Clear Sky Science · nl
Uitgebreide evaluatie van cross-kanker generalisatie in histopathologische segmentatiemodellen over 21 tumortypes
Slimmere hulpmiddelen voor kankerdetectie
Pathologen die weefsel onder de microscoop bestuderen, vertrouwen steeds vaker op computerprogramma’s om kanker te herkennen en nauwkeurig te kwantificeren. Maar voor elk afzonderlijk kankertype een apart hulpmiddel bouwen vergt maanden van deskundig werk. Deze studie stelt een eenvoudige vraag met grote praktische gevolgen: kan een hoogwaardig model dat voor één kanker is getraind veilig hergebruikt worden voor vele andere, zodat tijd wordt bespaard en digitale hulpmiddelen sneller beschikbaar komen in de kliniek? 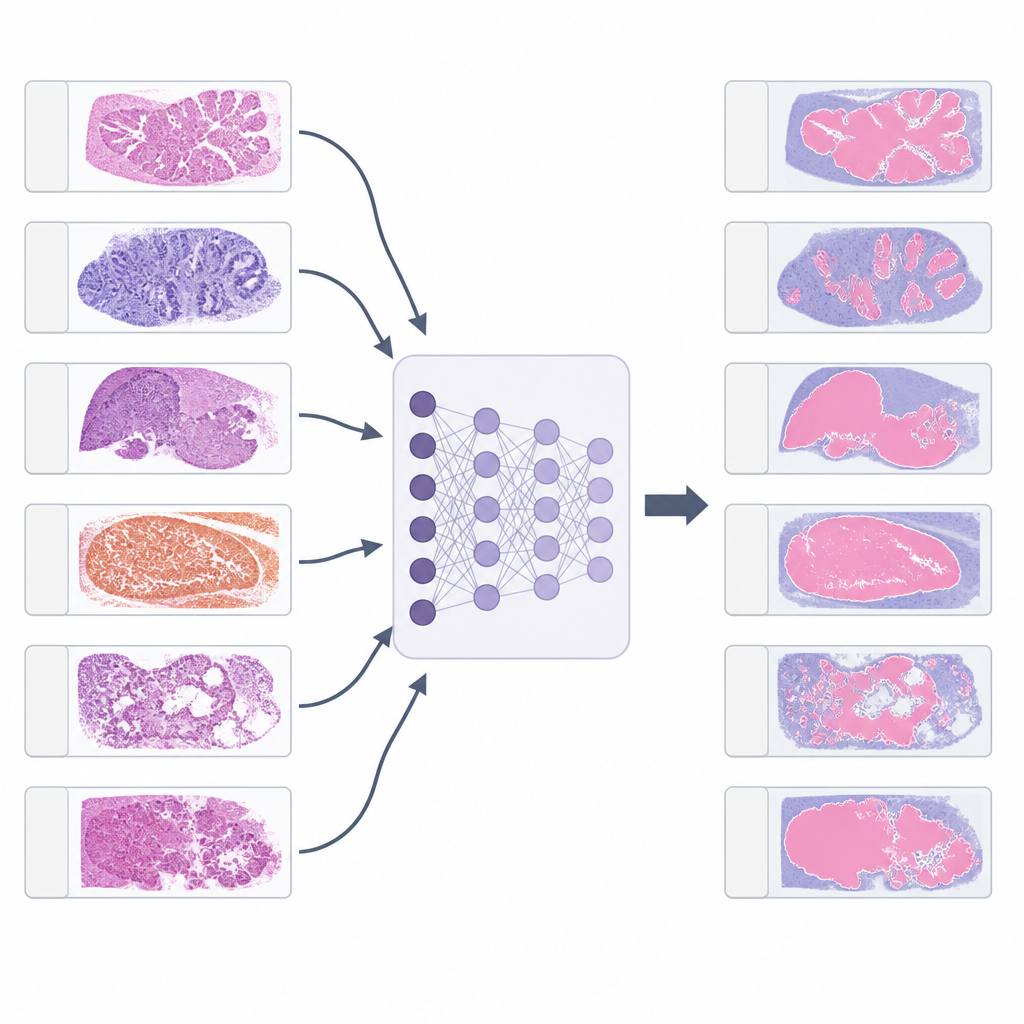
Waarom het markeren van kanker op objectglaasjes belangrijk is
Wanneer een patholoog naar een weefselslide kijkt, vraagt hij zich niet alleen af of er kanker aanwezig is. Hij tekent zorgvuldig de grenzen tussen tumor en gezond weefsel, beoordeelt de schikking van cellen en meet kenmerken zoals littekenachtig weefsel, necrotische gebieden en immuuncellen. Moderne kunstmatige intelligentie kan dit proces nabootsen door elke pixel van een slide te kleuren op basis van wat het bevat. Deze pixel-niveau kaarten ondersteunen onderzoek naar hoe tumoren groeien, helpen subtiele patronen te kwantificeren die mensen moeilijk kunnen meten en kunnen worden gebruikt in nieuwe tests die weefselstructuur koppelen aan genetische of medicijnresponsgegevens.
