Clear Sky Science · zh
集成光子学三维张量处理引擎
为何更快的“思考”机器很重要
从自动驾驶汽车到医学扫描仪和虚拟现实,我们的世界越来越依赖能够实时理解复杂三维数据的计算机。如今的人工智能系统功能强大,但推动它们的电子芯片在面对日益增大的、更快速的神经网络时已经吃紧。本文提出了一种使用光而非电来处理这类三维数据的新方法,承诺可以实现更快、更高效的“思考”机器,最终有望让汽车更安全、诊断更迅速,以及让在线体验更沉浸式。
从平面图像到三维世界
许多常见的 AI 系统处理的是平面图像——二维像素网格,使用所谓的卷积神经网络。但现代传感器,如医学扫描仪和自动驾驶车辆上的激光 LiDAR,会随时间捕获完整的三维场景。这些更丰富的数据集自然可以用“张量”来描述,即多维数组。用三维神经网络处理它们非常强大,但也极其苛求:随着每增加一个维度,所需的计算和内存会快速增长。像 GPU 和 TPU 这样的传统电子加速器主要为处理平面二维矩阵运算而构建,因此它们不得不不断重塑与搬运三维数据,浪费时间、能量和内存。
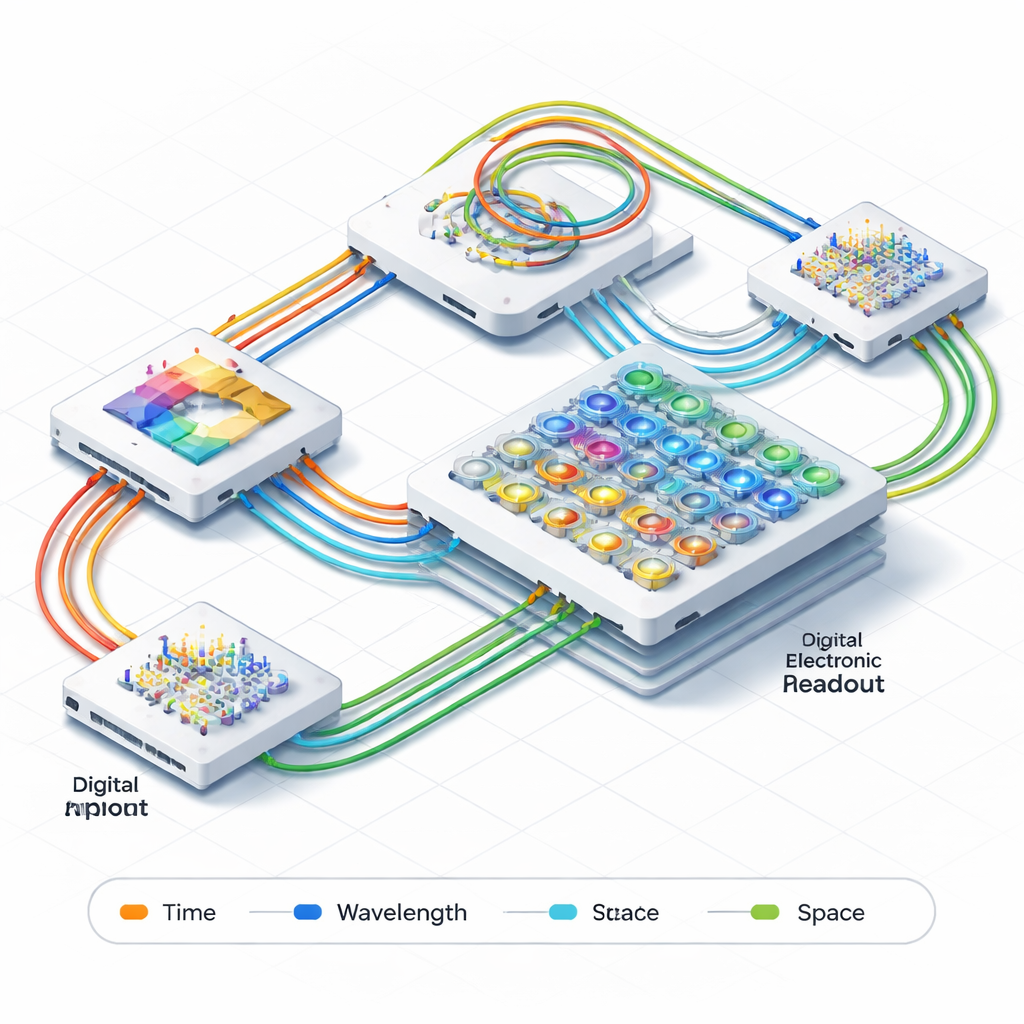
让光来承担繁重工作
研究人员引入了一种集成光子三维张量处理引擎,可直接用光执行三维神经网络中的关键步骤。他们的系统不是反复在内存和电子处理器之间移动数据,而是将信息作为光信号发送,光信号通过芯片上的微小波导和谐振器传输。系统同时使用三种不同的“轴”来编码和处理数据:光的颜色(波长)、脉冲通过的时间以及它们在芯片上所走的物理路径。通过将这三维交织在一起,该系统可以在不将三维卷积切分成许多小任务或依赖笨重电子控制硬件的情况下,直接处理完整的三维卷积运算。
内建的光学存储与同步
高速计算中的一个关键挑战是让多路数据精确对齐时间。传统系统使用复杂的电子时钟电路和大型缓存来实现这一点。在这里,团队完全在光学域内解决了这个问题。他们在主计算模块的前后加入了两个光学存储单元,由可调延迟线构成。这些延迟线像脉冲的可调候车室,让系统能够“缓存”数据并通过简单改变每个脉冲在芯片上行进的时间来同步各通道。延迟可用皮秒(万亿分之一秒)级精度微调,并支持约 2000 亿次每秒的有效时钟速率,而无需额外的电子时序硬件。
