Clear Sky Science · zh
Prism-OBI:一种通过视觉感知与特征解耦进行甲骨文识别的新框架
裂骨中的远古线索
三千多年前,古代中国的人们在兽骨和龟甲上刻下向神灵请问的问题,形成了已知最早的汉字书写。如今,甲骨文是研究早期历史的珍贵线索——但大多数仅以磨损、开裂的碎片形式保存,甚至专家也难以辨认。本文介绍了 Prism-OBI,一种新的人工智能系统,旨在透过损坏识别文字,将有意义的笔划与地质噪声分离,并帮助学者以规模化方式解读这些脆弱的记录。
为何古骨难读
甲骨在地下历经千年,受土壤挤压、潮湿与干燥交替侵蚀,并在发掘时发生破裂。字迹常常模糊、断裂或缺失,而骨面上的裂纹与污渍在视觉上容易被误认为刻划的笔划。传统方法要么依赖专家逐一比对辨认,要么使用为清晰现代印刷文本设计的标准字符识别软件。这两类方法在单个字符可能被裂缝分割、部分风化或因不同书写者与时代而呈现细微差异时都显得力不从心。结果是大量材料未被充分利用,仅仅因为难以确认哪个字符是什么就被锁住了。
教计算机看穿损坏
Prism-OBI 通过将识别任务拆成两个精心协调的阶段来应对这一难题,而不是使用单一的大型端到端模型。第一阶段,系统仅关注字符在拓片中的“位置”,而非其含义。在任何 AI 查看图像之前,先进行两步清理流程以增强对比并滤除斑点状扫描噪声,使笔划更为突出。清理后的拓片进入一个定制的检测器,该检测器基于快速目标检测网络并重新工程化为“降解感知”型。它将粗略形状与细微细节分离、突出可能的笔划模式、弱化随机裂缝,并在多尺度上融合信息,从而能可靠地检测到微小与较大字符。该阶段的输出是一组紧密包围每个疑似字符区域的边框。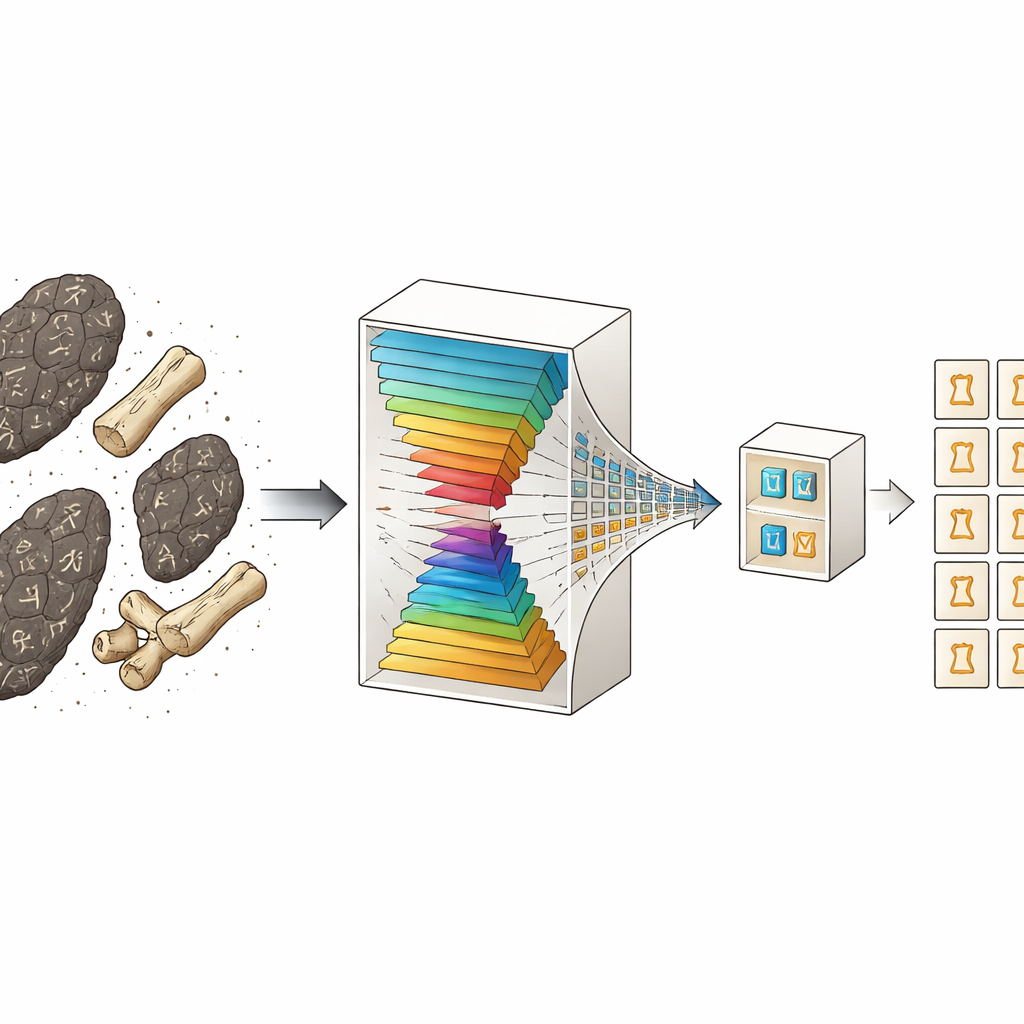
