Clear Sky Science · pt
Mecanismo integrado fotônico para processamento de tensores 3D
Por que máquinas que pensam mais rápido importam
De carros autônomos a scanners médicos e realidade virtual, nosso mundo depende cada vez mais de computadores capazes de entender dados tridimensionais complexos em tempo real. Os sistemas de inteligência artificial atuais são poderosos, mas os chips eletrônicos que os alimentam estão no limite diante da demanda por redes neurais cada vez maiores e mais rápidas. Este artigo apresenta uma nova forma de lidar com dados 3D usando luz em vez de eletricidade, prometendo máquinas “pensantes” mais rápidas e eficientes que, no futuro, podem tornar carros mais seguros, acelerar diagnósticos e tornar experiências on-line mais imersivas.
De imagens planas a mundos 3D
Muitos sistemas de IA conhecidos trabalham com imagens planas — grades bidimensionais de pixels — usando as chamadas redes neurais convolucionais. Mas sensores modernos, como scanners médicos e LiDARs a laser em veículos autônomos, capturam cenas 3D completas ao longo do tempo. Esses conjuntos de dados mais ricos são naturalmente descritos como “tensores”, ou arranjos multidimensionais. Processá-los com redes neurais 3D é extremamente potente, mas também extremamente exigente: a quantidade de cálculo e memória necessária cresce rapidamente a cada dimensão adicionada. Aceleradores eletrônicos convencionais, como GPUs e TPUs, são em sua maioria projetados para operações matriciais bidimensionais, de modo que precisam constantemente remodelar e reordenar dados 3D, desperdiçando tempo, energia e memória.
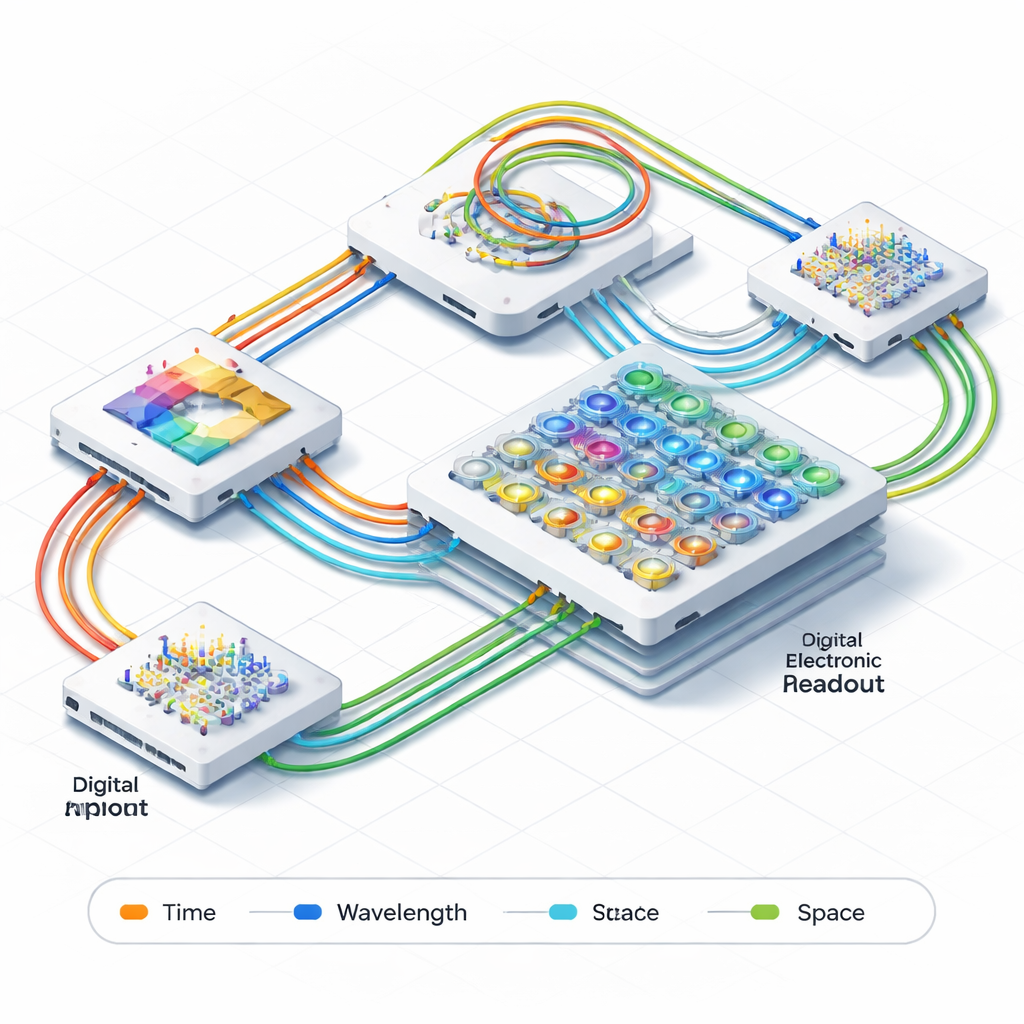
Deixando a luz fazer o trabalho pesado
Os pesquisadores apresentam um mecanismo integrado fotônico de processamento de tensores 3D que realiza uma etapa-chave das redes neurais 3D diretamente com luz. Em vez de mover repetidamente dados entre memória e processadores eletrônicos, o sistema transmite informação como sinais ópticos que viajam por minúsculos guias de onda e ressonadores em um chip. Três “eixos” diferentes são usados para codificar e processar dados simultaneamente: a cor (comprimento de onda) da luz, o tempo em que os pulsos passam e os caminhos físicos que percorrem no chip. Ao entrelaçar essas três dimensões, o sistema pode executar operações convolucionais 3D completas sem fragmentá-las em muitas tarefas menores ou depender de hardware eletrônico volumoso de controle.
