是构成蛋白质的小型构件。每种选定的氨基酸代表一个三比特的短模式,因此一条氨基酸链就成为编码信息。这些人工序列随后被插入更长的蛋白设计中,并在广泛用于生物技术的大肠杆菌内表达。一旦制备完成,蛋白被干燥成粉末,成为储存信息的物理介质。
早期设计为何受限与类胶原的启示
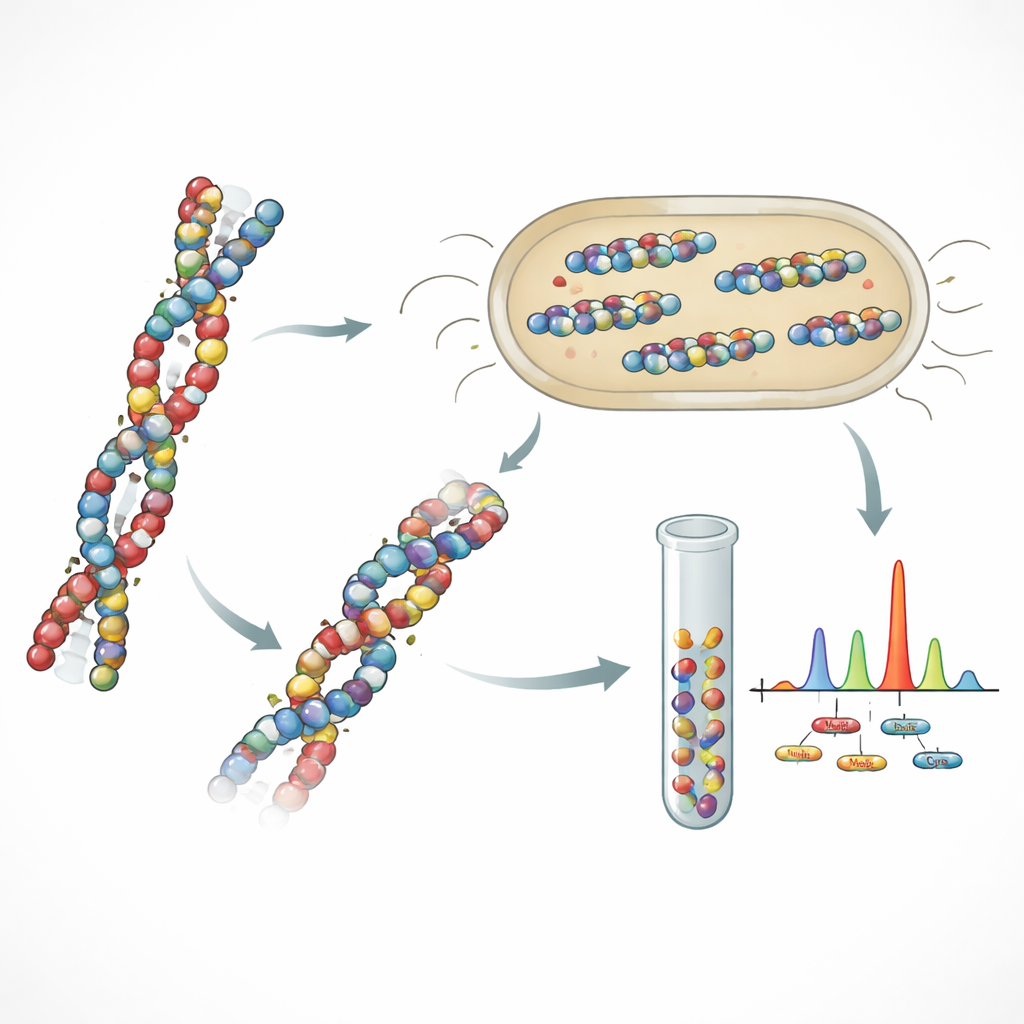
团队最初的做法只是将许多承载数据的片段缝合成一条长蛋白。尽管理论上很优雅,但这些非天然链在大肠杆菌内表现不佳:产量低且易被细胞自身的酶切割。为了解决这一问题,研究人员从胶原蛋白那里得到灵感——胶原是一种在骨骼和化石残骸中发现的坚韧结构蛋白,可保存数百万年。他们构建了一个模拟胶原重复模式的新模板,并将其与已知在细菌中能良好表达的类胶原结构域融合。这种类胶原风格的框架仍然留有编码数据的空间,但赋予整体蛋白更自然的形状,使细胞更能容纳并抵抗不必要的降解。
写入、读取与规模化蛋白记忆
借助受胶原启发的设计,科学家成功地在几种不同蛋白中存储了英文文本和多语种名言。他们展示了大肠杆菌可以以有用的产率生产这些携带数据的蛋白,并且常规生化工具可以在不需极端操作的情况下对其进行纯化。为读取存储信息,蛋白被酶切成较短片段,然后由灵敏的质谱仪称量这些片段。定制软件重建原始氨基酸序列并将其转换回比特。即便约有十分之一的片段缺失或错误,内置的纠错码仍能准确恢复完整信息,包括在多种不同蛋白混合的情况下。
稳定性、选择性访问与隐藏信息
分子存储的一个关键承诺是长寿命。作者将一种类胶原蛋白与携带相同信息的 DNA 序列在高温和强酸性条件下进行比较。该蛋白在70摄氏度高温和极低 pH 条件下经日处理后仍保留大部分质量且可读,而 DNA 则迅速降解。他们接着展示,附加在蛋白末端的短标签可像条形码一样工作:使用匹配抗体,他们能够从复杂混合物中仅拉出与某个选定名言相关的蛋白并读取该部分数据。通过将“诱饵”蛋白配以普通标签与仅用特殊标签标记的“秘密”蛋白相结合,他们构建了一种简单的分子密码学形式,只有知道正确标签的人才能可靠地检索隐藏信息。
这对数据未来意味着什么
这项工作首次完整演示了完全新型的非天然蛋白可以作为从写入、存储到准确读取的稳健数字介质。尽管当前的容量和速度离日常使用尚有差距,该方法在潜在密度和稳定性方面显示出很高的潜力,尤其适合长期存档。随着蛋白设计、生产与测序工具的持续进步,以蛋白编码的数据可能成为 DNA 与传统硬件的补充,支持地球上甚至太空中的耐久档案,并在严格安全措施下有望实现将信息直接存储于生物系统中。
引用: Zhou, Y., Ng, C.C.A., Liu, C. et al. Data storage and retrieval with unnatural proteins expressed via E. coli. Nat Commun 17, 3320 (2026). https://doi.org/10.1038/s41467-026-70061-7
关键词: 蛋白质数据存储, 分子记忆, 大肠杆菌表达, 类胶原蛋白, 数据加密