Clear Sky Science · zh
通过整合离散自然语言处理模型提升退伍军人事务部患者的个性化自杀风险预测
这项研究为何重要
退伍军人自杀是一个紧迫的公共卫生危机,但我们现有的最佳预测工具仍然漏掉许多有风险的人,尤其是那些没有明显危险迹象的人。本研究探讨计算机是否可以从退伍军人在病历中书写的文字中学到更多信息,以更好地识别可能需要帮助的人,特别关注目前被归类为仅为低或中等风险的个体。
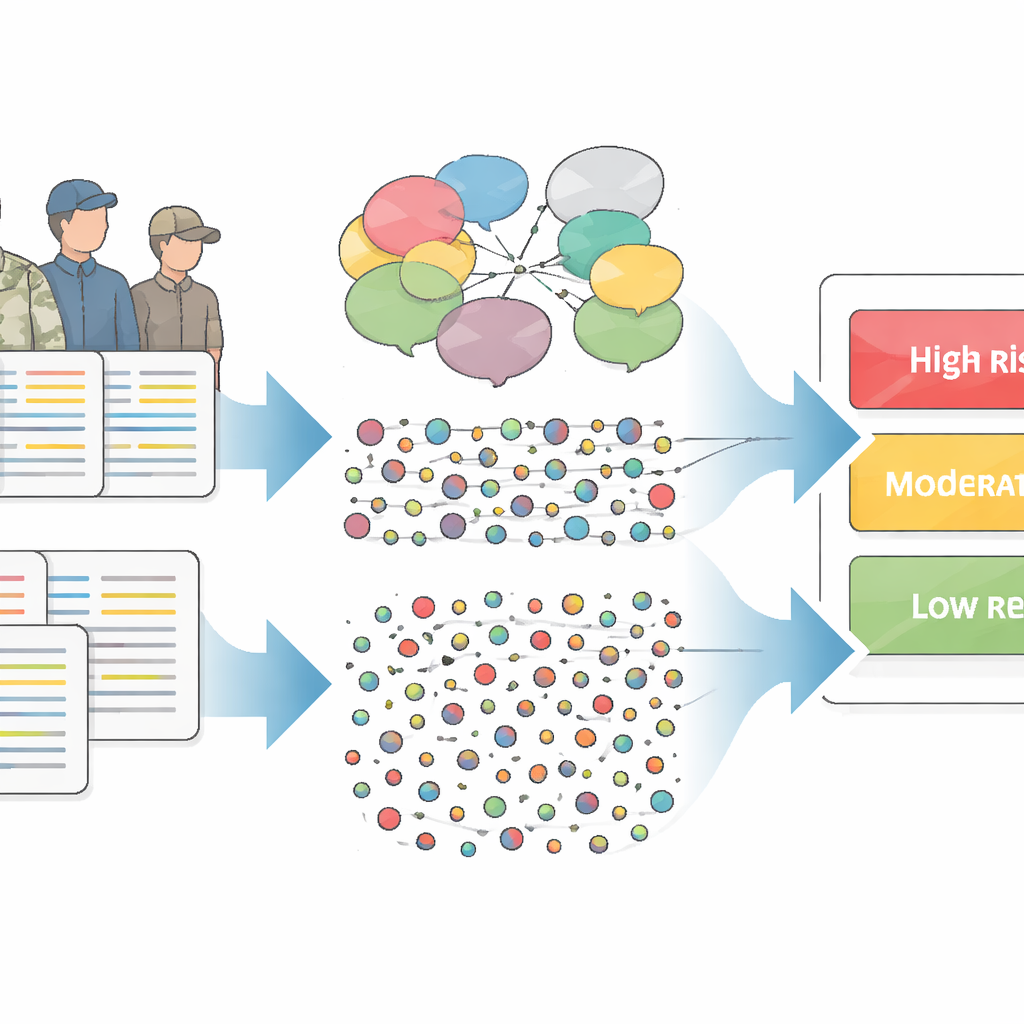
超越常规数据
美国退伍军人事务部(VA)已经使用名为 REACH-VET 的系统来标记自杀风险最高的退伍军人。REACH-VET 依赖于“结构化”信息,这类信息可以整齐地放入表格,例如诊断、既往住院记录或某人是否曾报告过自杀想法。尽管这种方法很强大,但对经常使用 VA 服务并产生大量此类数据的患者最为有效。就诊较少或其困境未被复选框和代码充分捕捉的退伍军人,可能会被忽视,尽管他们也处于危险之中。
将医生笔记转化为可用信号
临床人员对患者的许多了解存在于自由文本笔记中,而不是整洁的字段里。研究人员利用了这些书面笔记——对于死于自杀的退伍军人,是在其死亡前 5 到 30 天内;对于未死亡的匹配退伍军人,则在相同时间窗口内——以查看语言模式是否能提高风险预测的准确性。他们比较了两种处理文本的方法。一种是“语义”方法,基于专家构建的词典来捕捉诸如家庭关系、愉悦或消极情绪等概念。另一种是“计数”方法,仅统计特定单词或短语出现的频率,让数据在没有先验假设的情况下揭示模式。
结合两种语言视角
利用这些要素,团队构建了机器学习模型,试图区分死于自杀的退伍军人和未死的相似退伍军人,分别在按 REACH-VET 预测风险分为高、中、低的三个群体内进行。他们建立了仅使用语义特征、仅使用词频计数或两者混合的模型。为了公平地融合两种文本方法,他们对模型进行了调整,使得数量较少的语义特征在大量计数字段旁仍有机会影响决策。模型性能使用一种标准指标来衡量,本质上是检查模型在多大程度上会给死于自杀者比匹配的未死者更高的风险分数。
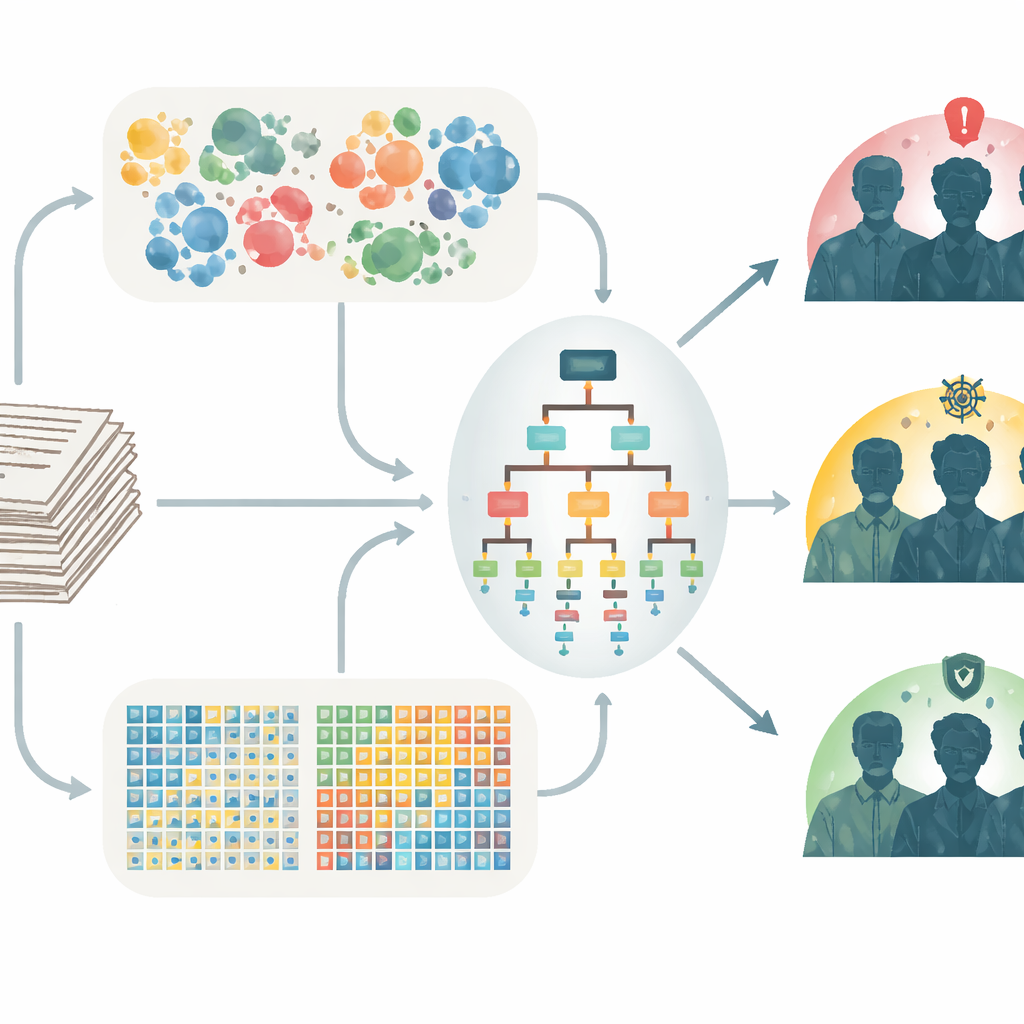
