Clear Sky Science · fr
Humain contre intelligence artificielle : étude de la capacité de jeunes universitaires d’établissements de recherche et non-recherche à identifier des résumés de recherche dentaire générés par ChatGPT
Pourquoi cette étude intéresse le grand public
À mesure que des outils comme ChatGPT pénètrent rapidement les salles de classe et les laboratoires, beaucoup se posent une question simple : peut-on vraiment reconnaître quand un ordinateur a rédigé quelque chose qui a l’air scientifique ? Cette étude se penche sur ce problème dans un contexte très concret — la recherche dentaire — et teste si de jeunes enseignants-chercheurs sont capables de repérer des résumés de recherche écrits par une IA, et comment leurs compétences se comparent à celles de logiciels spécialisés de détection d’IA.
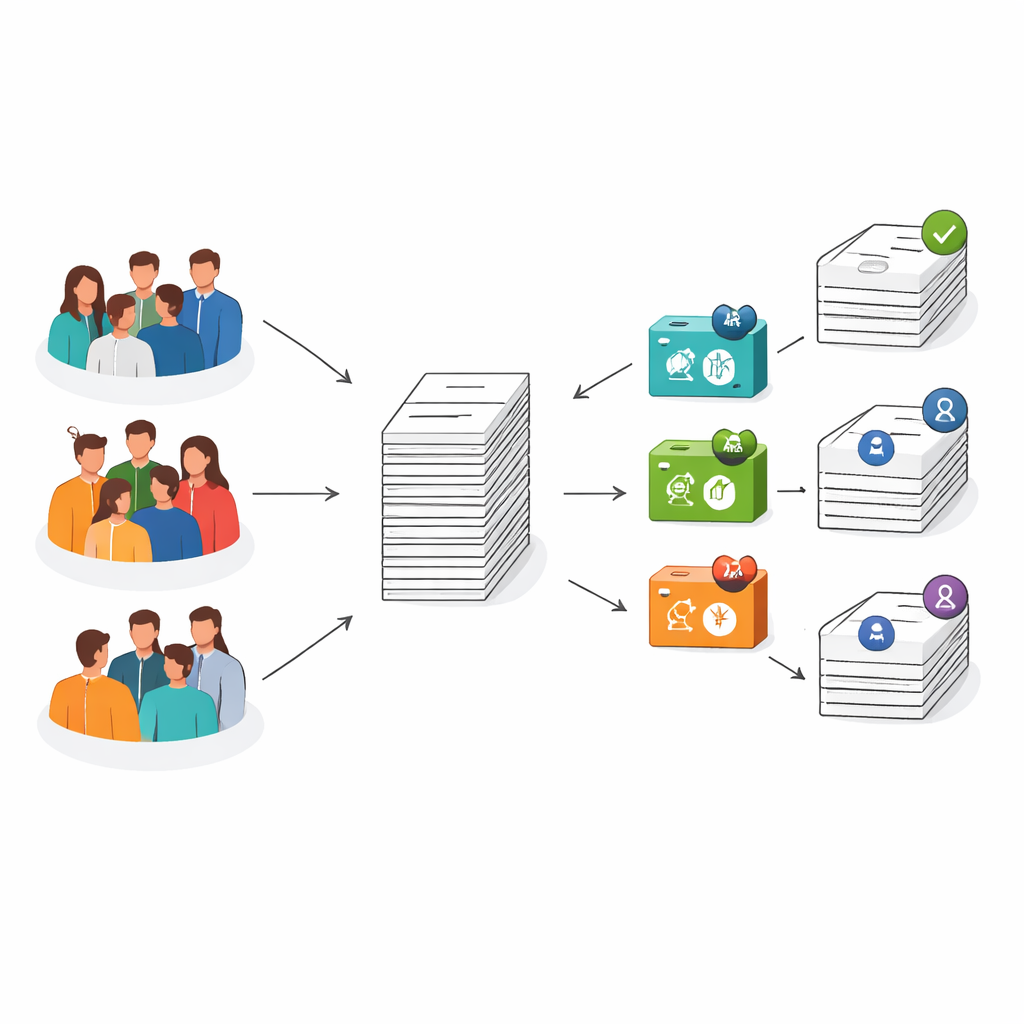
Mettre en concurrence humains et machines
Les chercheurs se sont concentrés sur une forme d’écriture scientifique très précise et importante : le résumé (abstract), le court condensé en tête d’un article que la plupart des lecteurs consultent en premier. Ils ont rassemblé 75 résumés réels de revues dentaires de premier plan, puis ont demandé à ChatGPT de rédiger 75 nouveaux résumés à partir des mêmes titres. Cela a produit un corpus de 150 textes — moitié rédigés par des humains, moitié générés par l’IA — qui avaient l’apparence de véritables résumés mais différaient par leur origine, information cachée aux évaluateurs.
