Clear Sky Science · ru
Повышение надежности оценки качества арабской онлайн-медицинской информации с помощью улучшенной архитектуры BERT и взвешивания признаков PCA и ICA
Почему медицинским онлайн‑советам нужен умный фильтр
Все больше людей ищут в интернете ответы о сердечных заболеваниях, инсультах, кровяном давлении и других неотложных проблемах со здоровьем. При этом многие сайты на арабском языке дают советы, которые неполны, устарели или просто неверны. В этой статье описывается, как исследователи создали систему искусственного интеллекта, которая читает арабские медицинские веб‑страницы и оценивает, насколько их информация заслуживает доверия, с точностью, близкой к оценке экспертов‑людей. Их цель — помочь пациентам, семьям и будущим цифровым помощникам избегать вводящих в заблуждение медицинских рекомендаций в интернете.
Отбор полезной медицинской информации среди бесполезной
Авторы начинают с описания серьёзной проблемы: большинство онлайн‑медицинских материалов низкого качества, но люди часто воспринимают их как надёжные и иногда используют вместо посещения врача. Ранее автоматические попытки оценивать веб‑страницы в основном ориентировались на английский язык, использовали узкие определения качества и мало учитывали, насколько уверенными и хорошо калиброванными были системы ИИ. В этом исследовании внимание сосредоточено на арабском контенте и применяется более широкое представление о качестве, включающее авторство, актуальность, наличие доказательной базы и ясность описания пользы и рисков лечения. Человеческие рецензенты оценили сотни арабских страниц по неотложным состояниям, таким как инфаркт и инсульт, создав подробный эталонный набор данных с метками «высокое качество» и «низкое качество».

Обучение машины чтению арабских медицинских текстов
Для оценки новых страниц исследователи обратились к современным языковым моделям — системам ИИ, обученным понимать текст. Они начали с арабского BERT, мощной модели, которая представляет каждое слово как точку в многомерном пространстве, отражающем значение и контекст. Затем создали специализированную медицинскую версию, дообучив её на более чем 100 миллионах слов из арабских медицинских книг и сайтов, чтобы модель лучше понимала технические выражения и типичные описания симптомов и методов лечения. Поскольку веб‑страницы могут быть длинными, команда разбивала их на управляемые фрагменты и очищала текст, чтобы орфографические варианты и специальные символы не путали модель.
Понимание сложных закономерностей
Даже после того как BERT преобразует веб‑страницу в числовые представления, результат остаётся большим и частично избыточным. Поэтому авторы применили математические методы — метод главных компонент (PCA) и метод независимых компонент (ICA) — чтобы сжать эти представления в более компактные и информативные наборы признаков. PCA находит направления, захватывающие наибольшую изменчивость данных, тогда как ICA пытается разделить перекрывающиеся сигналы на более независимые составляющие. Эти сокращённые наборы признаков затем передаются в финальный слой, который решает, вероятно ли страница является высококачественной или низкокачественной. Команда также экспериментировала с модифицированным правилом обучения, которое наказывает модель за расплывчатые предсказания, подталкивая её к более чётким и уверенным решениям.
