Clear Sky Science · en
Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning
Why teaching hardware to learn matters
Computers are getting better at learning from experience, but most of today’s artificial intelligence still runs entirely in software on power-hungry chips. Our brains, by contrast, store and process information in the same place, using slow, subtle flows of ions that naturally adapt over time. This paper introduces a new type of electronic component that imitates those gentle internal gradients, allowing hardware to adjust how quickly it learns as the task and environment change. Such devices could one day lead to more efficient, brain-like machines that keep learning continuously without starting from scratch.
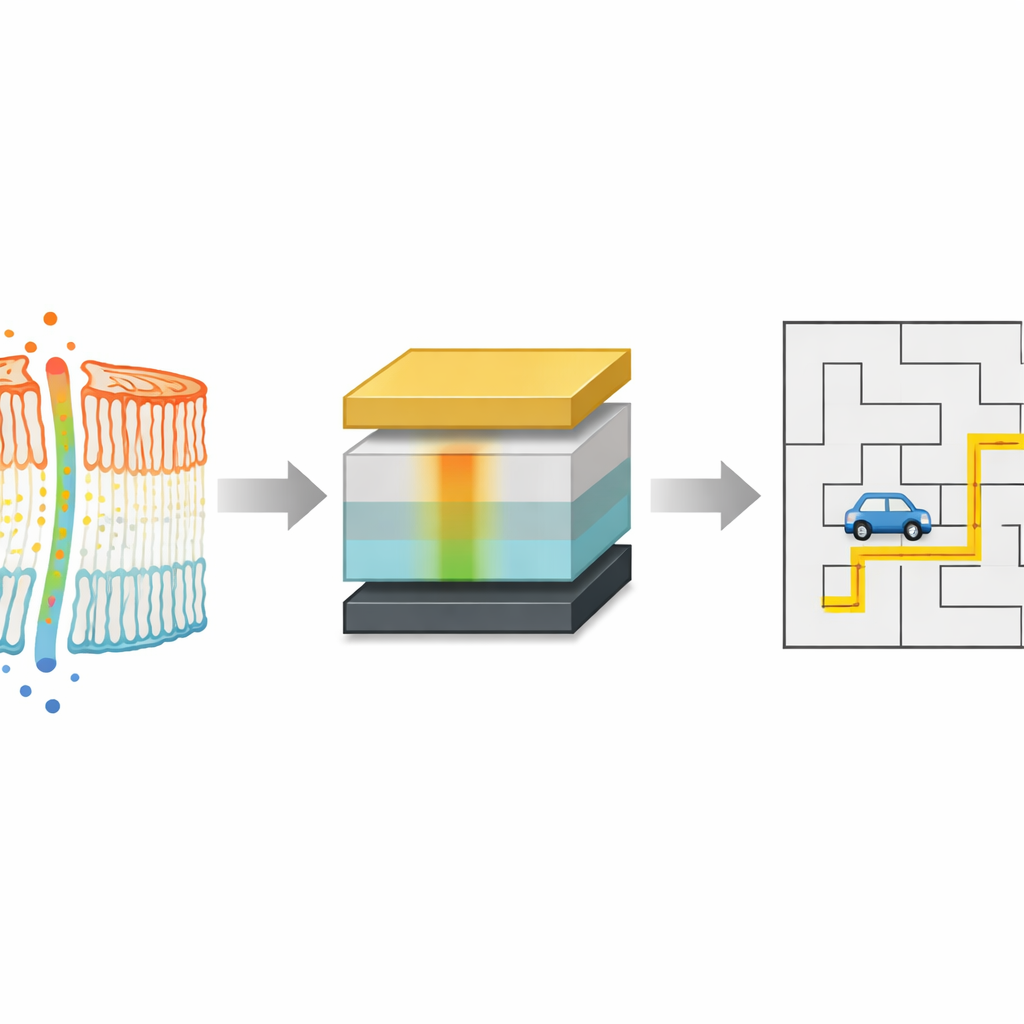
A tiny device inspired by living cells
The work is inspired by how living cells use differences in ion concentration across their membranes as long-lasting energy landscapes for signaling and memory. Instead of trying to copy every biological detail, the researchers focused on reproducing one key feature: a built-in gradient that changes slowly over time. They built a sandwich-like electronic device, called a second-order memristor, made of stacked thin films on a transparent electrode. By inserting a special zinc-porphyrin molecular layer and then carefully depositing an aluminum oxide layer on top, they created a stable oxygen concentration gradient inside the device. This internal gradient acts rather like the inside–outside difference across a cell membrane, storing a history of past electrical activity.