为复杂数学设计的智能光路
计算模块的核心是一张微小环形光学谐振器的网格,它们控制每一路光通道对最终结果的贡献强度——类似神经网络中可调的权重。作者在多层光子平台上采用了一种特殊的双环设计,使这些元件对温度变化和制造缺陷不那么敏感,同时提供宽而平坦的光学响应。这意味着这些环能够以更少的失真处理高速信号,并保持精确的权重设置——使用简单校准即可达到优于 7 位的有效精度。在测试中,芯片在符号率最高达 30 吉波(gigabaud)时成功执行了四通道矩阵乘法,展示了速度与精确性的兼备。

用于三维激光感测的真实世界测试
为证明他们的引擎超越实验室基准的实用性,团队将其应用于一个实用的三维识别问题:在 LiDAR 点云数据中区分行人与车辆。他们使用了类似已知实时模型的紧凑三维神经网络,在线下以数字方式训练其参数,然后将关键的三维卷积步骤卸载到光子引擎。以 20 吉波符号率运行时,光学系统生成的特征图与数字计算非常接近,并实现了约 97% 的分类准确率——与传统计算机基本相当,但繁重的三维运算是由光来完成的。
这对日常科技意味着什么
简言之,这项工作表明可以构建一个紧凑的光学“数学引擎”,直接解决三维 AI 工作负载中最难的部分,同时使用更少的内存、更少的电子组件,并有可能比现有设计消耗更少的能量。通过将数据缓存、时序对齐和计算全部保留在光学域内,这种方法降低了复杂性,并为更高速度和更大并行度打开了路径。随着光子集成的进步以及片上光源和放大器的成熟,这类三维张量引擎有望成为未来自动驾驶、医学成像、视频分析和沉浸式虚拟环境设备的关键构件——悄然使用光束帮助机器实时“看见”并理解我们的三维世界。
引用: Wu, Y., Ni, Z., Li, X. et al. Integrated photonic 3D tensor processing engine. Light Sci Appl 15, 154 (2026). https://doi.org/10.1038/s41377-026-02183-y
关键词: 光子计算, 三维神经网络, 光学加速器, LiDAR 识别, 张量处理