Clear Sky Science · sv
Slutsatser vid felklassificering av utfall i hälsoriskmodeller med en simuleringsstudie och en valideringsdatamängd
Varför fel på dödsorsaker spelar roll
Det mesta vi vet om hur miljöfarliga exponeringar påverkar vår hälsa bygger på stora befolkningsstudier som förlitar sig på officiella register, framförallt dödsorsaksintyg. Men vad händer om den dödsorsak som anges på dessa blanketter ibland är felaktig? Den här studien undersöker hur sådana misstag, även när de inte är medvetet vinklade, ändå kan vilseleda oss om huruvida en exponering som lågnivåstrålning faktiskt ökar risken för att dö i cancer. Med hjälp av både verkliga data från tidigare kärnarbetare och omfattande datorbaserade simuleringar visar författarna att den vanliga, lugnande tumregeln — "slumpmässiga misstag bara tonar ner sambandet" — inte alltid gäller för enskilda studier.
Hur hälsostudier använder ofullständiga register
Epidemiologer jämför ofta grupper av människor med olika exponeringsnivåer — till exempel arbetare som fått högre eller lägre doser strålning — och ser hur många i varje grupp som dog i cancer. Dödsorsaksintygen lämnar den officiella dödsorsaken, men decennier av forskning visar att de ofta felmärker vad människor faktiskt dog av. Den vanliga uppfattningen är att om dessa fel är oberoende av exponeringsnivå så främst suddar ut signalen och får en verklig risk att se mindre ut än den egentligen är. Många forskare antar därför att om de kunde rätta till dödsregistren skulle varje samband mellan exponering och sjukdom bara bli starkare.
En verklig testmiljö bland kärnarbetare
Författarna baserade sina simuleringar på en unik grupp tidigare kärnarbetare som gick med i United States Transuranium and Uranium Registries. Dessa frivilliga gick med på detaljerade obduktioner efter döden, vilket gav forskarna ovanligt tillförlitlig information om vad de faktiskt dött av. För 229 arbetare hade teamet både strålningsdoshistorik och två konkurrerande versioner av dödsorsak: den från obduktionen och den från dödsorsaksintyget. Tidigare arbete i denna grupp visade att ungefär en fjärdedel av dödsorsaksintygen felklassificerade den underliggande dödsorsaken, men att dessa fel inte berodde på stråldos — vilket gör detta till en användbar "validerings"-datamängd för att förankra mer omfattande simuleringar.
Simulera många alternativa verkligheter
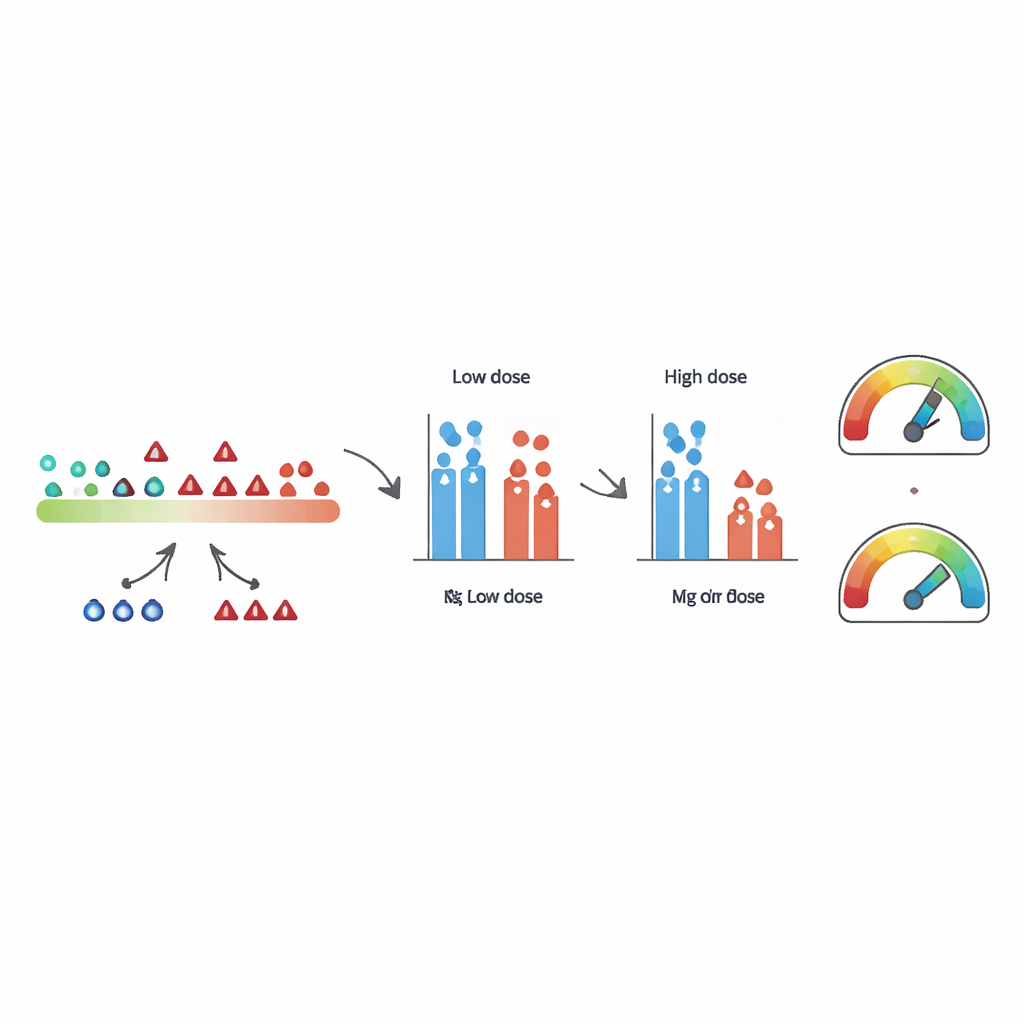
