Clear Sky Science · pl
Kwantowo zainspirowana klasyfikacja losowych stanów mieszanych
Dlaczego ukryte wzorce kwantowe mają znaczenie
Technologie kwantowe, takie jak ultrabezpieczna komunikacja i potężne nowe komputery, opierają się na osobliwym rodzaju powiązań między cząstkami zwanych korelacjami, w szczególności splątaniem. W praktyce laboratoryjnej rzeczywiste systemy kwantowe są jednak zanieczyszczone i hałaśliwe, co utrudnia określenie, jakie korelacje rzeczywiście występują. W artykule przedstawiono nowy sposób automatycznego dzielenia zaszumionych stanów kwantowych na trzy szerokie rodziny — nieskorelowane, skorelowane klasycznie i rzeczywiście splątane — wykorzystując pomysły zapożyczone z tego, jak sam układ kwantowy próbowałby rozróżniać stany. Metoda działa na zwykłym komputerze, ale jest prowadzona przez zasady fizyki kwantowej od podstaw.
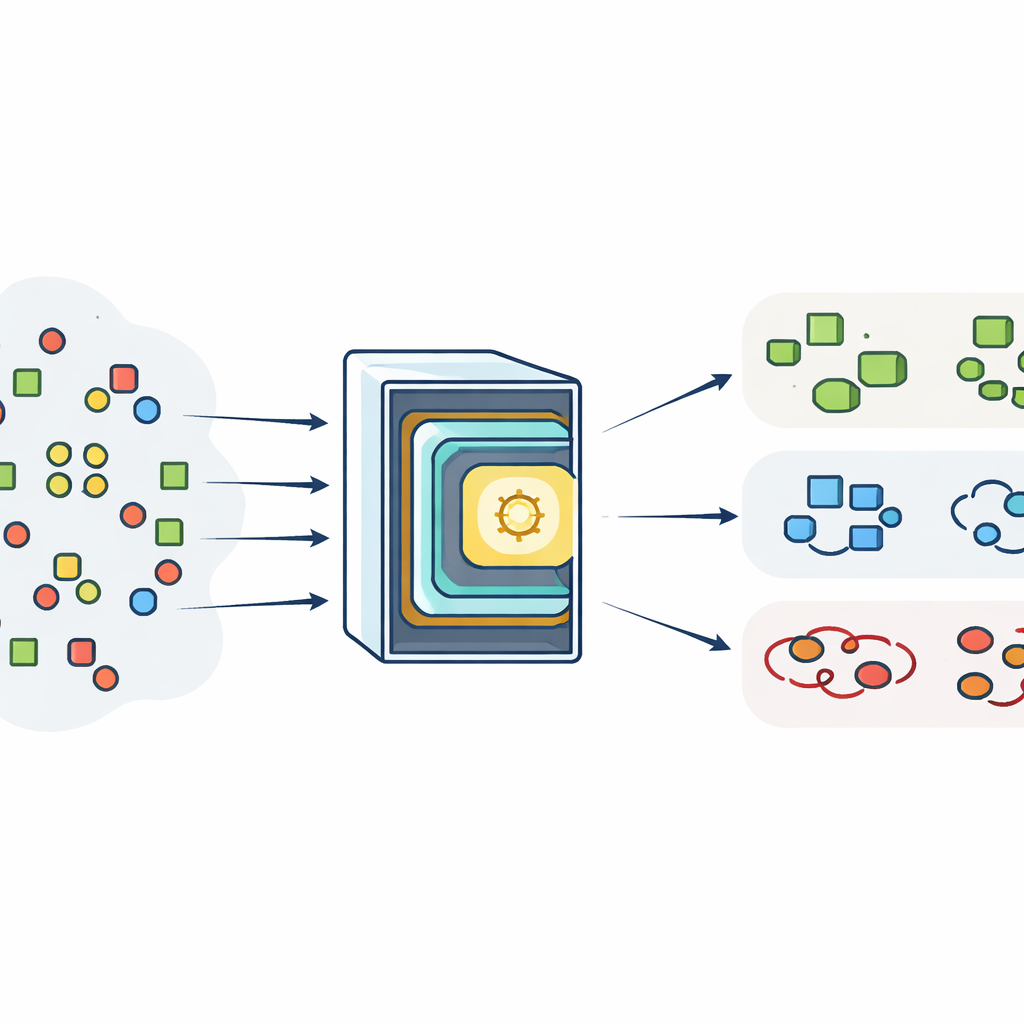
Sortowanie stanów kwantowych jak e‑mail
Inżynierowie coraz częściej korzystają z uczenia maszynowego do rozpoznawania wzorców w danych kwantowych, podobnie jak filtry antyspamowe sortują pocztę elektroniczną. Niektóre podejścia działają bezpośrednio na sprzęcie kwantowym, inne używają klasycznych algorytmów, które jedynie czerpią inspirację z teorii kwantowej. Kluczowym miernikiem dla tych metod jest zdolność do poprawnej klasyfikacji różnych wzorców korelacji w małych układach kubitów. Dla dwóch i trzech kubitów stany mogą być całkowicie niezależne, jedynie klasycznie zmieszane lub autentycznie splątane w sposoby wykorzystywane przez technologie kwantowe. Rozróżnianie tych przypadków jest proste dla idealizowanych, perfekcyjnie przygotowanych stanów; staje się znacznie trudniejsze, gdy pojawiają się niedoskonałości i szum, tworząc tzw. stany mieszane, które łączą wiele możliwości.
