Clear Sky Science · pl
Badanie przenoszalności międzyregionowej i międzyzmiennowej metody super-rozdzielczości opartej na ResNet dla danych ERA5
Dlaczego ostrzejsze mapy pogodowe mają znaczenie
Prognozy pogody, mapy ryzyka klimatycznego i ostrzeżenia przed falami upałów opierają się na danych siatkowych o temperaturze, wietrze i ciśnieniu. Te dane bywają jednak zbyt grube, by ukazać, co dzieje się w konkretnym mieście, wzdłuż wybrzeża czy w dolinie, a tradycyjne metody ich wyostrzania są powolne i kosztowne. Badanie pokazuje, jak współczesna technika sztucznej inteligencji potrafi znacznie szybciej przekształcić rozmyte globalne dane pogodowe w bardziej szczegółowe pola — i co ważne, jak pojedynczy wytrenowany model można ponownie wykorzystać w różnych częściach świata, a nawet dla różnych zmiennych pogodowych, zmniejszając zarówno koszty obliczeniowe, jak i zapotrzebowanie na dane.
Z rozmytych siatek do drobniejszych szczegółów
Większość globalnych informacji pogodowych i klimatycznych pochodzi z produktów reanalizy, takich jak zestaw danych ERA5, które łączą obserwacje z modelami opartymi na prawach fizyki. Dane te są siatkowane w przybliżeniu co 25 kilometrów — wystarczająco gęste dla wzorców o dużej skali, lecz zbyt rzadkie dla lokalnych detali. Naukowcy tradycyjnie wypełniali luki lub zwiększali rozdzielczość metodami asimilacji danych lub interpolacji. Choć skuteczne, techniki te wymagają dużej mocy obliczeniowej i muszą być wykonywane osobno dla każdego regionu i zmiennej. Autorzy proponują alternatywę: model uczenia głębokiego oparty na sieci rezydualnej (ResNet) połączonej z modułem „sub-pixel” zaprojektowanym specjalnie do rekonstruowania brakującej struktury drobnej skali — zadania zwanego super-rozdzielczością. 
Wytrenować AI raz, używać wiele razy
Główne pytanie brzmi, czy model super-rozdzielczości wytrenowany w jednym miejscu można ponownie wykorzystać gdzie indziej, zamiast uczyć go od zera dla każdego przypadku. Zespół najpierw szkoli swój model ResNet na dużym obszarze obejmującym Azję Wschodnią, używając temperatury powietrza blisko powierzchni na wysokości dwóch metrów. Wejścia o niskiej rozdzielczości powstają przez celowe zgrubienie oryginalnych danych ERA5 przez czynniki dwa i cztery, a model uczy się rekonstruować oryginalne pola o wysokiej rozdzielczości. Po treningu ten sam model — bez dalszego dopasowywania — jest stosowany do 15 innych regionów rozmieszczonych na oceanach i kontynentach w strefach umiarkowanych, a ich wyjścia porównuje się z prawdziwymi polami ERA5 przy użyciu wielu miar błędu i podobieństwa.
Oceany są łatwiejsze, ląd trudniejszy
Wyniki pokazują, że umiejętność modelu rzeczywiście się przenosi: we wszystkich 16 regionach i na dwóch poziomach powiększenia rekonstrukcja AI jest konsekwentnie bliższa danym źródłowym niż standardowe metody interpolacyjne. Najlepsze wyniki osiągnięto nad otwartym oceanem, gdzie wzorce temperatury zmieniają się stopniowo, a środowisko jest stosunkowo jednorodne. Obszary obejmujące tylko powierzchnię morza wykazują najmniejsze błędy i największe podobieństwo do pól referencyjnych. Nad lądem, gdzie góry, wybrzeża i silne kontrasty dobowe wprowadzają ostre zmiany, wydajność spada nieco, lecz pozostaje użyteczna. Dłuższe średnie czasowe dodatkowo poprawiają zgodność, ponieważ drobne błędy momentu do momentu mają tendencję do się znoszenia przy uśrednianiu wielu godzin.
