Clear Sky Science · fr
Stockage et récupération de données avec des protéines non naturelles exprimées via E. coli
Pourquoi transformer des données en protéines compte
Nos téléphones, capteurs et vies en ligne inondent le monde d’informations, et les disques durs et bandes magnétiques d’aujourd’hui pourraient ne pas suffire indéfiniment. Cette étude explore une idée radicalement différente : stocker des données numériques à l’intérieur de protéines synthétiques produites par des bactéries courantes. Les auteurs montrent que ces protéines sur mesure peuvent contenir des messages, résister à des conditions difficiles mieux que l’ADN, et même permettre des astuces avancées comme l’accès sélectif et des informations secrètes « verrouillées ».
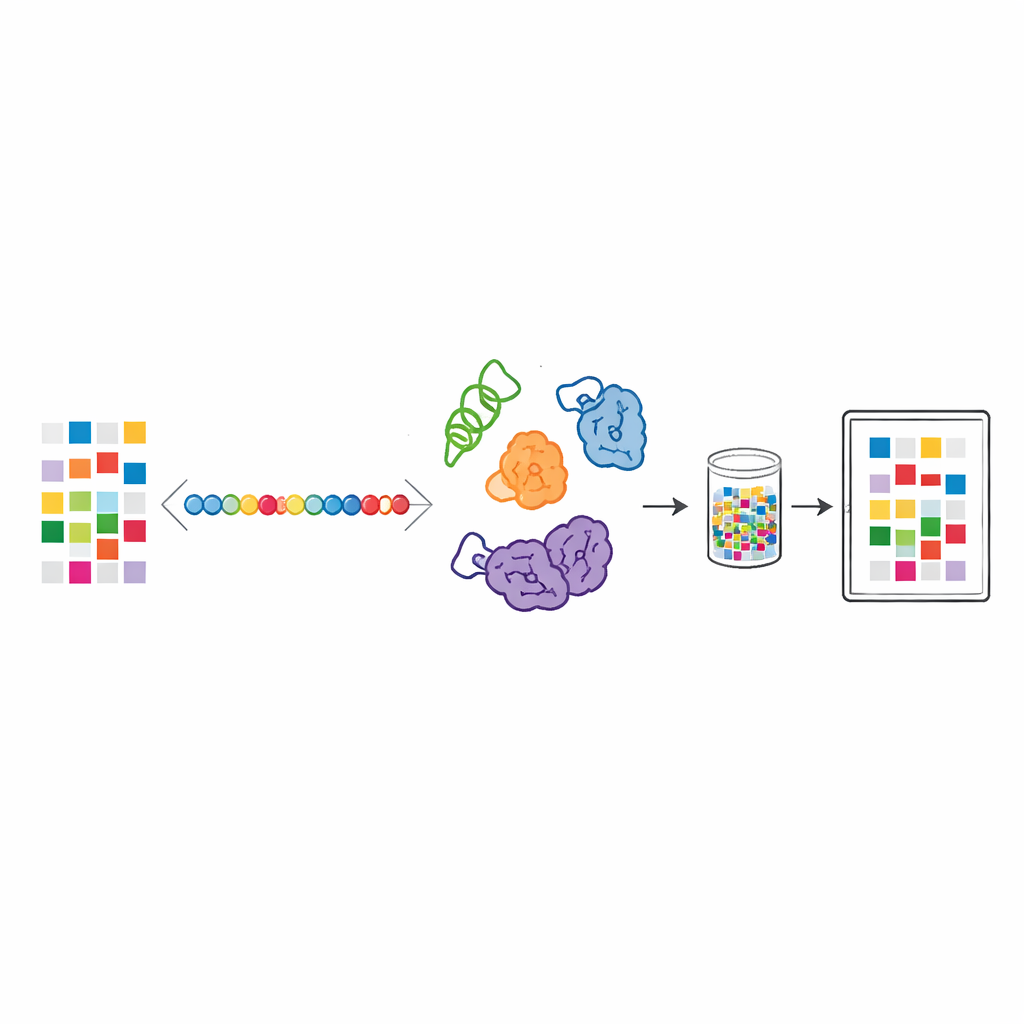
Des uns et des zéros aux chaînes de briques élémentaires
Tout fichier numérique est finalement une longue suite de uns et de zéros. Les chercheurs convertissent d’abord ces bits en une séquence d’acides aminés, les petits éléments constitutifs des protéines. Chaque acide aminé choisi représente un motif bref de trois bits, de sorte qu’une chaîne d’acides aminés devient un message codé. Ces séquences artificielles sont ensuite insérées dans des conceptions protéiques plus longues et produites à l’intérieur d’Escherichia coli, une bactérie « travailleuse » largement utilisée en biotechnologie. Une fois fabriquées, les protéines sont séchées en poudre, qui devient le support physique stockant l’information.