Klasyfikator zainspirowany pomiarami kwantowymi
Autorzy opracowali metodę opartą na koncepcji zwanej Pretty-Good-Measurement (PGM), wcześniej testowanej na idealnych stanach czystych. W teorii kwantowej pomiar można zaprojektować tak, by jak najbardziej niezawodnie rozróżniał kilka możliwych stanów, znając przykłady każdej opcji. PGM to konkretna recepta na taki niemal optymalny pomiar. Badacze przekładają ten pomysł na regułę klasyfikacji danych numerycznych: najpierw zamieniają każdy stan kwantowy w zbiorze treningowym na reprezentację macierzową, potem obliczają średnią „prototypową” macierz dla każdej klasy. Na podstawie tych prototypów i ich częstości matematycznie konstruują zestaw operatorów przypominających pomiary, które po zastosowaniu do nowego stanu zwracają wyniki wskazujące, jak prawdopodobne jest przynależenie do każdej klasy. W przeciwieństwie do sieci neuronowych, procedura ta nie wymaga iteracyjnego trenowania; gdy średnie klas są znane, reguła decyzyjna jest matematycznie ustalona.
Generowanie uczciwych i realistycznych zestawów danych kwantowych
Aby sprawiedliwie przetestować swoją metodę, autorzy musieli wygenerować losowe stany mieszane, które rzeczywiście pokrywają pełne spektrum możliwych korelacji, bez ukrytych uprzedzeń. Naiwne sposoby próbkowania macierzy mają tendencję do wytwarzania stanów niemal czystych lub niemal całkowicie losowych, pomijając wiele interesującego „środkowego” obszaru. Zamiast tego zespół używa konstrukcji opartych na symetrii z teorii kwantowej: zaczynają od jednostajnie losowych stanów czystych w większym układzie i matematycznie „śledzą” niewidzialne środowisko, pozostawiając stany mieszane dla kubitów będących przedmiotem zainteresowania. Poprzez ostrożny wybór rozmiaru tego środowiska mogą kontrolować, jak zaszumione są otrzymane stany i jak często pojawia się splątanie. Definiują jasne, operacyjne reguły oznaczania każdego stanu — używając standardowych testów do stwierdzenia, czy stan jest rozdzielny, częściowo skorelowany, czy na pewno splątany — i konstruują zbilansowane zbiory danych dla układów dwukubitowych i trzykubitowych.
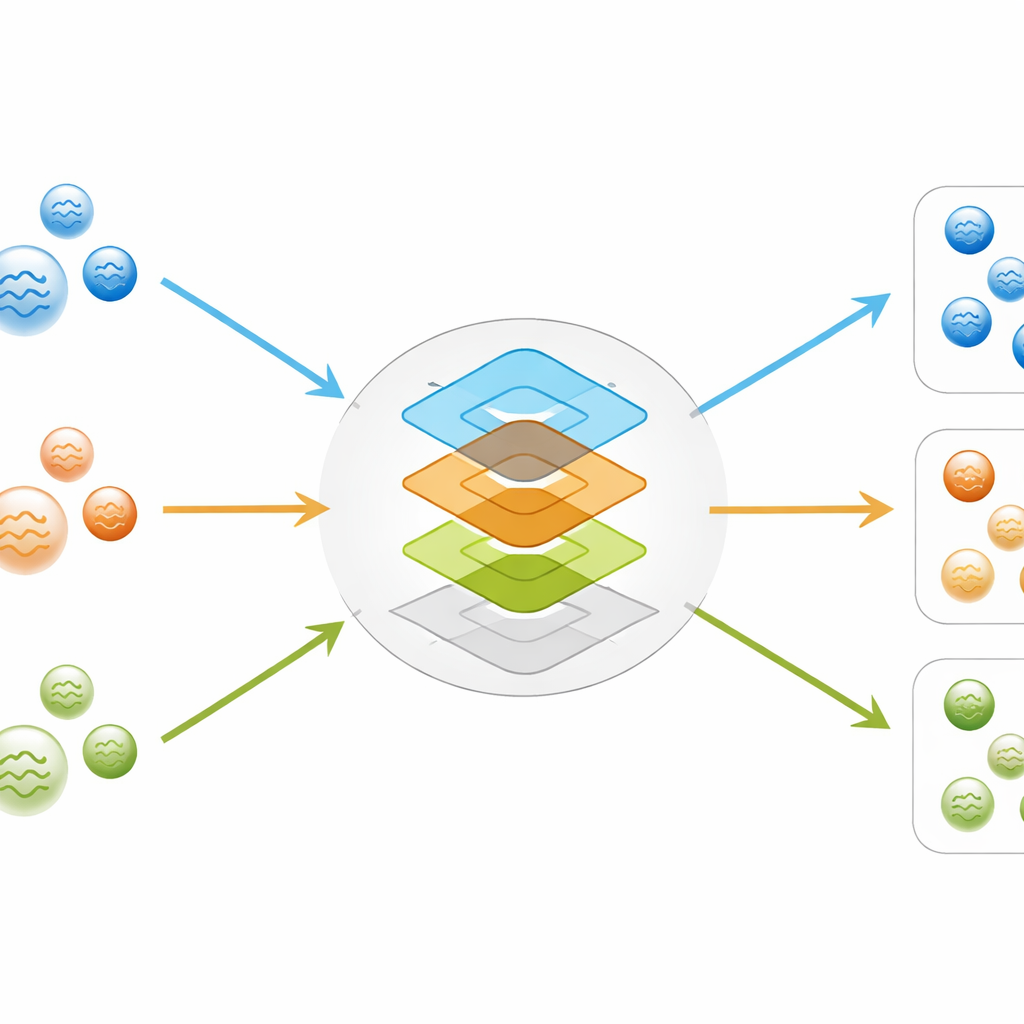
Jak dobrze sprawdza się podejście inspirowane kwantami?