从裁切的符号到识别的字符
在第二阶段,每个裁切出的字符补丁被调整为标准方形并输入到一个改编自常用视觉模型的深度神经网络分类器中。该分类器专长于区分 OBC306 数据集中数百个细微不同的字符,OBC306 包含超过 30 万个甲骨字符,分为 306 类,每类对应一个现代汉字。由于检测器已完成清理与孤立字符的艰巨工作,分类器可以专注于笔划形状与布局上的细微差别——例如微小的勾、断裂或相交处——而不必与原始拓片的背景噪声抗争。测试表明,这种专注检测器与强分类器的配对比更简单的单阶段系统能获得更高的识别准确度,同时仍足够快速,可实现近实时处理。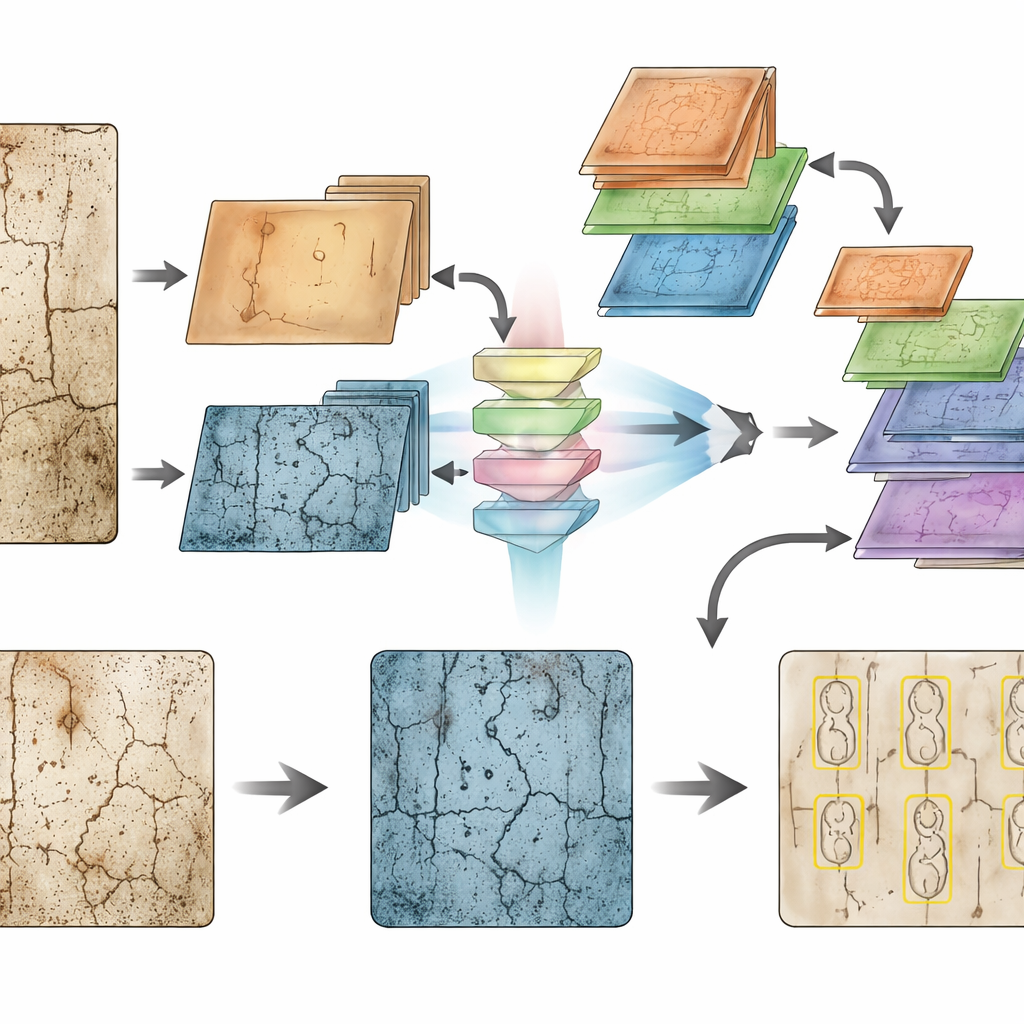
新检测器的内部机制
在幕后,Prism-OBI 的检测器采用了多项针对性技巧以应对严重退化的文物。一模块将视觉信号分解为低频成分(整体轮廓)与高频成分(锐利边缘),使模型能分别处理粗大形状与细微笔尖,随后应用注意力机制以强调一致的笔划模式而抑制随机裂隙。另一个模块构建不同尺度的视图金字塔并学习各尺度的信任度,从而在不被噪声淹没的情况下改善对微小字符与较大字符的检测。第三个模块学习对来自不同网络层的特征进行加权,而不是简单堆叠,有助于保留有信息的信号同时降低不可靠信号的影响。最后,检测头显式编码了水平与垂直位置信息,这在字符密集布局中尤为重要,否则相邻字符容易混淆在一起。