Pourquoi les premiers modèles ont peiné et comment le collagène a montré la voie
La première approche de l’équipe consistait simplement à assembler de nombreux segments porteurs de données en une seule protéine longue. Bien qu’élégantes sur le papier, ces chaînes non naturelles ne se comportaient pas bien dans E. coli : leur production était faible et elles étaient facilement coupées par les propres enzymes de la cellule. Pour résoudre ce problème, les chercheurs se sont inspirés du collagène, une protéine structurelle robuste présente dans les os et les restes fossiles qui peut persister pendant des millions d’années. Ils ont construit un nouveau modèle qui imite le motif répétitif du collagène et l’ont fusionné avec un domaine de type collagène connu pour s’exprimer efficacement dans les bactéries. Cette structure de style collagène laisse encore de l’espace pour encoder des données, mais confère à la protéine une forme plus naturelle que la cellule tolère et qui résiste à la dégradation indésirable.
Écrire, lire et passer à l’échelle la mémoire protéique
Avec le design inspiré du collagène, les scientifiques ont stocké avec succès des textes en anglais et des citations célèbres en plusieurs langues dans plusieurs protéines différentes. Ils ont montré que E. coli peut produire ces protéines porteuses de données à des rendements utiles, et que des outils biochimiques standards peuvent les purifier sans efforts extrêmes. Pour lire l’information stockée, les protéines sont découpées en fragments plus courts par une enzyme, puis analysées par un spectromètre de masse sensible qui pèse les fragments. Un logiciel personnalisé reconstruit les séquences d’acides aminés originales et les convertit en bits. Même lorsque jusqu’à environ un fragment sur dix est manquant ou incorrect, des codes de correction d’erreurs intégrés permettent de récupérer fidèlement les messages complets, y compris lorsque de nombreuses protéines différentes sont mélangées.
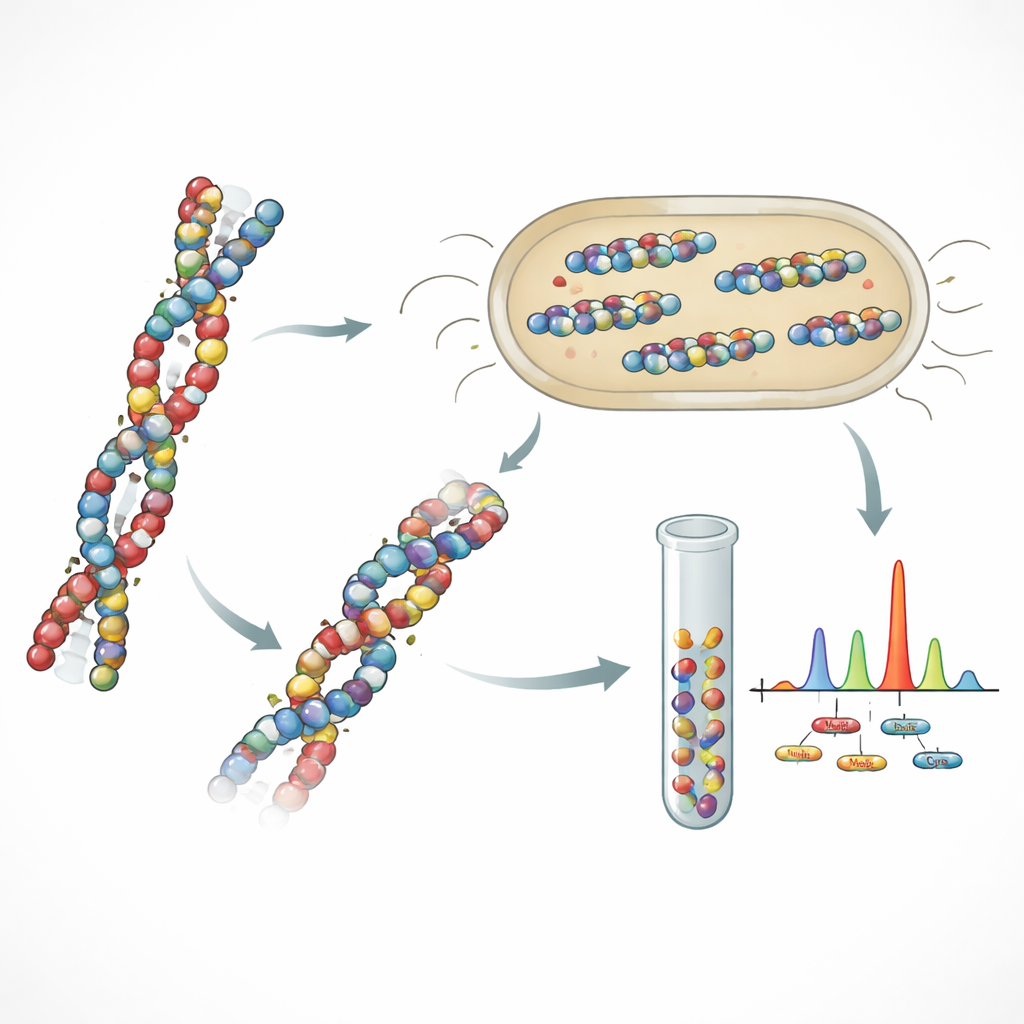
Stabilité, accès sélectif et messages cachés