De uitdaging van één-model-per-kanker
Het maken van zulke gedetailleerde hulpmiddelen is traag en arbeidsintensief. Deskundigen moeten nauwkeurige contouren van tumor en omliggend weefsel tekenen op veel grote afbeeldingen, een taak die uren per geval kan vergen. Voor elk nieuw kankertype wordt meestal een nieuw model getraind en vervolgens jarenlang getest op veiligheid en nauwkeurigheid, vaak over meerdere ziekenhuizen. Met tientallen veelvoorkomende tumortypes wordt deze “één model per kanker”-aanpak een serieuze knelpunt. Het beperkt hoe snel kunstmatige intelligentie in de routinezorg kan worden gebracht en bemoeilijkt het bouwen van breed inzetbare systemen.
Testen of modellen grenzen tussen kankers kunnen oversteken
De onderzoekers namen vijf bestaande weefselsegmentatiemodellen, oorspronkelijk getraind voor borst-, darm-, long-, nier- en prostaatkanker. Ze pasten deze toe op meer dan 7.700 digitale slides van 21 verschillende tumortypes die door The Cancer Genome Atlas zijn verzameld. Voor elke slide selecteerde een patholoog één groot gebied rijk aan tumor en, indien mogelijk, één gebied met benigne weefsel. De modellen kleurden elke pixel in deze gebieden op basis van weefseltype. Pathologen scoorden vervolgens hoe goed elk model tumor scheidde van het ondersteunende weefsel op een eenvoudige schaal van 0 tot 10, waarbij hogere scores meer accurate contouren en minder gemiste structuren aangaven. 
Welke modellen het beste tussen kankers reisden
Het longkankermodel bleek het meest veelzijdig. Gemiddeld scoorde het ongeveer 8 van de 10 over alle tumortypes, en het bereikte “uitstekende” kwaliteit in meer dan de helft van de niet-longkankers die werden getest, waaronder eierstokkanker, galwegtumoren, schildklierkanker en verschillende kankers opgebouwd uit platte squameuze cellen. In veel van deze gevallen kwam de prestatie overeen met die op de oorspronkelijke longslides. Borst- en darmmodellen werkten ook goed voor veel andere kankers, zij het niet zo breed inzetbaar als het longmodel. Nier- en prostaatmodellen, getraind op meer specifiek gevormde tumoren, generaliseerden minder betrouwbaar, vooral voor kankers waarvan de cellen er onder de microscoop erg anders uitzien.
Patronen die goede generalisatie verklaren
De studie toonde aan dat succes of mislukking grotendeels overeenkwam met hoe vergelijkbaar de celvormen en groeipatronen tussen tumoren waren. Zo werkte het longmodel, dat zowel kliervormende als squameuze groei in longkankers had geleerd, goed op squameuze kankers van hoofd-hals, cervix en slokdarm. Het borstmodel, getraind om verspreide losse cellen te detecteren in een subtype genaamd invasief lobulair carcinoom, bleek effectief voor diffuus maagkanker dat bestaat uit vergelijkbare losse, kleine celclusters. Daarentegen waren tumoren met ongebruikelijke verschijningsvormen, zoals veel nierkankers en melanomen, moeilijker voor alle modellen. Desondanks produceerden de hulpmiddelen vaak nuttige contouren in benigne gebieden, zoals normale klieren of vroege voorstadia van kanker, die in toekomstig trainen hergebruikt zouden kunnen worden.
Snellere wegen naar nieuwe klinische hulpmiddelen
Aangezien meerdere modellen al goed presteren op kankers die ze tijdens training nooit hebben gezien, kunnen ze dienen als “starttools” in plaats van experts te dwingen alles vanaf nul te labelen. De auteurs schetsen praktische routes: een sterk model direct zonder retraining gebruiken voor bepaalde studies, de output als eerste versie laten corrigeren door pathologen, of oudere, grove datasets omzetten naar precieze pixelkaarten door patchlabels te combineren met deze segmentaties. In gunstige gevallen kan dit de tijd om een nieuw model te bouwen verkorten van meer dan een jaar tot minder dan een week. Voor patiënten kan dit betekenen dat accurate, verklaarbare AI de diagnostiek en biomarkerontdekking over veel kankers eerder en met minder dubbel werk ondersteunt.
Wat dit betekent voor toekomstige kankerzorg
Voor een niet-specialistische lezer is de hoofdboodschap dat hetzelfde slimme computerprogramma dat longtumoren traceert vaak kan worden hergebruikt om veel andere kankers te omlijnen zonder helemaal opnieuw te beginnen. Dit hergebruik verkort het traagste deel van modelontwikkeling, namelijk het zorgvuldig handmatig tekenen door experts, en helpt onderzoekers te focussen op het testen en verbeteren van hulpmiddelen in plaats van dezelfde patronen steeds opnieuw te tekenen. Als deze aanpak verder wordt ontwikkeld tot echte “all-cancer”-systemen, zouden zulke segmentatiemodellen een standaardlaag in digitale pathologie kunnen worden, die consistente kaarten van tumor en omliggend weefsel levert en zo bijdraagt aan betere studies, helderdere rapporten en uiteindelijk meer geïnformeerde klinische beslissingen.
Bronvermelding: Bedau, T., Harder, C., Al-Shughri, A. et al. Comprehensive evaluation of cross cancer generalization in histopathology segmentation models across 21 tumor types. Commun Med 6, 302 (2026). https://doi.org/10.1038/s43856-026-01601-x
Trefwoorden: computationele pathologie, kankersegmentatie, deep learning, digitale histologie, pan-kanker modellen