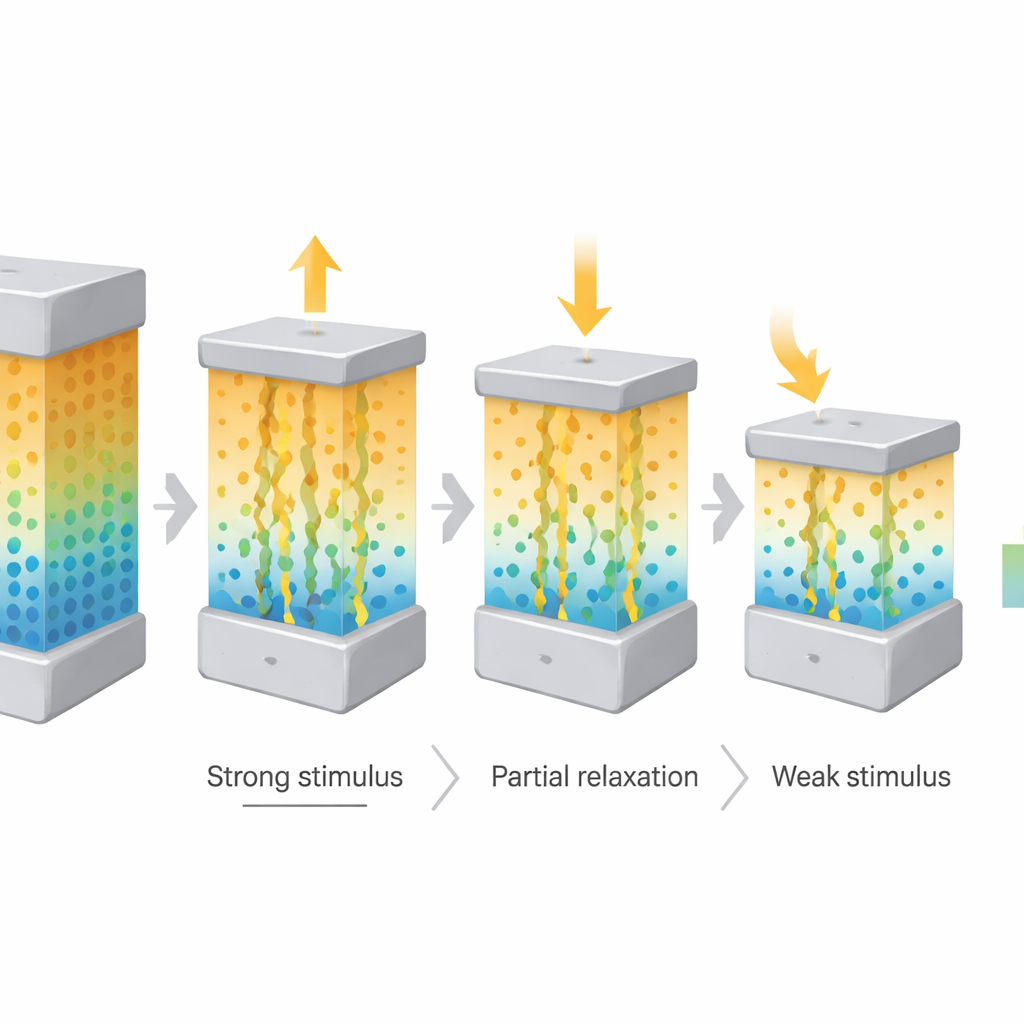
Slow, controllable change instead of abrupt switching
Many existing memristors switch abruptly between states, which is good for digital memory but poor at representing gradual change over time. In the new device, oxygen ions drift and diffuse slowly along the built-in gradient, producing a gently evolving electrical conductance that can persist and relax over more than 100 seconds. By applying short electrical spikes of different strengths from a single direction, the team could either push ions further against the gradient or let them drift back, finely tuning the conductance rather than flipping it on and off. This behavior, known as second-order dynamics, allowed the device to create about 40 distinct, long-lived intermediate levels—"pseudo-nonvolatile" states that are not permanently fixed, yet remain stable long enough to be useful for learning.
How the device reshapes learning in practice
To show why this slow, gradient-driven behavior matters, the authors linked the device directly to a common learning rule used in reinforcement learning, where an agent repeatedly explores a world and updates how much it trusts each action. In these algorithms, a single parameter—the learning rate—controls how quickly past experience is overwritten by new information. Instead of choosing that rate by hand, they mapped it to the time-dependent conductance changes of their memristor. Early after a strong electrical pulse, the device conductance changes rapidly; later, it settles into slower, smaller adjustments. Translating this natural slowdown into the learning rule means the agent starts off exploring boldly and then gradually stabilizes its strategy, much like an animal that initially experiments but later refines its habits.
Beating conventional training in changing worlds
The researchers tested this hardware-inspired learning schedule on simulated navigation tasks where an autonomous vehicle must find a good path under communication coverage. In a static world, the memristor-driven learning rate cut the number of training iterations needed to reach a good solution by nearly 70 percent compared with fixed or manually tuned schedules, while also reducing unstable oscillations and poor local choices. They then made the problem harder by enlarging the maps and changing conditions over multiple stages, mimicking a world that grows more complex over time. Even there, the device-derived learning pattern reduced the total number of training episodes by more than a third relative to standard linear schemes, adapting smoothly as the task scaled up.
What this means for future brain-like machines
For a lay reader, the core message is that the team has turned a microscopic material trick—locking in a gentle oxygen gradient—into a powerful way to control how machines learn over time. Rather than relying on carefully hand-tuned software settings, the learning behavior emerges naturally from the device’s own slow internal physics. This suggests a future in which neuromorphic hardware does not just store numbers but embodies learning rules in its material structure, making artificial systems that can continually adapt to new situations with less energy and less human fine-tuning.
Citation: Ming, J., Wang, R., Fu, J. et al. Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning. Nat Commun 17, 3367 (2026). https://doi.org/10.1038/s41467-026-70014-0
Keywords: memristor, neuromorphic hardware, reinforcement learning, oxygen ion gradient, continual learning