Clear Sky Science · pl
Człowiek kontra sztuczna inteligencja: badanie umiejętności młodych naukowców z instytucji badawczych i niebadawczych w rozpoznawaniu streszczeń badań stomatologicznych wygenerowanych przez ChatGPT
Dlaczego to badanie ma znaczenie dla czytelników
W miarę jak narzędzia takie jak ChatGPT szybko trafiają do sal wykładowych i laboratoriów badawczych, wiele osób zadaje proste pytanie: czy potrafimy odróżnić, kiedy komputer napisał coś, co wygląda naukowo? To badanie przygląda się temu problemowi w bardzo praktycznym kontekście — badaniach stomatologicznych — i sprawdza, czy młodzi wykładowcy akademiccy potrafią wykryć streszczenia badań napisane przez AI oraz jak ich umiejętności wypadają na tle wyspecjalizowanego oprogramowania do wykrywania AI.
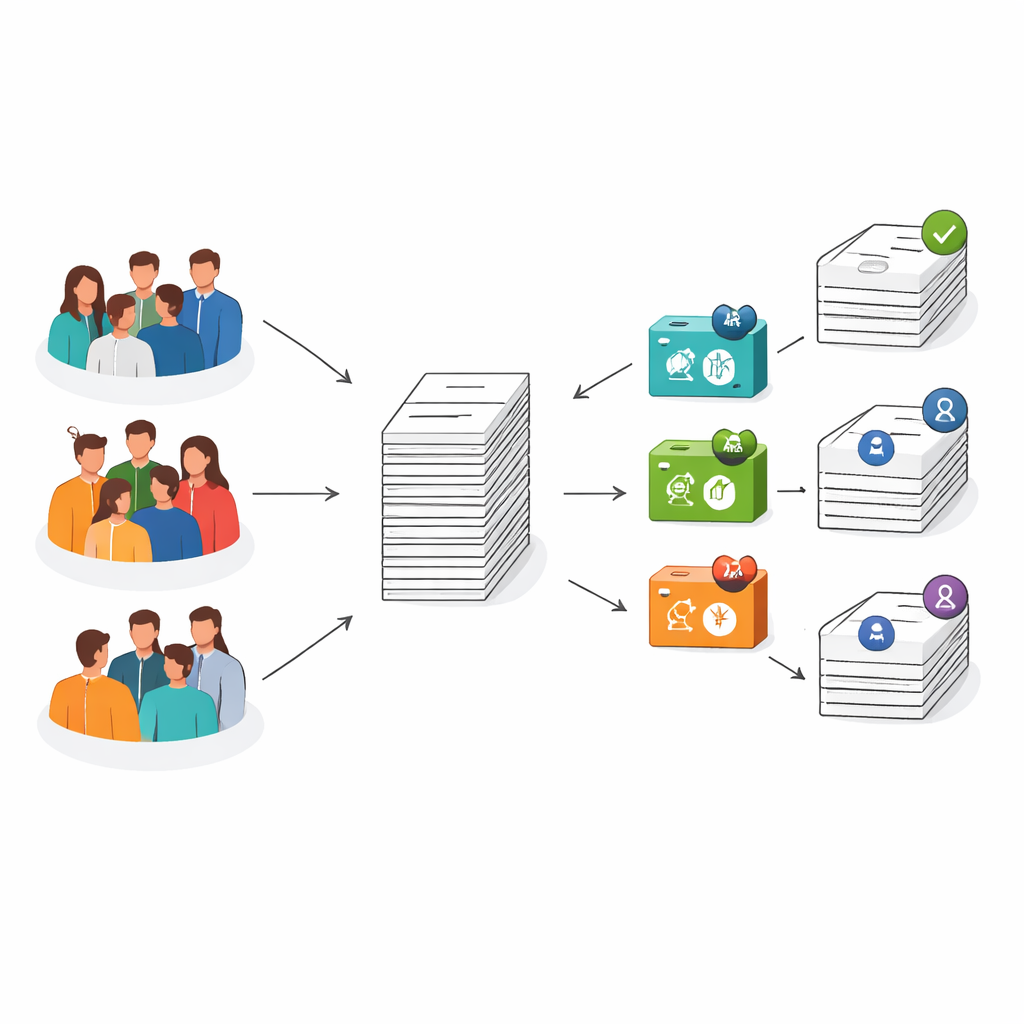
Postawienie ludzi i maszyn na próbę
Badacze skupili się na bardzo konkretnym i istotnym fragmencie pisania naukowego: streszczeniu, krótkim podsumowaniu na początku artykułu naukowego, które większość czytelników widzi jako pierwsze. Zebrali 75 prawdziwych streszczeń z wiodących czasopism stomatologicznych, a następnie poprosili ChatGPT o napisanie 75 nowych streszczeń na podstawie tych samych tytułów. Powstała pula 150 tekstów — połowa napisana przez ludzi, połowa wygenerowana przez AI — które wyglądały jak autentyczne streszczenia badań, choć ich pochodzenie było niewidoczne dla oceniających.