Jeden model dla wielu rodzajów danych pogodowych
Super-rozdzielczość nie dotyczy tylko temperatury. W drugim zestawie testów autorzy podają wstępnie wytrenowanemu modelowi inne zmienne ERA5 bliskie powierzchni dla wybranych regionów: ciśnienie na poziomie morza, dwie składowe poziomego wiatru oraz temperaturę punktu rosy, będącą miarą wilgotności. Pomimo że sieć nigdy nie była trenowana na tych zmiennych, potrafi je skutecznie wyostrzyć, często przewyższając solidną statystyczną bazę porównawczą znaną jako regresja Lasso. Wiatry są rekonstruowane szczególnie dobrze, podczas gdy ciśnienie i wilgotność są bardziej wrażliwe na lokalizację, zwłaszcza w pobliżu wybrzeży i urozmaiconego terenu, gdzie pola pogodowe mogą gwałtownie zmieniać się na krótkich dystansach. 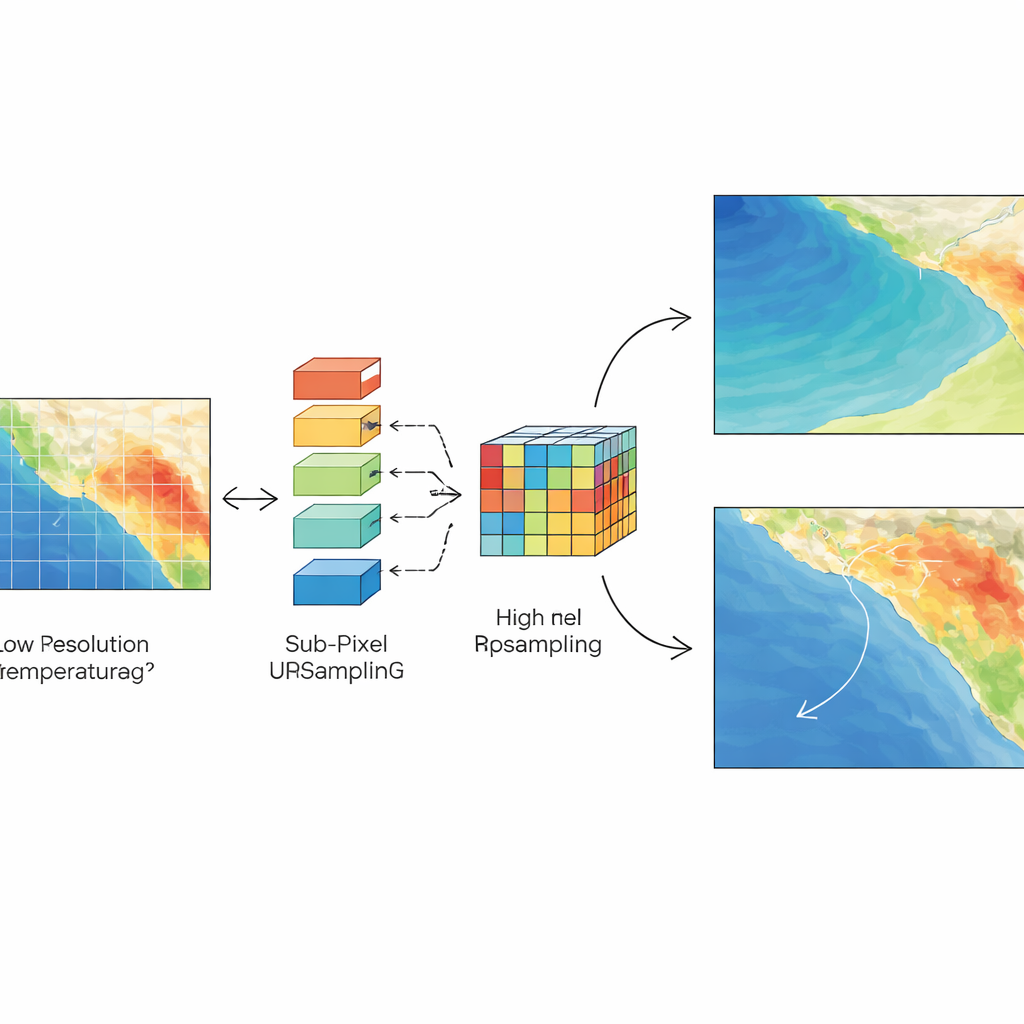
Testy modelu w ekstremalnych warunkach
Aby sprawdzić odporność, badanie analizuje również warunki ekstremalne, koncentrując się na kilku cyklonach tropikalnych nad Oceanem Spokojnym i Indyjskim. Nawet podczas tych intensywnych, szybko zmieniających się zdarzeń przeniesiony model nadal dodaje użyteczne drobne szczegóły do pól temperatury, wiatru, ciśnienia i wilgotności, choć z nieco większymi błędami niż w warunkach spokojnych. Regiony o prostych powierzchniach oceanicznych radzą sobie lepiej niż obszary złożone pod względem wybrzeża i rzeźby terenu, co podkreśla, że ostre zmiany wysokości i kontrast ląd–morze wciąż stanowią wyzwanie dla czysto danych napędzanych metod.
Co to oznacza dla przyszłych prognoz
Mówiąc prosto, badanie wykazuje, że model AI wytrenowany do wyostrzania danych pogodowych nad jedną częścią świata można ponownie użyć nad wieloma innymi obszarami i dla kilku powiązanych zmiennych bez konieczności ponownego treningu od zera. To ponowne użycie — znane jako uczenie transferowe — dostarcza dokładniejszych pól wysokiej rozdzielczości niż tradycyjna interpolacja, oszczędzając czas i zasoby obliczeniowe. Podejście jest szczególnie obiecujące dla regionów oceanicznych i zmiennych takich jak wiatry blisko powierzchni. Autorzy sugerują, że przyszłe prace mogą poprawić wydajność nad lądem, dostarczając modelowi dodatkowych informacji o ukształtowaniu terenu i granicach ląd–morze. Jeśli się to powiedzie, takie metody mogą uczynić szczegółowe, szybko aktualizowane produkty klimatyczne i pogodowe bardziej dostępnymi dla synoptyków, planistów i badaczy na całym świecie.
Cytowanie: Li, Z., Kong, H., Wong, C. et al. Exploring cross-regional and cross-variable transferability of a ResNet-based super-resolution method for the ERA5 data. Sci Rep 16, 10421 (2026). https://doi.org/10.1038/s41598-026-41002-7
Słowa kluczowe: dane klimatyczne, prognozowanie pogody, uczenie głębokie, super-rozdzielczość, uczenie transferowe