Z tymi zestawami danych klasyfikator PGM porównano z szeregiem znanych metod klasycznych, w tym drzewami decyzyjnymi, lasami losowymi, maszynami wektorów nośnych i sieciami neuronowymi. Dla układów dwukubitowych PGM osiąga zrównoważoną dokładność powyżej 90 procent, bliską najlepszym modelom neuronowym i jądrowym. W zadaniach trzykubitowych, gdzie struktura korelacji staje się bogatsza i subtelniejsza, PGM utrzymuje lub nawet poprawia swoją względną wydajność, ponownie dorównując czołowym technikom klasycznym. Gdy autorzy doprecyzowują zadanie, aby rozróżnić kilka różnych odmian stanów rozdzielnych trzech kubitów, problem staje się trudniejszy dla wszystkich metod. Nawet wtedy PGM pozostaje konkurencyjny: wyłapuje główne wzorce, ale podobnie jak inne klasyfikatory, od czasu do czasu myli ściśle powiązane klasy, których statystyczne sygnatury naturalnie się pokrywają.
Co to oznacza dla przyszłych narzędzi kwantowych
Dla osoby niezwiązanej ze specjalistyczną dziedziną główne przesłanie jest takie: istnieje zasadniczy sposób, by zasady fizyki kwantowej kierowały tym, jak uczymy maszyny rozpoznawania zasobów kwantowych — bez konieczności dostępu do rzeczywistego komputera kwantowego. Klasyfikator Pretty-Good-Measurement dostarcza przejrzystej, fizycznie ugruntowanej recepty na sortowanie zaszumionych stanów kwantowych według rodzaju przechowywanych korelacji. Działa porównywalnie z zaawansowanymi czarnymi skrzynkami, oferując jednocześnie jaśniejsze powiązania z mierzalnymi wielkościami i potencjalne ścieżki do implementacji sprzętowej. W miarę jak urządzenia kwantowe rosną w rozmiarze i złożoności, takie kwantowo zainspirowane, a jednocześnie klasyczne narzędzia mogą stać się cennymi roboczymi narzędziami do benchmarkingu, diagnozowania i w efekcie wykorzystywania splątania w realistycznych, niedoskonałych warunkach.
Cytowanie: Sergioli, G., Cuccu, C., Rieger, C.S. et al. A quantum-inspired classification for random mixed states. Sci Rep 16, 10668 (2026). https://doi.org/10.1038/s41598-026-44068-5
Słowa kluczowe: splątanie kwantowe, kwantowe uczenie maszynowe, stany kwantowe mieszane, klasyfikacja stanów kwantowych, pretty good measurement