Clear Sky Science · sv
Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning
Varför det är viktigt att lära hårdvara att lära sig
Datorer blir bättre på att lära av erfarenhet, men större delen av dagens artificiella intelligens körs fortfarande helt i mjukvara på strömslukande kretsar. Våra hjärnor, däremot, lagrar och bearbetar information på samma plats med långsamma, subtila jonflöden som naturligt anpassar sig över tid. Denna artikel presenterar en ny typ av elektronisk komponent som efterliknar sådana mjuka interna gradienter och gör det möjligt för hårdvara att justera hur snabbt den lär sig när uppgiften och omgivningen förändras. Sådana enheter skulle en dag kunna ge mer energieffektiva, hjärnlika maskiner som fortsätter lära sig kontinuerligt utan att börja om från början.
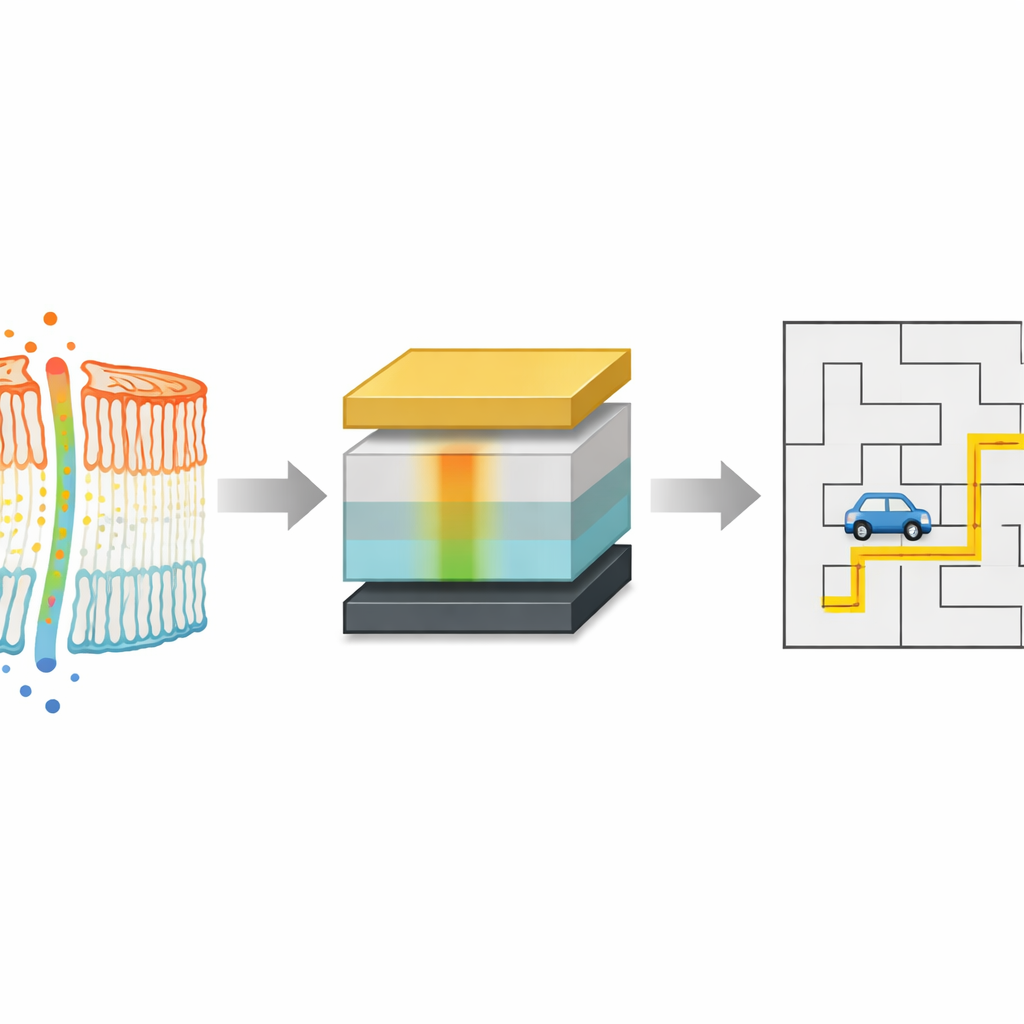
En pytteliten enhet inspirerad av levande celler
Arbetet är inspirerat av hur levande celler använder skillnader i jonkoncentration över sina membran som långvariga energilandskap för signalering och minne. Istället för att försöka kopiera varje biologisk detalj fokuserade forskarna på att återskapa en nyckelfunktion: en inbyggd gradient som ändras långsamt över tid. De byggde en smörgåsliknande elektronisk enhet, kallad en andragradsmemristor, bestående av staplade tunna filmer på en transparent elektrod. Genom att infoga ett särskilt zink-porfyrinmolekylskikt och sedan varsamt deponera ett lager aluminiumoxid ovanpå skapade de en stabil syrekoncentrationsgradient inuti enheten. Denna interna gradient fungerar ungefär som insida–utsida-skillnaden över ett cellmembran och lagrar en historia av tidigare elektrisk aktivitet.