Jeunes universitaires sous examen
Six jeunes universitaires en dentisterie, tous ayant moins de deux ans d’expérience d’enseignement et de recherche, ont été recrutés dans six universités de Malaisie — trois universités publiques axées sur la recherche et trois établissements privés sans orientation recherche. Chaque participant a reçu un mélange de résumés réels et générés par l’IA, dépouillés de tout nom de revue ou d’auteur pour ne laisser que le texte. Ils devaient décider si chaque résumé était rédigé par un humain ou par une IA, et noter sa qualité à l’aide d’une grille simple évaluant clarté, enchaînement, créativité, profondeur de compréhension, grammaire, usage du vocabulaire technique et connaissances spécifiques au domaine.
Comment les logiciels évaluent les mêmes textes
Les mêmes 150 résumés ont ensuite été évalués par trois détecteurs d’IA différents et par un vérificateur de similitude largement utilisé. Les détecteurs d’IA estiment la probabilité qu’un texte provienne d’un système comme ChatGPT, tandis que le vérificateur de similitude (Turnitin) compare le texte à d’immenses bases de données d’écrits existants pour en mesurer la proximité. Ensemble, ces outils représentent les garde-fous numériques sur lesquels les universités commencent à s’appuyer pour protéger l’intégrité académique à l’ère de l’écriture assistée par IA.
Qui s’en est le mieux sorti, humains ou machines ?
Les jeunes universitaires ont éprouvé plus de difficultés qu’ils ne l’auraient peut‑être imaginé. Leur taux de réussite pour identifier si un résumé était humain ou généré par une IA variait de 44 % à 76 % — parfois guère mieux qu’un pari réfléchi. Les évaluateurs issus d’universités axées sur la recherche ne surpassaient pas nettement ceux d’établissements privés orientés enseignement ; les différences individuelles pesaient plus que le type d’institution. Fait intéressant, lorsqu’ils notaient la qualité, les évaluateurs avaient tendance à classer les résumés réels de bons à excellents et les résumés d’IA plutôt moyens, ce qui suggère qu’ils percevaient des différences de profondeur et de nuance même lorsqu’ils se trompaient sur l’auteur.
Détecteurs supérieurs à leurs utilisateurs humains
Les logiciels, en particulier un outil nommé GPTZero, se sont révélés plus fiables pour distinguer écriture humaine et écriture générée. GPTZero a correctement classé environ neuf résumés sur dix, bien mieux que les évaluateurs humains et mieux que les deux autres détecteurs testés. Le vérificateur de similitude a également bien performé : presque tous les résumés réels présentaient une très forte similitude avec des sources existantes (étant donné qu’il s’agissait d’œuvres publiées), tandis que les résumés générés par l’IA affichaient une similitude faible à modérée, reflétant la capacité de ChatGPT à reformuler plutôt qu’à copier. Ensemble, ces outils montrent que la détection automatisée peut actuellement dépasser le jugement humain non assisté, du moins chez de jeunes universitaires confrontés à des textes techniques.
Ce que cela signifie pour l’éducation et la recherche
Pour les non-spécialistes, le message clé est que même des jeunes universitaires formés ont du mal à repérer de manière fiable des résumés de recherche polis écrits par une IA uniquement à la lecture, et que le contexte institutionnel — axé sur la recherche ou non — n’assure pas forcément de meilleurs instincts. En revanche, certains outils de détection font déjà un travail étonnamment bon, bien qu’ils ne soient pas parfaits et que leur précision puisse évoluer avec les systèmes d’IA. Les auteurs concluent que les universités ne devraient pas compter uniquement sur le jugement humain ni sur un détecteur unique. Ils recommandent plutôt une approche combinée : renforcer la formation à la littératie en IA pour les jeunes enseignants-chercheurs, utiliser judicieusement plusieurs outils de détection et établir des lignes directrices éthiques claires afin que l’expertise humaine et l’intelligence artificielle œuvrent de concert pour préserver la fiabilité de l’écriture scientifique.
Citation: AL-Rawas, M., Abdul Qader, O.A.J., Lin, G.S.S. et al. Human versus artificial intelligence: investigating ability of young academics from research and non-research institutions to identify ChatGPT-generated dental research abstracts. Sci Rep 16, 12287 (2026). https://doi.org/10.1038/s41598-026-42555-3
Mots-clés: ChatGPT, intégrité académique, détection d’IA, recherche dentaire, jeunes chercheurs