Młodzi naukowcy na „gorącym krześle”
Do badania zrekrutowano sześciu początkujących akademików z dziedziny stomatologii, każdy z mniej niż dwuletnim doświadczeniem dydaktycznym i badawczym, z sześciu uniwersytetów w Malezji — trzech państwowych uczelni badawczych oraz trzech prywatnych instytucji bez orientacji badawczej. Każdy uczestnik otrzymał mieszankę prawdziwych i wygenerowanych przez AI streszczeń, pozbawionych nazw czasopism i danych autorów, tak aby pozostało jedynie brzmienie tekstu. Poproszono ich o decyzję, czy każde streszczenie jest napisane przez człowieka czy AI, oraz o ocenę jego jakości za pomocą prostego arkusza ocen oceniającego jasność, spójność, kreatywność, głębię zrozumienia, gramatykę, użycie terminologii technicznej i znajomość dziedziny.
Jak oprogramowanie ocenia te same teksty
Te same 150 streszczeń oceniono następnie za pomocą trzech różnych detektorów tekstów generowanych przez AI oraz powszechnie stosowanego narzędzia do sprawdzania podobieństwa. Detektory AI szacują, jak prawdopodobne jest, że tekst pochodzi z systemu takiego jak ChatGPT, podczas gdy narzędzie do sprawdzania podobieństwa (Turnitin) porównuje tekst z ogromnymi bazami istniejących materiałów, aby ustalić stopień zgodności. Razem te narzędzia reprezentują cyfrowe zabezpieczenia, na które uczelnie zaczynają polegać w celu ochrony integralności akademickiej wraz z rosnącym użyciem pisania wspomaganego przez AI.
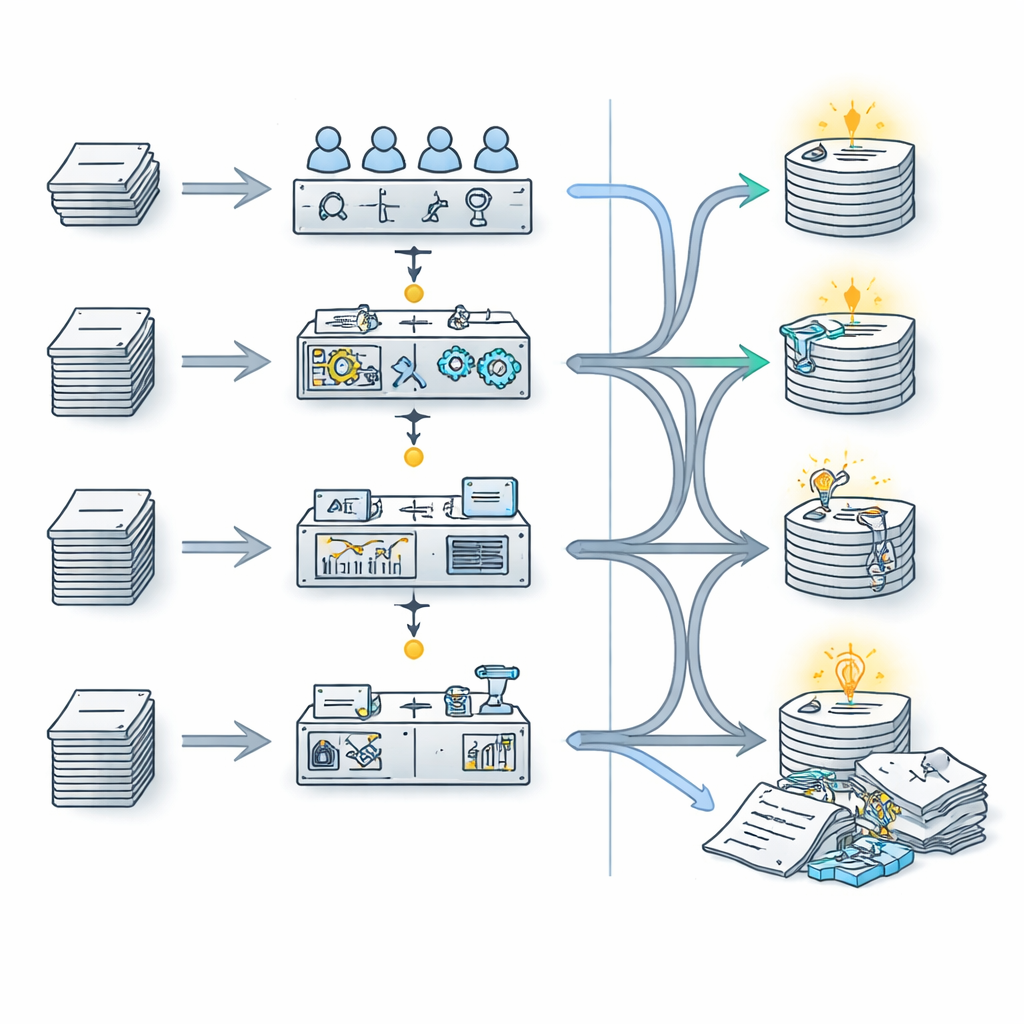
Kto wypadł lepiej — ludzie czy maszyny?