Långsam, kontrollerbar förändring i stället för abrupt växling
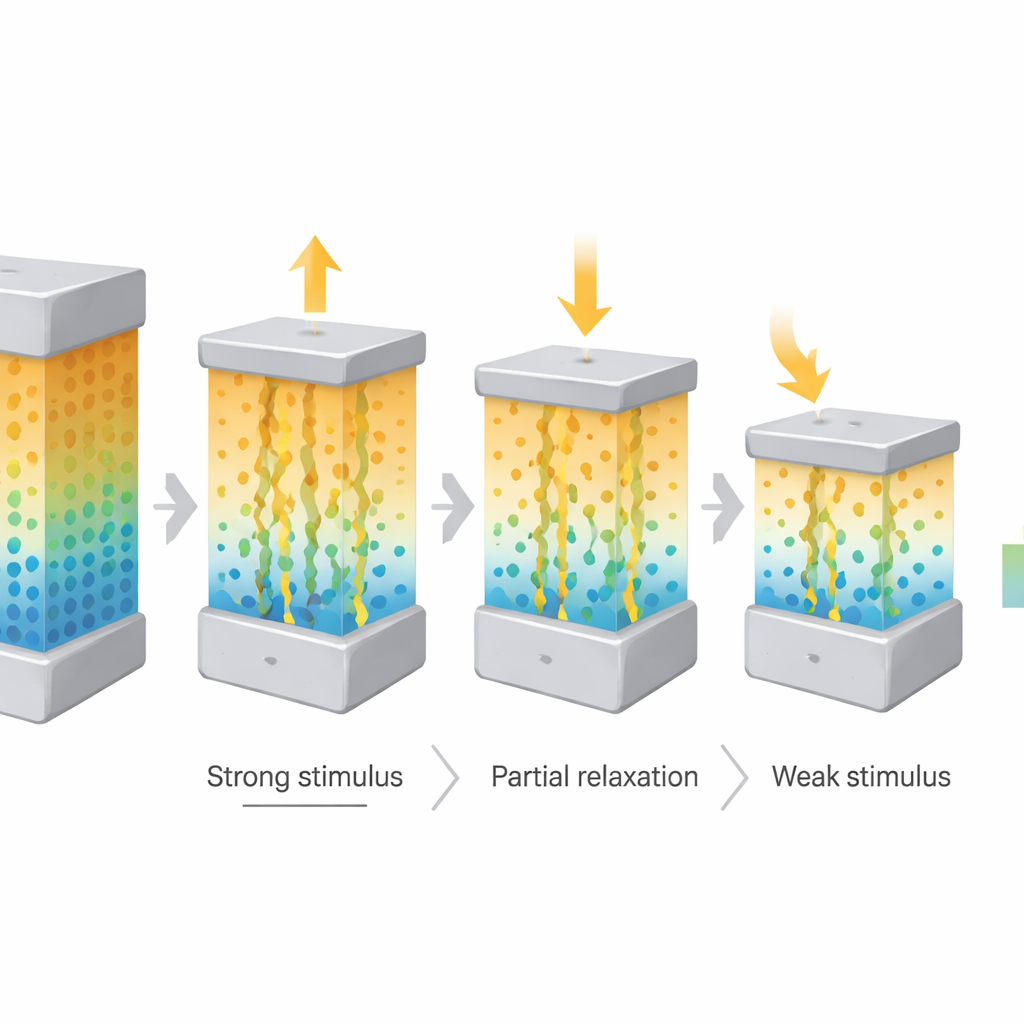
Många befintliga memristorer växlar abrupt mellan tillstånd, vilket är bra för digital lagring men dåligt för att representera gradvisa förändringar över tid. I den nya enheten driver och diffunderar syrejoner långsamt längs den inbyggda gradienten och ger upphov till en mjukt utvecklande elektrisk ledningsförmåga som kan bestå och slappna av över mer än 100 sekunder. Genom att applicera korta elektriska pulser av olika styrka från samma riktning kunde teamet antingen skjuta jonerna längre mot gradienten eller låta dem driva tillbaka, och fint justera ledningsförmågan i stället för att slå den på eller av. Detta beteende, känt som andragradens dynamik, gjorde det möjligt för enheten att skapa ungefär 40 distinkta, långlivade mellanlägen — ”pseudo-icke-flyktiga” tillstånd som inte är permanent fixerade men som förblir stabila tillräckligt länge för att vara användbara för inlärning.
Hur enheten omformar inlärning i praktiken
För att visa varför detta långsamma, gradientdrivna beteende har betydelse kopplade författarna enheten direkt till en vanlig inlärningsregel som används i förstärkningsinlärning, där en agent upprepade gånger utforskar en värld och uppdaterar hur mycket den litar på varje handling. I dessa algoritmer styr en enda parameter — inlärningshastigheten — hur snabbt tidigare erfarenhet överskrivs av ny information. I stället för att välja den hastigheten för hand kopplade de den till de tidsberoende ledningsförändringarna hos sin memristor. Tidigt efter en stark elektrisk puls ändras enhetens ledningsförmåga snabbt; senare stabiliserar den sig till långsammare, mindre justeringar. Att översätta denna naturliga avmattning till inlärningsregeln gör att agenten börjar med djärvt utforskande och sedan gradvis stabiliserar sin strategi, ungefär som ett djur som först experimenterar men senare förfinar sina vanor.
