Clear Sky Science · en
Enhancing personalized suicide risk prediction for VA patients by integrating discrete natural language processing models
Why this research matters
Suicide among military veterans is a pressing public health crisis, yet our best prediction tools still miss many at-risk people, especially those who do not appear to be in obvious danger. This study explores whether computers can learn more from the words written in veterans’ medical charts to better spot who may need help, with a special focus on those currently classified as only low or moderate risk.
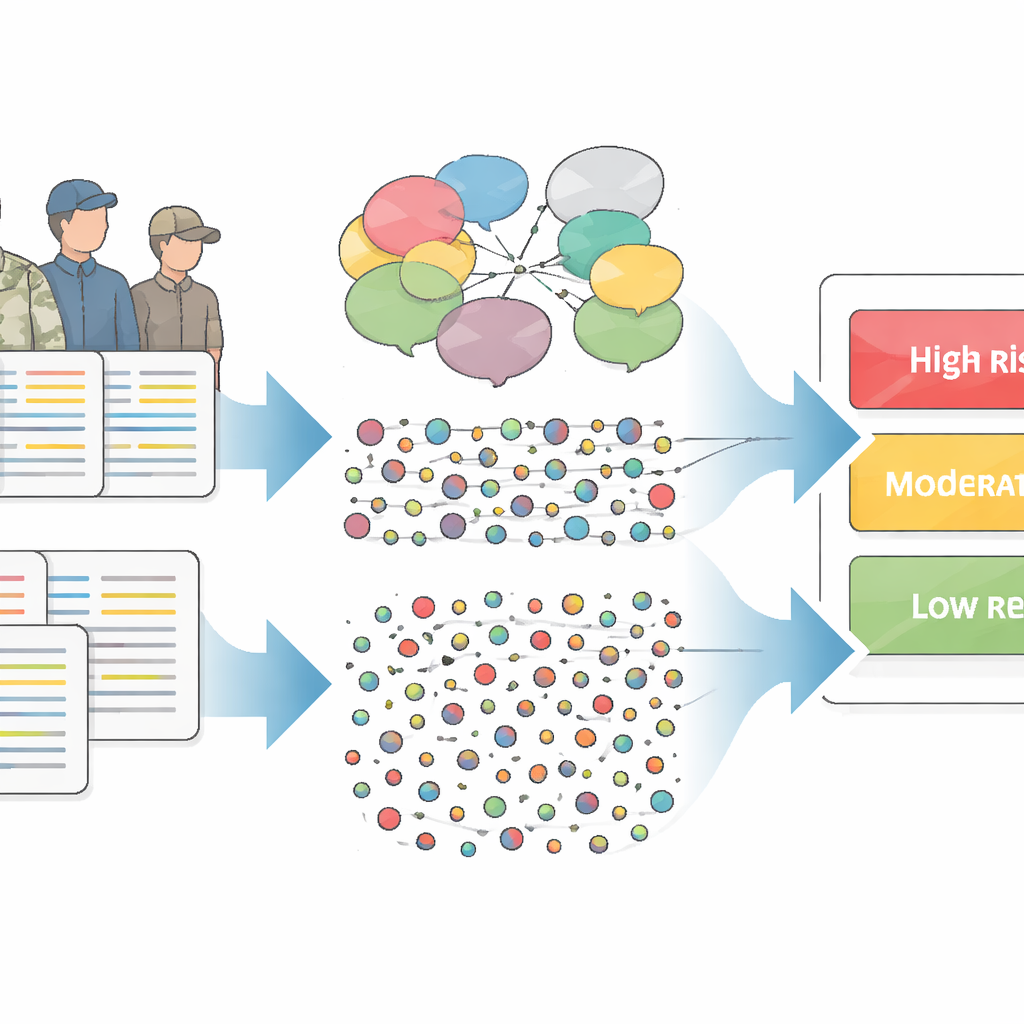
Looking beyond the usual numbers
The U.S. Department of Veterans Affairs (VA) already uses a system called REACH-VET to flag veterans at highest risk of suicide. REACH-VET relies on “structured” information that fits neatly into tables, such as diagnoses, past hospital stays, or whether someone has ever reported suicidal thoughts. While powerful, this approach works best for patients who use VA services often and generate a lot of such data. Veterans who have fewer visits, or whose struggles are not fully captured in checkboxes and codes, can be overlooked despite being in danger.
Turning doctors’ notes into usable signals
Much of what clinicians know about a patient lives in free‑text notes rather than in tidy fields. The researchers tapped into these written notes—taken within 5 to 30 days before death for veterans who died by suicide, and in the same window for matched veterans who did not—to see whether patterns in language could sharpen risk prediction. They compared two ways of processing text. One was a “semantic” method that starts from expert‑built dictionaries capturing ideas such as family ties, pleasure, or negative feelings. The other was a “count” method that simply tallies how often specific words or short phrases appear, letting the data reveal patterns without prior assumptions.
Combining two lenses on language
Using these ingredients, the team built machine‑learning models that tried to distinguish veterans who died by suicide from similar veterans who did not, separately within three groups: high, moderate, and low predicted risk according to REACH-VET. They created models that used only semantic features, only word counts, or a hybrid of both. To fairly blend the two text approaches, they adjusted the model so that semantic features, which are fewer in number, would still have a chance to influence decisions alongside the far more numerous count features. Performance was measured using a standard metric that asks, in essence, how often the model gives a higher risk score to someone who died by suicide than to a matched person who did not.
