Clear Sky Science · pl
Kontext narracyjny przesuwa spojrzenie z saliency wizualnej na semantyczną
Dlaczego nasze oczy nie podążają wyłącznie za najjaśniejszym elementem
Kiedy patrzysz na obraz, twoje oczy przeskakują gwałtownie, zatrzymując się krótko na różnych częściach sceny. Może się wydawać oczywiste, że wzrok przyciągany jest do tego, co najbardziej kolorowe lub ma największy kontrast. Jednak w codziennym życiu zwykle śledzimy opowieści — oglądamy film, czytamy komiks, przewijamy zdjęcia — i próbujemy zrozumieć, co się dzieje. To badanie stawia proste, ale silne pytanie: w miarę rozwijania się narracji, czy nasze oczy nadal gonią za najbardziej efektownymi elementami, czy przesuwają się ku częściom istotnym dla zrozumienia fabuły?
Oglądanie bezsłownych historyjek obrazkowych
Naukowcy poprosili dorosłych o obejrzenie krótkich, bezsłownych opowieści obrazkowych o chłopcu i jego zwierzęcych przyjaciołach. Każda historia składała się z 24 ręcznie rysowanych obrazów, które w swoim pierwotnym porządku tworzyły wyraźny początek, środek i koniec. Czasem uczestnicy oglądali obrazy we właściwej kolejności, tak że mogli zbudować spójną narrację w myślach. Innym razem te same obrazy były przemieszane w losowej kolejności, mieszając fabułę przy zachowaniu identycznej zawartości wizualnej. Przez cały czas ludzie mieli po prostu swobodnie oglądać obrazki, a ich ruchy oczu rejestrowano sprzętem do śledzenia z dużą precyzją.
Pomiary tego, co wizualnie rzuca się w oczy versus tego, co ma znaczenie
Aby zrozumieć, jakie aspekty każdego obrazu przyciągały wzrok, zespół porównał dwa zupełnie różne rodzaje „ważności”. Po pierwsze, oszacowali saliencję wizualną — jak bardzo obiekt wyróżnia się wyłącznie ze względu na właściwości obrazu, takie jak kontrast czy krawędzie — używając zaawansowanych modeli komputerowego widzenia, które przewidują, gdzie ludzie zwykle patrzą na pojedyncze obrazki. Po drugie, oszacowali saliencję semantyczną — jak ważny jest dany obiekt dla zrozumienia historii. W tym celu oddzielni wolontariusze napisali krótkie narracje opisujące każdą sekwencję obrazów w spójnym porządku. Duży model językowy (nowoczesny system AI szkolony na tekście) został następnie użyty do obliczenia, jak zaskakujące były poszczególne słowa w tych narracjach, biorąc pod uwagę wcześniejszy kontekst, a te miary zaskoczenia przypisano do konkretnych obiektów na obrazach (na przykład zazdrosna żaba, która nagle ugryza inną żabę).
Jak kolejność zdarzeń zmienia gdzie i kiedy patrzymy
Mając te miary, autorzy zbadali dwa aspekty spojrzenia: jak często każdy obiekt był fiksowany oraz jak szybko przyciągał pierwsze spojrzenie. W obu warunkach, wyraźnie wizualnie salientne obiekty były, co nie zaskakuje, oglądane częściej i wcześniej niż inne części obrazu. Kluczowe odkrycie pojawiło się przy porównaniu spójnej i przemieszanej kolejności historii. Gdy obrazki tworzyły znaczącą sekwencję, widzowie patrzyli stosunkowo częściej na obiekty semantycznie ważne — te, które niosły ciężar narracyjny — niż wtedy, gdy te same obrazy były poodwracane. Skłaniali się również ku patrzeniu na te znaczące obiekty wcześniej w czasie w ramach każdego pięciosekundowego okresu oglądania. W przeciwieństwie do tego, przewaga wizualnie efektownych obiektów nie wzrastała w spójnych historiach; jeśli już, to ich wczesna dominacja szybciej zanikała, gdy można było skonstruować sensowną narrację.
Przebieg czasowy przesuwania uwagi
Badanie śledziło także, jak ta równowaga zmieniała się w kolejnych ruchach oczu. Pierwsze kilka fiksacji po pojawieniu się nowego obrazu było silnie ukierunkowane przez saliencję wizualną, niezależnie od kontekstu: oczy początkowo przeskakiwały do fizycznie prominentnych części sceny. Jednak w miarę kontynuowania oglądania, szczególnie po kilku fiksacjach, pojawiała się dywergencja. W sekwencjach przemieszanych ludzie wciąż faworyzowali regiony wizualnie salientne. W sekwencjach spójnych ich spojrzenia coraz bardziej przesuwały się ku obiektom semantycznie istotnym, które pomagały aktualizować wewnętrzny model rozwijającej się opowieści. Ten wzorzec utrzymywał się nie tylko dla pojedynczego najbardziej saliencyjnego obiektu, lecz dla wszystkich obiektów na scenie: w spójnych historiach znaczenie semantyczne lepiej przewidywało zarówno to, jak często, jak i jak szybko obiekty były fiksowane.