这些结果对文化遗产的意义
在标准甲骨检测数据集上,增强后的检测器相比基线模型显著提升了精确率、召回率与边框整体质量,减少了被漏检的字符与由裂缝产生的误报。配合分类器后,完整的 Prism-OBI 框架在笔记本 GPU 上大约以每秒 32 帧的速度处理图像,同时保持强劲的字符识别性能。早期的定性测试甚至表明,相同的检测器在未经再训练的情况下也能在其他古文字(如金文与篆书)中实现有意义的字符定位,尽管为了获得最佳效果仍需微调。对于非专业人士来说,关键结论是 Prism-OBI 提供了一条实用且可扩展的路径,能够自动读取受损严重的古代书写。通过清晰地将“文字在哪里?”与“文字内容是什么?”分离,该系统将杂乱、破碎的骨面转化为结构化、可检索的文本,帮助历史学家与考古学家比以往更快、更彻底地探索人类最早的书写记录。
引用: Li, J.W., He, J.R., Wu, J.R. et al. Prism-OBI: a novel framework for oracle bone inscription recognition via visual perception and feature decoupling. npj Herit. Sci. 14, 218 (2026). https://doi.org/10.1038/s40494-026-02493-9
关键词: 甲骨文, 古文字识别, 深度学习, 文化遗产数字化, 计算机视觉