Memória óptica integrada e sincronização
Um desafio central em computação de alta velocidade é manter muitos canais de dado precisamente alinhados no tempo. Sistemas tradicionais usam circuitos de clock eletrônicos complexos e grandes buffers de memória para isso. Aqui, a equipe resolve o problema inteiramente no domínio óptico. Eles adicionam duas unidades de memória óptica, feitas de linhas de atraso ajustáveis, antes e depois do bloco principal de computação. Essas linhas de atraso funcionam como salas de espera ajustáveis para pulsos de luz, permitindo que o sistema “cacheie” dados e sincronize canais simplesmente alterando quanto tempo cada pulso viaja no chip. Os atrasos podem ser finamente ajustados com precisão de picosegundos (bilionésimos de segundo) e suportam taxas efetivas de clock de cerca de 200 bilhões de operações por segundo, tudo sem recorrer a hardware eletrônico adicional de temporização.
Circuitos ópticos mais inteligentes para cálculos pesados
No núcleo do bloco de computação está uma grade de minúsculos ressonadores ópticos em forma de anel que controlam o quanto cada canal de luz contribui para o resultado final — análogo aos pesos ajustáveis em uma rede neural. Os autores usam um design especial de anel duplo em uma plataforma fotônica multicamadas que torna esses elementos menos sensíveis a variações de temperatura e imperfeições de fabricação, ao mesmo tempo em que oferece uma resposta óptica larga e plana. Isso significa que os anéis conseguem lidar com sinais de alta velocidade com menos distorção e manter configurações de peso precisas — melhor que 7 bits de precisão efetiva — usando uma calibração simples. Em testes, o chip realizou com sucesso multiplicações de matrizes de quatro canais em taxas de símbolo de até 30 gigabaud, demonstrando velocidade e precisão.

Teste no mundo real com sensoriamento a laser 3D
Para mostrar que o mecanismo é útil além de métricas de laboratório, a equipe o aplicou a um problema prático de reconhecimento 3D: distinguir pedestres de veículos em dados de nuvem de pontos LiDAR. Usaram uma rede neural 3D compacta, similar a modelos conhecidos de tempo real, treinaram seus parâmetros digitalmente e então descarregaram a etapa crucial de convolução 3D para o motor fotônico. Operando a uma taxa de símbolo de 20 gigabaud, o sistema óptico produziu mapas de características que correspondiam de perto aos cálculos digitais e obteve uma precisão de classificação de cerca de 97% — essencialmente igual a um computador tradicional, mas com a parte pesada da matemática 3D realizada pela luz.
O que isso significa para a tecnologia cotidiana
Em termos simples, este trabalho mostra que é possível construir um “motor matemático” óptico compacto que enfrenta diretamente a parte mais difícil das cargas de trabalho de IA 3D, usando menos memória, menos componentes eletrônicos e potencialmente muito menos energia do que os designs atuais. Ao manter cache, alinhamento temporal e computação no domínio óptico, a abordagem reduz complexidade e abre caminho para maiores velocidades e mais paralelismo. Conforme a integração fotônica melhora e fontes de luz e amplificadores on-chip amadurecem, tais motores de tensores 3D podem se tornar blocos de construção chave em dispositivos futuros para direção autônoma, imagens médicas, análise de vídeo e ambientes virtuais imersivos — usando discretamente feixes de luz para ajudar máquinas a ver e entender nosso mundo 3D em tempo real.
Citação: Wu, Y., Ni, Z., Li, X. et al. Integrated photonic 3D tensor processing engine. Light Sci Appl 15, 154 (2026). https://doi.org/10.1038/s41377-026-02183-y
Palavras-chave: computação fotônica, redes neurais 3D, aceleradores ópticos, reconhecimento LiDAR, processamento de tensores