Clear Sky Science · zh
基于可调高斯样记忆单元的 Kolmogorov-Arnold 网络的计算内存架构
这个新芯片思想为何重要
当今的人工智能系统—from 博弈程序到聊天机器人—依赖庞大的简单算术单元网络,消耗大量能量并依赖性能强劲的图形处理芯片。本文提出了一种不同的 AI 硬件思路,将存储与计算融合在相同的微小单元中,并针对一种新型神经网络——Kolmogorov–Arnold 网络进行优化。其结果是一个芯片概念,旨在更像大脑那样灵活且高效地学习,同时比当前主流硬件使用更少的能量。
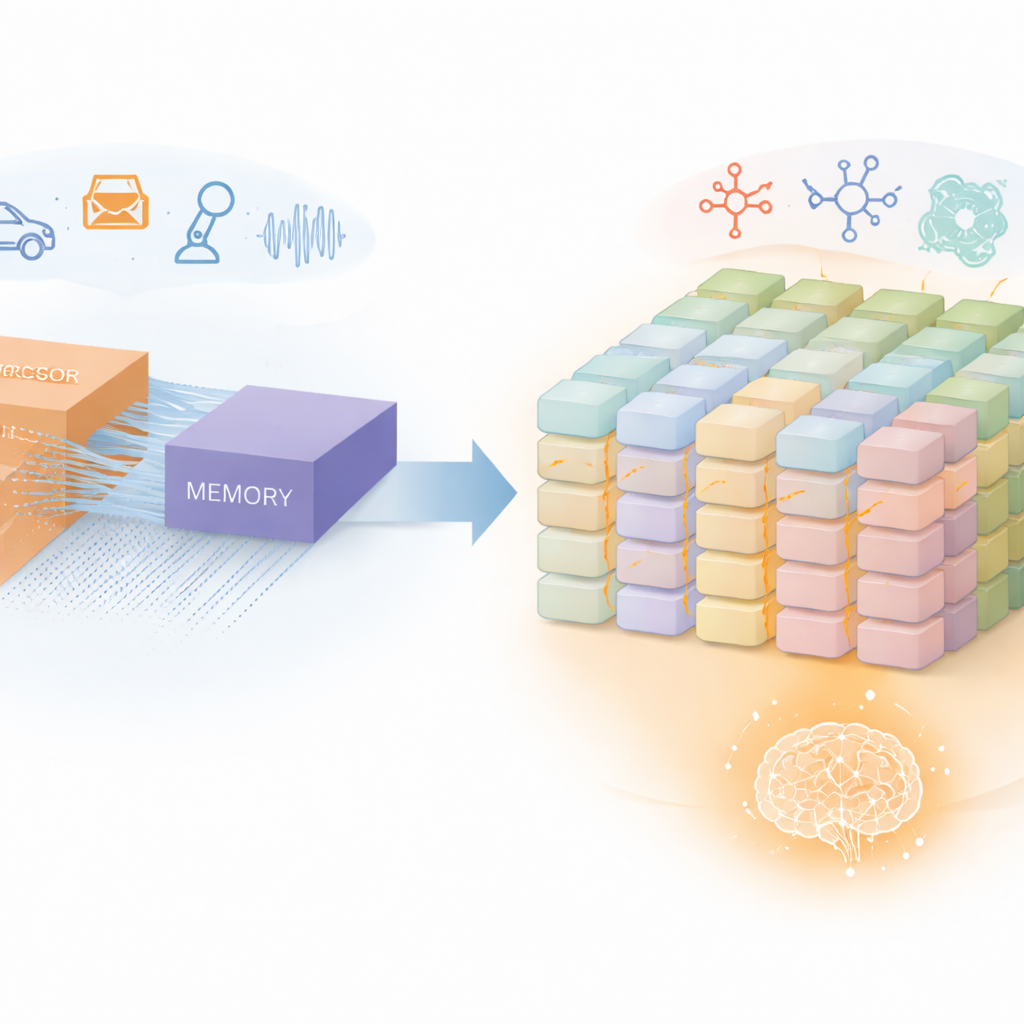
神经网络学习的新途径
目前广泛使用的大多数神经网络,如多层感知机,依赖固定的数学框架,学习主要通过调整人工神经元之间连接的强度来实现。Kolmogorov–Arnold 网络采用不同的方法:它们不仅调整连接强度,还学习将输入变换为输出的函数的详细形状。这些学习到的曲线像可定制的构件,使网络能够适应复杂的数据模式,并且重要的是在学习新任务时保留旧任务的记忆。然而,在普通芯片上实现这些丰富的函数电路开销大、能耗高,因为它需要大量重复且不规则的计算,标准处理器和图形芯片难以高效处理。
一种新型记忆单元
为弥合算法与硬件之间的差距,研究团队设计了一个基本的电子构件,称为高斯样记忆单元。每个单元将两种纳米级组件串联:一种能以平滑的钟形曲线表现出响应的特殊晶体管,以及一种可通过电脉冲永久调节电阻的忆阻器。通过调节忆阻器,团队可以移动和缩放晶体管的钟形响应,有效地在硬件中直接编程出高斯样曲线的高度与宽度。测量显示,这些单元可以重复重编程、长时间保留状态,并在多次循环和不同器件之间表现出一致性,这些特性对构建可靠的大规模阵列至关重要。
将单元组成计算内存“大脑”
下一步是将成千上万这样的记忆单元排列成网格状的交叉阵列。在这种布局中,行与列的导线在每个单元处相交,沿列施加的信号控制单元行为,而沿行收集的电流根据基本电学定律自然相加。这意味着芯片可以直接在存储信息的位置执行 Kolmogorov–Arnold 网络的核心运算——将多个高斯样函数相加以形成灵活的激活曲线——而无需在独立的处理器与存储之间频繁传输数据。附加电路允许表示与求和正负贡献,可选的残差通道在不取代核心计算内存运算的前提下增强深度网络的稳定性。