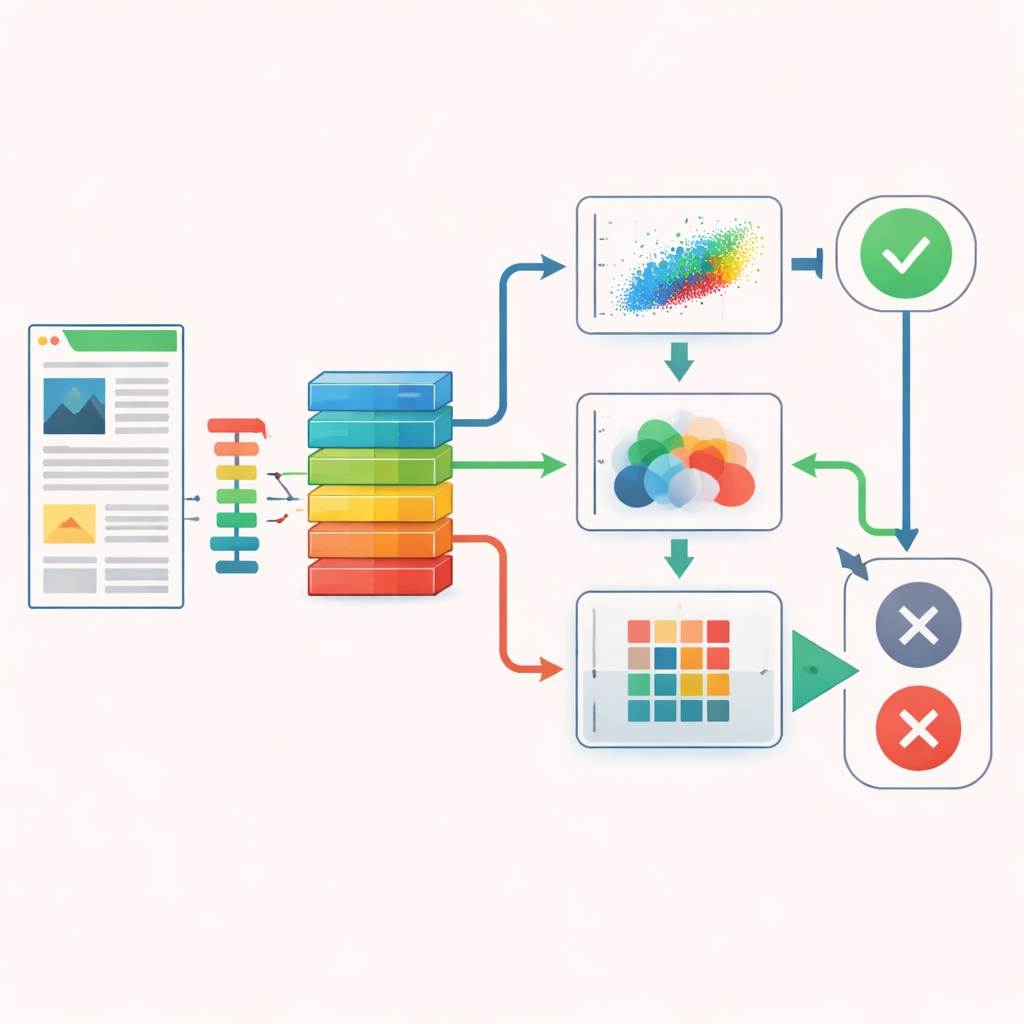
Насколько хорошо работает система
Поскольку низкокачественных страниц значительно больше, чем высококачественных, авторы применили несколько методов увеличения данных, например обратный и прямой машинный перевод, чтобы сбалансировать обучающие примеры. Они оценивали различные версии системы с использованием стандартных метрик, таких как точность и F1‑score, а также более современных показателей соответствия доверия модели реальности. Лучшая конфигурация сочетала арабский BERT с взвешиванием признаков на основе PCA, достигнув примерно 94,7% точности — на уровне или немного выше, чем у человеко‑рецензентов в сопоставимых задачах. Другие версии, включая специализированную медицинскую модель и энтропийную функцию потерь, предоставляли компромиссы между чистой точностью и тем, насколько равномерно они относились к высоким и низким качествам страниц или насколько осторожно выражали уверенность.
Что это может значить для пациентов и врачей
С точки зрения неспециалиста ключевое сообщение таково: теперь возможно создавать инструменты ИИ, которые выступают в роли опытных рецензентов арабских медицинских сайтов, выделяя надёжные страницы и помечая сомнительные. Авторы подчёркивают, что такие системы должны поддерживать, а не заменять медицинских специалистов, однако их работа указывает на практические применения — например, плагины для браузеров, предупреждающие пользователя, поисковые системы, повышающие ранжирование надёжных источников, или медицинские чат‑боты, которые выборочно фильтруют использованную ими информацию. При дальнейшем тестировании и соблюдении мер безопасности эти методы могут стать важным уровнем защиты для уязвимых пациентов от вводящих в заблуждение онлайн‑советов.
Цитирование: Baqraf, Y., Keikhosrokiani, P. & Cheah, YN. Enhancing trustworthiness of Arabic online health information quality evaluation using an enhanced BERT architecture with PCA and ICA feature weighting. Sci Rep 16, 12434 (2026). https://doi.org/10.1038/s41598-026-43158-8
Ключевые слова: онлайн-медицинская информация, арабский язык, медицинская дезинформация, глубокое обучение, BERT