模型的发现
在所有三个风险组中,仅基于词频计数的模型总体上优于仅使用语义词典的模型。然而,对于被 REACH-VET 评为中等和低风险的退伍军人,最成功的模型是倾向于词频计数但仍从语义测量中汲取部分信息的混合模型。这些组合模型相较于单独使用 REACH-VET 实现了中等程度的改进,增益在最初被标记为低风险的退伍军人中最大——这些人往往就诊较少、结构化数据也较少。不同组别中重要的语言模式有所差异:高风险笔记强调急性精神健康问题,中等风险笔记突出护理流程,低风险笔记则更多涉及一般医疗与康复主题,以及社会联系或其缺失的迹象。
对护理和预防的启示
这些发现表明,电子健康记录中的非结构化文本包含可提高自杀风险估计的有价值线索,尤其适用于那些尚未处于最高风险类别的人。通过将简单的词频模式与更有理论驱动的语义信号相结合,并针对不同风险层级定制模型,医疗系统或许能更早识别脆弱的退伍军人,并设计与其风险程度和类型相匹配的干预措施。对于低风险患者,这可能意味着较轻的支持方式,例如自动化随访、推荐同行或健康计划,或在常规就诊中讨论社会和情绪挑战。
对退伍军人和临床医生的意义
简而言之,研究表明,关注临床医生如何描述患者——与传统医疗数据结合使用——可以使自杀预测工具对那些可能被忽略的退伍军人更为敏感。尽管改进幅度有限且该方法仍需在实时临床环境中进行验证,但这是朝着更个性化、以数据为依据的自杀预防迈出的具体一步,旨在服务于不仅处于明显危机中的人,也包括那些风险更隐匿、更复杂且更容易被忽视的人。
引用: Dimambro, M., Levy, J., Gui, J. et al. Enhancing personalized suicide risk prediction for VA patients by integrating discrete natural language processing models. Transl Psychiatry 16, 196 (2026). https://doi.org/10.1038/s41398-026-03940-8
关键词: 退伍军人自杀风险, 电子健康记录, 自然语言处理, 风险预测模型, 心理健康护理