Clear Sky Science · pl
Zintegrowany fotoniczny silnik przetwarzania tensorów 3D
Dlaczego szybsze maszyny myślące mają znaczenie
Od samochodów autonomicznych po skanery medyczne i wirtualną rzeczywistość — nasz świat coraz bardziej opiera się na komputerach, które potrafią w czasie rzeczywistym rozumieć złożone dane trójwymiarowe. Dzisiejsze systemy sztucznej inteligencji są potężne, ale elektroniczne układy, które je napędzają, mają trudności z rosnącym zapotrzebowaniem na coraz większe i szybsze sieci neuronowe. W artykule przedstawiono nowy sposób obsługi danych 3D z użyciem światła zamiast elektryczności, obiecujący szybsze, bardziej efektywne „maszyny myślące”, które w przyszłości mogą zwiększyć bezpieczeństwo samochodów, przyspieszyć diagnozy i uczynić doświadczenia online bardziej immersyjnymi.
Od płaskich obrazów do światów 3D
Wiele znanych systemów AI działa na płaskich obrazach — dwuwymiarowych siatkach pikseli — wykorzystując tzw. splotowe sieci neuronowe. Jednak nowoczesne czujniki, takie jak skanery medyczne czy lidar laserowy w pojazdach autonomicznych, rejestrują pełne sceny 3D w czasie. Te bogatsze zestawy danych naturalnie opisuje się jako „tensory”, czyli wielowymiarowe tablice. Przetwarzanie ich za pomocą sieci 3D jest bardzo wydajne, lecz też niezwykle wymagające: ilość obliczeń i pamięci rośnie gwałtownie z każdą dodatkową wymiarowością. Konwencjonalne elektroniczne akceleratory, takie jak GPU i TPU, są głównie zaprojektowane do operacji macierzowych w dwóch wymiarach, więc muszą ciągle przekształcać i przestawiać dane 3D, tracąc czas, energię i pamięć.
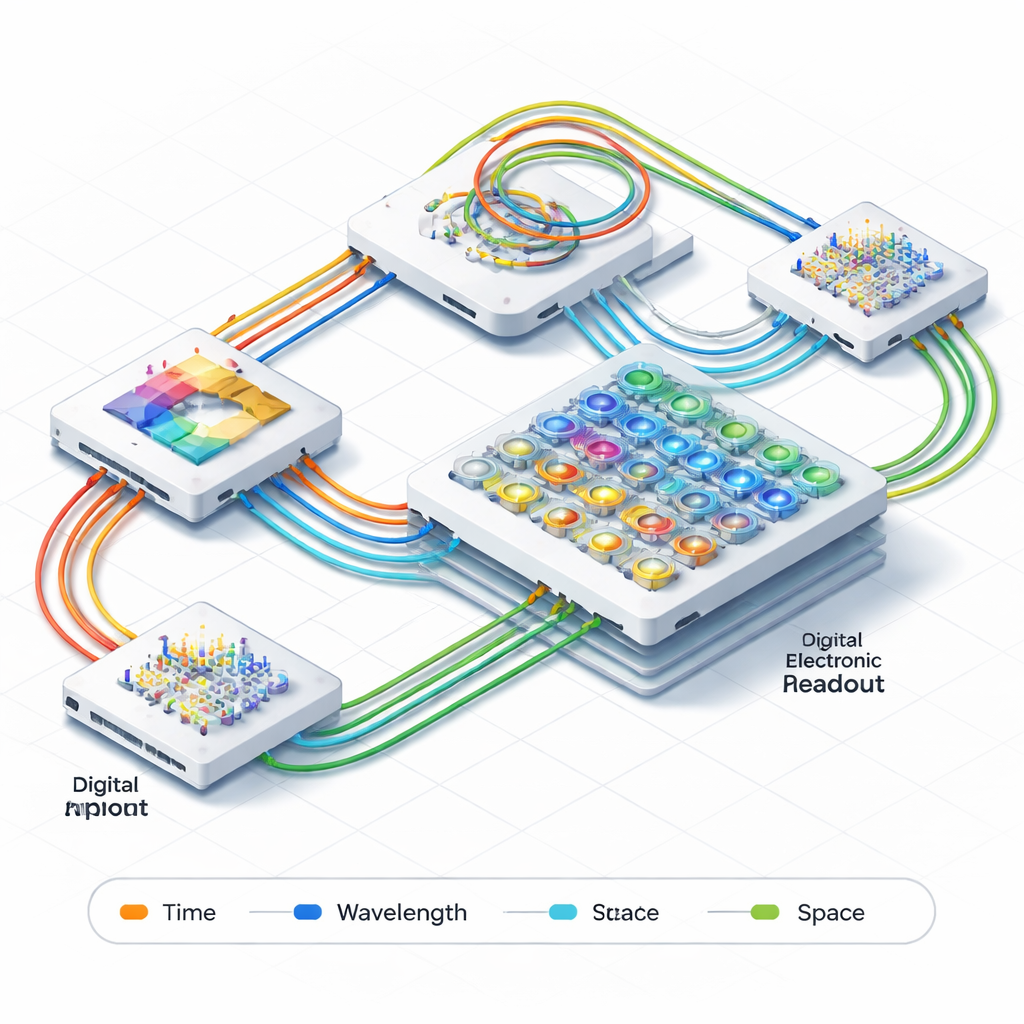
Niech to światło wykona ciężką pracę
Badacze przedstawiają zintegrowany fotoniczny silnik przetwarzania tensorów 3D, który wykonuje kluczowy etap sieci 3D bezpośrednio za pomocą światła. Zamiast wielokrotnie przenosić dane między pamięcią a procesorami elektronicznymi, ich system przesyła informacje jako sygnały optyczne płynące przez mikroskopijne falowody i rezonatory na chipie. Trzy różne „osi” służą do jednoczesnego kodowania i przetwarzania danych: barwa (długość fali) światła, czas przejścia impulsów oraz fizyczne ścieżki, jakie przebiegają po układzie. Poprzez przeplatanie tych trzech wymiarów system potrafi realizować pełne operacje splotu 3D bez dzielenia ich na wiele mniejszych zadań czy polegania na masywnej elektronicznej logice sterującej.