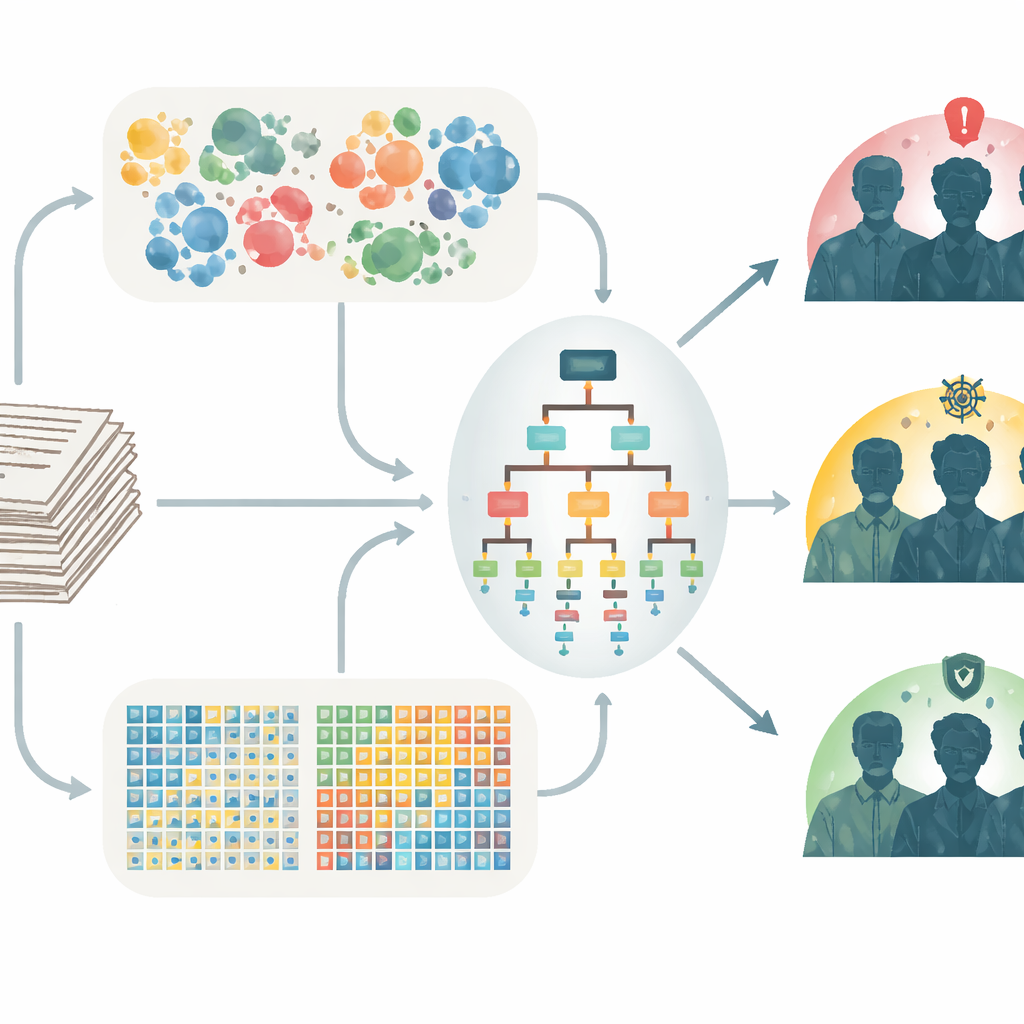
What the models discovered
Across all three risk groups, models based solely on word counts generally outperformed models that used only semantic dictionaries. Yet the most successful models for veterans in the moderate and low REACH-VET tiers were hybrids that leaned heavily on word counts while still drawing some information from semantic measures. These combined models achieved moderate gains over REACH-VET alone, with the largest improvements for veterans initially labeled low risk, who also tended to have fewer medical encounters and less structured data. The language patterns that mattered differed by group: high-risk notes emphasized acute mental health problems, moderate-risk notes highlighted care processes, and low-risk notes leaned toward general medical and rehabilitation themes, as well as signs of social connection or its absence.
Implications for care and prevention
These findings suggest that unstructured text in electronic health records contains valuable clues that can refine suicide risk estimates, especially for people not already in the highest-risk category. By blending simple word‑count patterns with more theory‑driven semantic signals, and tailoring models to different risk tiers, health systems may be able to spot vulnerable veterans earlier and design interventions that match their level and type of risk. For lower‑risk patients, this might mean lighter‑touch supports such as automated check‑ins, referrals to peer or wellness programs, or routine discussions of social and emotional challenges in regular visits.
What this means for veterans and clinicians
In plain terms, the study shows that paying attention to how clinicians describe their patients—alongside traditional medical data—can make suicide prediction tools more sensitive to veterans who might otherwise slip through the cracks. While the gains are modest and the approach still needs to be tested in real‑time clinical settings, it marks a concrete step toward more personalized, data‑informed suicide prevention that serves not only those in obvious crisis but also those whose risk is quieter, more complex, and easier to miss.
Citation: Dimambro, M., Levy, J., Gui, J. et al. Enhancing personalized suicide risk prediction for VA patients by integrating discrete natural language processing models. Transl Psychiatry 16, 196 (2026). https://doi.org/10.1038/s41398-026-03940-8
Keywords: veteran suicide risk, electronic health records, natural language processing, risk prediction models, mental health care