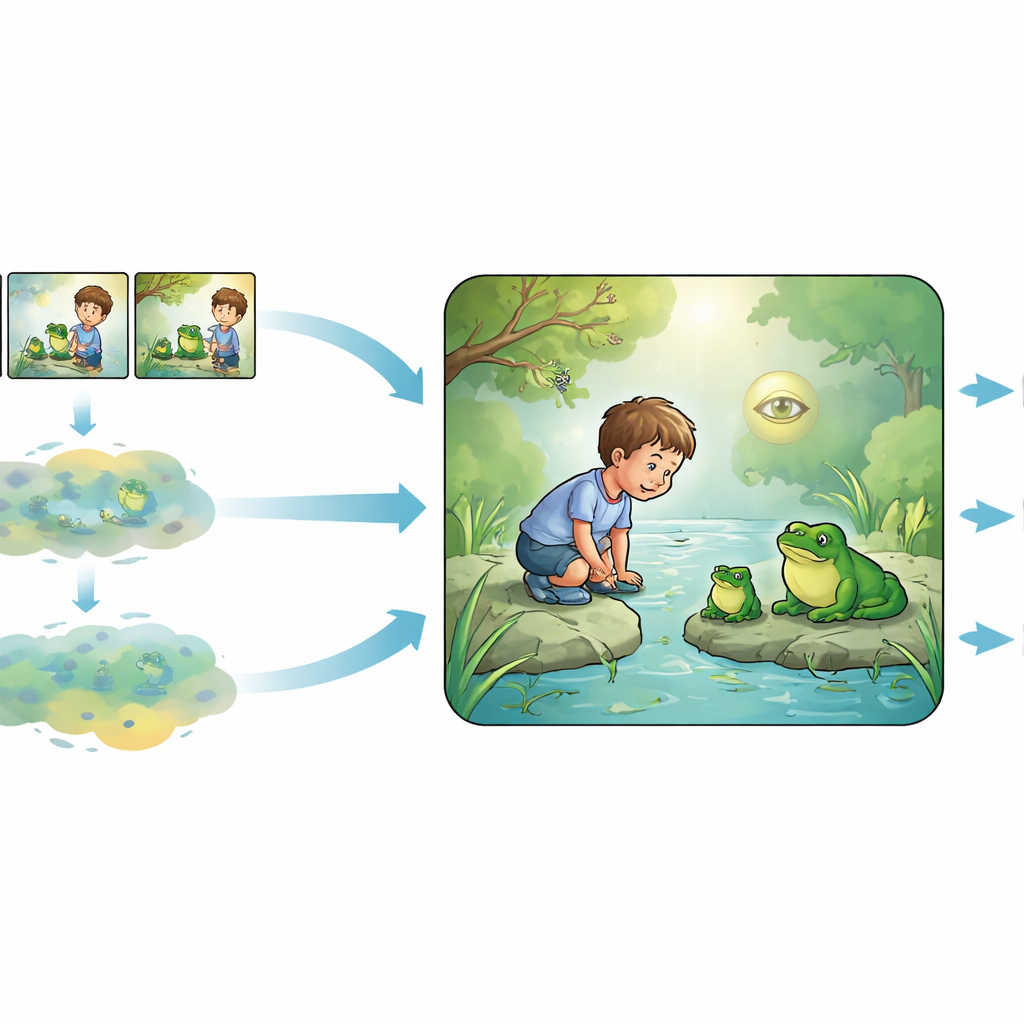
Co to mówi o tym, jak rozumiemy sceny
Wyniki sugerują, że nasze oczy nie są jedynie niewolnikami jasności i kontrastu. Zamiast tego służą naszej ciekawości i zrozumieniu. Na pierwszy rzut oka wybieramy najbardziej „głośne” wizualnie części sceny, ale w ciągu ułamka sekundy nasze wewnętrzne pytanie „co się tu dzieje?” zaczyna kierować wzrokiem ku elementom istotnym dla opowieści — nawet jeśli te elementy są wizualnie niepozorne, jak nijakie drzwi czy zirytowana żaba. Łącząc śledzenie wzroku, modele oparte na obrazie i AI oparte na języku, badanie pokazuje, że kontekst narracyjny przekształca sposób, w jaki eksplorujemy obrazki. W codziennym życiu oznacza to, że ruchy oczu dają wgląd nie tylko w to, co widzimy, lecz także w niewidzialną historię, którą budujemy w naszych umysłach.
Cytowanie: Berlot, E., Schmitt, LM., Huber-Huber, C. et al. Narrative context shifts gaze from visual to semantic salience. Commun Psychol 4, 59 (2026). https://doi.org/10.1038/s44271-026-00426-7
Słowa kluczowe: ruchy oczu, uwaga wzrokowa, percepcja opowieści, saliencja semantyczna, modele językowe