Wbudowana pamięć optyczna i synchronizacja
Centralnym wyzwaniem w szybkich obliczeniach jest utrzymanie precyzyjnego wyrównania w czasie wielu kanałów danych. Tradycyjne systemy używają złożonych układów zegarowych i dużych buforów pamięci do tego celu. Tutaj zespół rozwiązuje problem całkowicie w domenie optycznej. Dodają dwie jednostki pamięci optycznej wykonane jako strojonе linie opóźniające przed i za głównym blokiem obliczeniowym. Te linie opóźniające działają jak regulowane poczekalnie dla impulsów świetlnych, pozwalając systemowi „buforować” dane i synchronizować kanały poprzez prostą zmianę czasu, jaki każdy impuls pokonuje na chipie. Opóźnienia można precyzyjnie dostroić z dokładnością do pikosekund (bilionowych części sekundy) i obsługują efektywne częstotliwości taktowania rzędu około 200 miliardów operacji na sekundę, wszystko bez użycia dodatkowego elektronicznego sprzętu synchronizującego.
Inteligentniejsze obwody świetlne do ciężkiej matematyki
W sercu bloku obliczeniowego znajduje się siatka małych pierścieniowych rezonatorów optycznych, które kontrolują, jak mocno każdy kanał świetlny przyczynia się do wyniku — analogicznie do regulowanych wag w sieci neuronowej. Autorzy stosują specjalną konstrukcję z podwójnym pierścieniem na wielowarstwowej platformie fotonicznej, która sprawia, że elementy te są mniej wrażliwe na zmiany temperatury i niedokładności produkcyjne, oferując przy tym szeroką, płaską odpowiedź optyczną. Oznacza to, że pierścienie mogą obsługiwać szybkie sygnały z mniejszym zniekształceniem i utrzymywać precyzyjne ustawienia wag — lepsze niż równowartość 7 bitów efektywnej precyzji — przy prostym kalibrowaniu. W testach chip pomyślnie wykonał mnożenia macierzy czterokanałowych przy szybkościach symbolowych do 30 gigabaud, pokazując jednocześnie szybkość i dokładność.

Test w rzeczywistym świecie z użyciem laserowego pomiaru 3D
Aby pokazać, że ich silnik jest przydatny poza benchmarkami laboratoryjnymi, zespół zastosował go w praktycznym zadaniu rozpoznawania 3D: rozróżnianiu pieszych od pojazdów w chmurach punktów LiDAR. Użyli kompaktowej sieci 3D podobnej do znanych modeli czasu rzeczywistego, cyfrowo wytrenowali jej parametry, a następnie przenieśli kluczowy etap splotu 3D na silnik fotoniczny. Pracując przy szybkości symbolowej 20 gigabaud, system optyczny wygenerował mapy cech bardzo zbliżone do obliczeń cyfrowych i osiągnął dokładność klasyfikacji na poziomie około 97 procent — praktycznie taką samą jak tradycyjny komputer, ale przy wykonaniu ciężkiej matematyki 3D za pomocą światła.
Co to oznacza dla codziennej technologii
Mówiąc prosto, praca ta pokazuje, że można zbudować kompaktowy optyczny „silnik matematyczny”, który bezpośrednio zajmuje się najtrudniejszą częścią obciążeń AI 3D, używając przy tym mniej pamięci, mniejszej liczby komponentów elektronicznych i potencjalnie znacznie mniej energii niż obecne rozwiązania. Utrzymując buforowanie danych, wyrównanie czasowe i obliczenia w domenie optycznej, podejście redukuje złożoność i otwiera drogę do wyższych prędkości oraz większego stopnia równoległości. W miarę jak integracja fotoniczna się poprawia, a nachipowe źródła światła i wzmacniacze dojrzewają, takie silniki tensorowe 3D mogą stać się kluczowymi elementami przyszłych urządzeń dla autonomicznej jazdy, obrazowania medycznego, analizy wideo i immersyjnych środowisk wirtualnych — dyskretnie wykorzystując wiązki światła, by pomóc maszynom widzieć i rozumieć nasz trójwymiarowy świat w czasie rzeczywistym.
Cytowanie: Wu, Y., Ni, Z., Li, X. et al. Integrated photonic 3D tensor processing engine. Light Sci Appl 15, 154 (2026). https://doi.org/10.1038/s41377-026-02183-y
Słowa kluczowe: obliczenia fotoniczne, sieci neuronowe 3D, akceleratory optyczne, rozpoznawanie LiDAR, przetwarzanie tensorów