Une promesse clé du stockage moléculaire est la longue durée de vie. Les auteurs ont comparé l’un de leurs protéines de type collagène avec une séquence d’ADN portant le même message dans des conditions chaudes et fortement acides. La protéine a conservé la majeure partie de sa masse et est restée lisible après plusieurs jours à 70 degrés Celsius et à pH très bas, tandis que l’ADN s’est rapidement dégradé. Ils ont ensuite montré que de courts tags ajoutés aux extrémités des protéines peuvent agir comme des codes-barres : en utilisant des anticorps correspondants, ils ont pu extraire uniquement les protéines liées à une citation choisie à partir d’un mélange complexe et ne lire que cette partie des données. En combinant des protéines « leurres » avec des tags ordinaires et des protéines « secrètes » marquées uniquement par des tags spéciaux, ils ont construit une forme simple de cryptographie moléculaire, où seul quelqu’un qui connaît le tag correct peut récupérer de manière fiable le message caché.
Ce que cela signifie pour l’avenir des données
Ce travail fournit la première démonstration complète que des protéines entièrement nouvelles et non naturelles peuvent agir comme un support robuste pour des données numériques, depuis l’écriture et le stockage jusqu’à une lecture précise. Bien que les capacités et vitesses actuelles soient loin d’un usage quotidien, l’approche offre une densité potentielle très élevée et une stabilité impressionnante, en particulier pour l’archivage à long terme. À mesure que les outils de conception, de production et de séquençage des protéines continuent de progresser, les données encodées dans des protéines pourraient compléter l’ADN et le matériel traditionnel, permettant des archives durables sur Terre ou même dans l’espace, et potentiellement autorisant le stockage d’informations directement au sein de systèmes vivants sous des garde-fous stricts.
Citation: Zhou, Y., Ng, C.C.A., Liu, C. et al. Data storage and retrieval with unnatural proteins expressed via E. coli. Nat Commun 17, 3320 (2026). https://doi.org/10.1038/s41467-026-70061-7
Mots-clés: stockage de données par protéines, mémoire moléculaire, expression dans E. coli, protéines de type collagène, cryptographie des données