Överträffar konventionell träning i föränderliga världar
Forskarna testade detta hårdvaru-inspirerade inlärningsschema i simulerade navigationsuppgifter där ett autonomt fordon måste hitta en bra väg under kommunikationstäckning. I en statisk värld minskade den memristordrivna inlärningshastigheten antalet träningsiterationer som krävdes för att nå en bra lösning med nästan 70 procent jämfört med fasta eller manuellt justerade scheman, samtidigt som instabila oscillationer och dåliga lokala val reducerades. De gjorde sedan problemet svårare genom att förstora kartorna och ändra förhållanden över flera steg, vilket efterliknade en värld som blir mer komplex över tid. Även där minskade det enhetsbaserade inlärningsmönstret det totala antalet träningsavsnitt med mer än en tredjedel jämfört med standardlinjära scheman och anpassade sig smidigt i takt med att uppgiften växte.
Vad detta betyder för framtida hjärnlika maskiner
För en lekmansläsare är huvudbudskapet att teamet har förvandlat ett mikroskopiskt materialknep — att låsa in en mild syregradient — till ett kraftfullt sätt att styra hur maskiner lär sig över tid. I stället för att förlita sig på noggrant handanpassade mjukvaruinställningar uppstår inlärningsbeteendet naturligt ur enhetens egen långsamma interna fysik. Detta antyder en framtid där neuromorf hårdvara inte bara lagrar siffror utan förkroppsligar inlärningsregler i sitt material, vilket skapar artificiella system som kontinuerligt kan anpassa sig till nya situationer med mindre energiåtgång och mindre mänsklig finjustering.
Citering: Ming, J., Wang, R., Fu, J. et al. Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning. Nat Commun 17, 3367 (2026). https://doi.org/10.1038/s41467-026-70014-0
Nyckelord: memristor, neuromorphic hardware, reinforcement learning, oxygen ion gradient, continual learning