对该架构的测试
作者利用与器件测量行为相结合的详细仿真表明,由这些记忆单元阵列构建的网络能够应对多种任务。他们成功地拟合了复杂的一维函数而不遗忘先前任务,识别手写数字和服装类别,求解偏微分方程,并预测混沌时间序列。在这些情形中,高斯单元网络保留了 Kolmogorov–Arnold 网络的关键优势:用相对较少的参数实现出色性能,并在训练新任务时显著避免灾难性遗忘。与使用类似忆阻硬件实现的传统神经网络相比,该新架构常常在更小的中间层下实现更好的准确率和泛化能力。
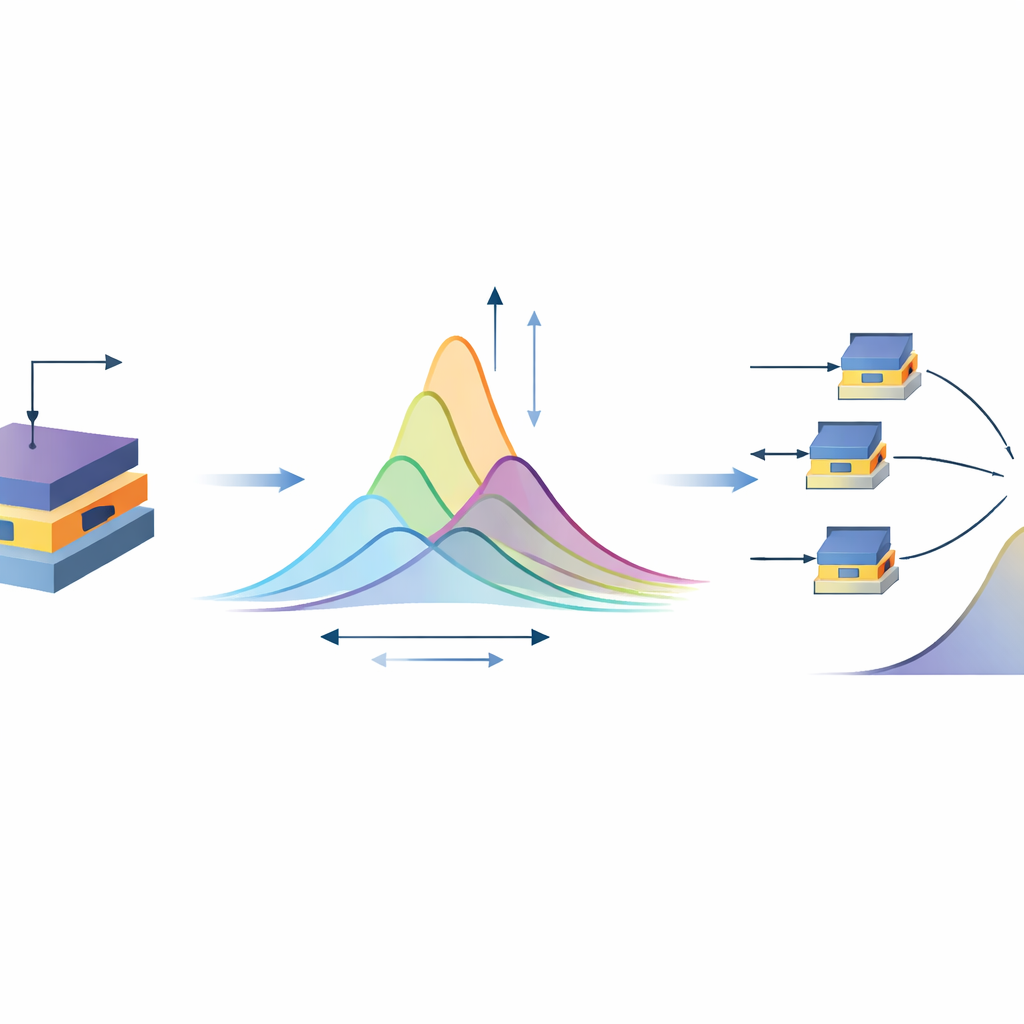
节能与实际前景
由于计算发生在存储学习参数的相同单元内,所提出的架构在很大程度上规避了困扰当今 AI 硬件的昂贵存储与处理器间数据传输。作者估算,他们的高斯样记忆单元系统在执行 Kolmogorov–Arnold 网络核心运算时,能效相比运行等效算法的现代图形芯片约高两个数量级。简而言之,该工作勾勒出如何构建每个微小器件既能记忆又能计算可变的钟形响应,并让许多此类器件并行协作。这为未来的类脑硬件指明了方向:能够连续学习、抗遗忘,并以远低于现有平台的能耗运行强大 AI 模型。
引用: Wen, Z., Zhang, Q., Chen, J. et al. Computing-in-memory architecture for Kolmogorov-Arnold networks based on tunable Gaussian-like memory cells. Nat Commun 17, 3496 (2026). https://doi.org/10.1038/s41467-026-69592-w
关键词: 类脑计算, 计算内存, Kolmogorov-Arnold 网络, 忆阻器器件, 节能人工智能硬件