Med denna grund skapade forskarna tusentals konstgjorda studiedatauppsättningar för att se hur utfallsfel kan spela ut i praktiken. De använde både de verkliga dosregistren och större, datorgenererade dosfördelningar som liknade arbetarnas exponeringar. För hälsoutfallet använde de antingen de faktiska obduktionsbaserade cancerdödsfallen eller genererade "sanna" cancerutfall enligt en enkel regel som kopplade dos till cancerrisk. Från varje utgångsdatamängd simulerade de sedan felklassificering genom att slumpmässigt byta ut vissa icke-cancer-dödsfall till cancer och vissa cancer-dödsfall till icke-cancer över ett brett spektrum av felproportioner. För var och en av de 20 000 felklassificerade versionerna i varje scenario beräknade de om hur starkt dosen verkade vara kopplad till cancer och om resultatet skulle bedömas som statistiskt signifikant.
När slumpmässiga fel förstärker en svag signal
Simuleringarna bekräftade att om man kunde upprepa en studie oändligt många gånger och ta medelvärdet av resultaten så tenderar den här typen av fel att dra skattningen mot "ingen effekt." Men bilden förändras när man fokuserar på en enda, verklig studie — den situation forskare och tillsynsmyndigheter faktiskt står inför. En betydande andel av de simulerade studierna, ibland nära hälften, slutade med ett starkare till synes dos–cancer-samband efter felklassificering än före. I scenarier där de ursprungliga data precis understeg konventionell statistisk signifikans kunde även små nivåer av felklassificering få många simulerade studier att hamna över gränsen till "signifikant." I sällsynta fall där det verkliga sambandet i princip saknades, frambringade felklassificering ändå till synes övertygande, men helt falska, samband.
Vad detta betyder för tolkningen av hälsorisker
Dessa fynd visar att även när fel i dödsorsaker inte uppenbart är beroende av exponeringsnivå kan de ändå förvränga slutsatserna i enskilda studier åt båda hållen. Särskilt varnar de för den vårdslösa antagandet att ett observerat gränsfallssamband nödvändigtvis skulle bli starkare om bara data rengjordes. För områden som forskning om lågdoseradiation, där skattade risker är små och debatter kretsar kring p‑värden kring 0,05, kan effekten av även måttlig felklassificering vara betydande. Författarna menar att forskare och läsare bör vara extra försiktiga med sådana resultat och att framtida arbete i större utsträckning bör använda valideringsdata och korrigeringsmetoder för att förstå hur robusta en studiens slutsatser verkligen är mot fel som döljer sig i utfallsregistren.
Citering: Liu, X., McComish, S.L., Howard, S.C. et al. Inference under outcome misclassification in health risk models using a simulation study with a validation dataset. Sci Rep 16, 11981 (2026). https://doi.org/10.1038/s41598-026-41788-6
Nyckelord: fel på dödsorsaksintyg, epidemiologisk bias, lågdoseradiation, cancerdödlighet, simuleringsstudie