Młodzi naukowcy mieli więcej trudności, niż można by się spodziewać. Ich skuteczność w rozróżnianiu streszczeń napisanych przez ludzi i AI wahała się od 44% do 76% — w niektórych przypadkach niewiele lepiej niż przemyślane losowanie. Recenzenci z uczelni intensywnie prowadzących badania nie wypadają jednoznacznie lepiej niż ci z prywatnych uczelni skoncentrowanych na nauczaniu; większe znaczenie miały indywidualne różnice niż typ instytucji. Co ciekawe, oceniając jakość, recenzenci mieli tendencję do oceniania prawdziwych streszczeń jako dobrych do doskonałych, a streszczeń wygenerowanych przez AI jako przeważnie przeciętne, co sugeruje, że potrafili wyczuć różnice w głębi i niuansach, nawet gdy błędnie przypisywali autorstwo.
Detektory, które przewyższyły swoich ludzkich użytkowników
Oprogramowanie, a zwłaszcza narzędzie o nazwie GPTZero, okazało się bardziej niezawodne w rozróżnianiu tekstów ludzkich i generowanych przez AI. GPTZero prawidłowo sklasyfikowało około dziewięciu na dziesięć streszczeń, znacznie lepiej niż recenzenci i lepiej niż dwa pozostałe testowane detektory AI. Narzędzie do sprawdzania podobieństwa również wypadło mocno: prawie wszystkie prawdziwe streszczenia wykazywały bardzo wysokie podobieństwo do istniejących źródeł (jako że były to opublikowane prace), podczas gdy streszczenia generowane przez AI miały zwykle niskie do umiarkowanego podobieństwo, co odzwierciedla zdolność ChatGPT do parafrazowania, a nie kopiowania. Razem te narzędzia pokazały, że automatyczne wykrywanie może obecnie przewyższać nieuprzedzone ocenianie ludzkie, przynajmniej w przypadku młodych akademików czytających teksty techniczne.
Co to oznacza dla edukacji i badań
Dla laików kluczowy wniosek jest taki, że nawet wyszkoleni młodzi naukowcy mają trudności z niezawodnym rozpoznaniem dopracowanych streszczeń badań napisanych przez AI jedynie na podstawie ich lektury, a ich przynależność instytucjonalna — czy to uczelnia badawcza, czy nie — nie gwarantuje lepszej intuicji. Jednocześnie niektóre narzędzia wykrywania już dziś radzą sobie zaskakująco dobrze, choć nie są doskonałe i ich skuteczność może się zmieniać wraz z rozwojem systemów AI. Autorzy wnioskują, że uczelnie nie powinny polegać wyłącznie na ludzkim osądzie ani na jednym detektorze. Zamiast tego proponują podejście złożone: lepsze szkolenia z zakresu alfabetyzacji AI dla młodych pracowników, przemyślane stosowanie wielu narzędzi wykrywających oraz jasne wytyczne etyczne, tak aby kompetencje ludzkie i sztuczna inteligencja działały razem na rzecz wiarygodności pisania naukowego.
Cytowanie: AL-Rawas, M., Abdul Qader, O.A.J., Lin, G.S.S. et al. Human versus artificial intelligence: investigating ability of young academics from research and non-research institutions to identify ChatGPT-generated dental research abstracts. Sci Rep 16, 12287 (2026). https://doi.org/10.1038/s41598-026-42555-3
Słowa kluczowe: ChatGPT, uczciwość akademicka, wykrywanie AI, badania stomatologiczne, młodzi naukowcy