Clear Sky Science · nl
Machine learning-gebaseerde proteogenomische datamodellering identificeert circulerende plasmabiomarkers voor vroege opsporing van longkanker
Waarom dit onderzoek ertoe doet
Longkanker veroorzaakt wereldwijd meer sterfgevallen dan welke andere kanker dan ook, grotendeels omdat de ziekte meestal te laat wordt ontdekt. De huidige screeningsinstrumenten richten zich vooral op zware rokers en vertrouwen op beeldvorming die vroege ziekte kan missen. Deze studie stelt een eenvoudige maar krachtige vraag: kan een routinemonster bloed, verzameld jaren voordat symptomen verschijnen, onthullen wie in stilte richting longkanker beweegt? Door genetische gegevens te combineren met duizenden bloedproteïnen en moderne machine learning, zoeken de onderzoekers naar vroege waarschuwingssignalen die ooit de screening zouden kunnen verbreden en levens redden.
Op zoek naar aanwijzingen in genen en bloed
Het team bekeek eerst het DNA van honderden duizenden mensen in grote populatiebiobanken in het Verenigd Koninkrijk en Finland. Ze vergeleken de genetische codes van mensen die longkanker ontwikkelden met die van mensen die dat niet deden, en pinpointen DNA-streken die aan een hoger risico gekoppeld zijn. Vervolgens onderzochten ze of diezelfde genetische varianten verband hielden met veranderingen in specifieke eiwitten die in het bloed circuleren. Eiwitten zijn de werkpaardmoleculen van het lichaam, en verschuivingen in hun concentraties kunnen vroege biologische stress aantonen, lang voordat een tumor op een scan zichtbaar is. Door risicogenen te koppelen aan bloedproteïnelevels begonnen de onderzoekers in kaart te brengen hoe erfelijke gevoeligheid subtiel de interne chemie van het lichaam kan hervormen op weg naar longkanker.
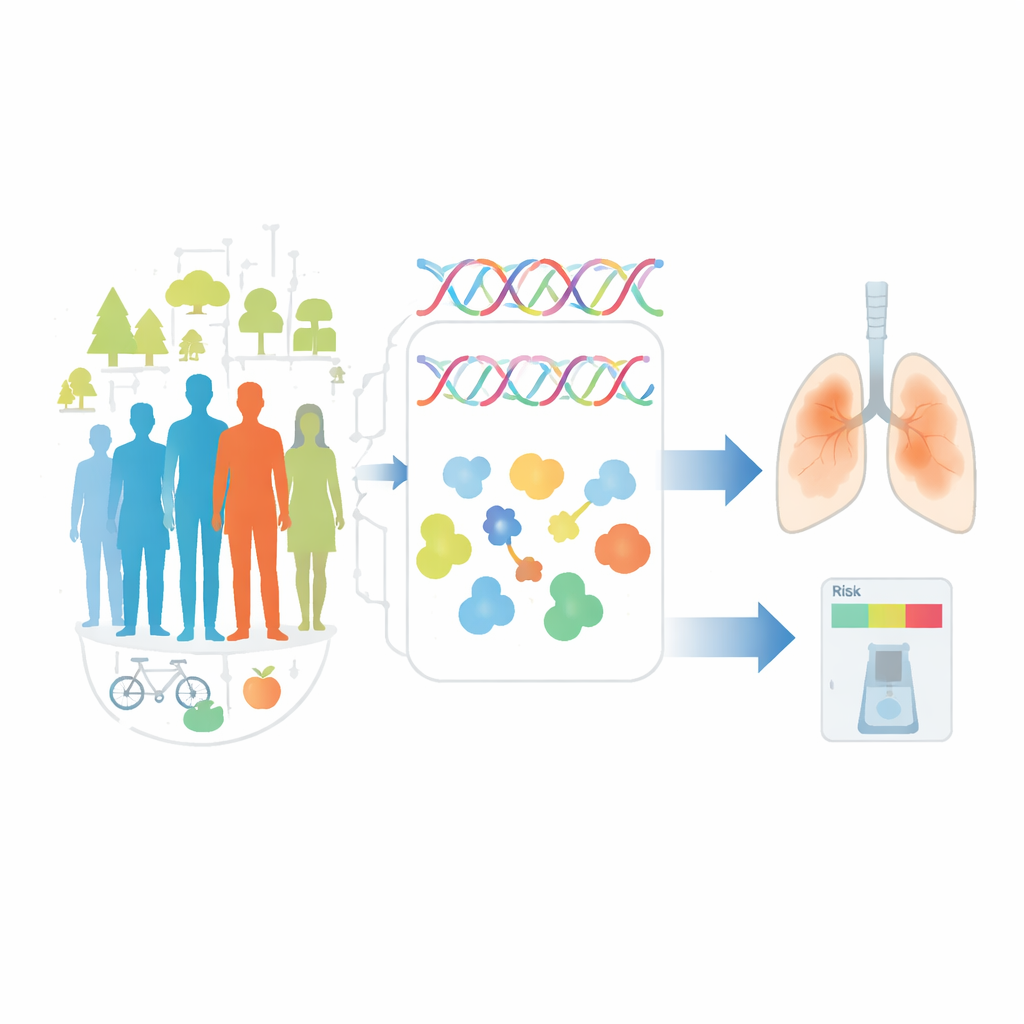
Bloedsignalen volgen jaren vóór diagnose
Het tweede, complementaire deel van de studie richtte zich direct op bloedproteïnen als mogelijke vroege signalen van ziekte. Met een high-throughput platform maten de onderzoekers bijna 3.000 verschillende eiwitten in bloedmonsters van meer dan 26.000 vrijwilligers uit de UK Biobank. Sommige mensen waren al gediagnosticeerd met longkanker toen hun bloed werd afgenomen, maar velen kregen de ziekte pas jaren later. De onderzoekers groepeerden deze “toekomstige patiënten” op basis van wanneer ze werden gediagnosticeerd: binnen 0–4 jaar, 5–9 jaar, of ergens binnen 0–9 jaar na het afnemen van het bloed. Ze vergeleken vervolgens de eiwitniveaus tussen elke groep en kankervrije deelnemers om eiwitten te vinden die consequent anders waren lang vóór de diagnose.
Computers trainen om hoogrisicoprofielen te herkennen
Aangezien geen enkel eiwit het hele verhaal vertelde, wendde het team zich tot machine learning om complexe patronen over honderden markers tegelijk te interpreteren. Ze trainden verschillende algoritmetypen — waaronder random forests en neurale netwerken — om mensen die later longkanker ontwikkelden te onderscheiden van degenen die kankervrij bleven, met alleen hun bloedproteïneprofielen als input. De modellen presteerden goed en bereikten nauwkeurigheidsscores (AUCs) van ongeveer 0,8–0,88, zelfs wanneer monsters tot negen jaar vóór diagnose waren genomen. Opvallend was dat modellen opgebouwd uit proteïnegegevens duidelijk beter presteerden dan modellen die alleen gebaseerd waren op standaardrisicofactoren zoals leeftijd, geslacht en rookgeschiedenis, wat aantoont dat de bloedsignalen zinvolle aanvullende informatie leveren naast wat artsen al weten.
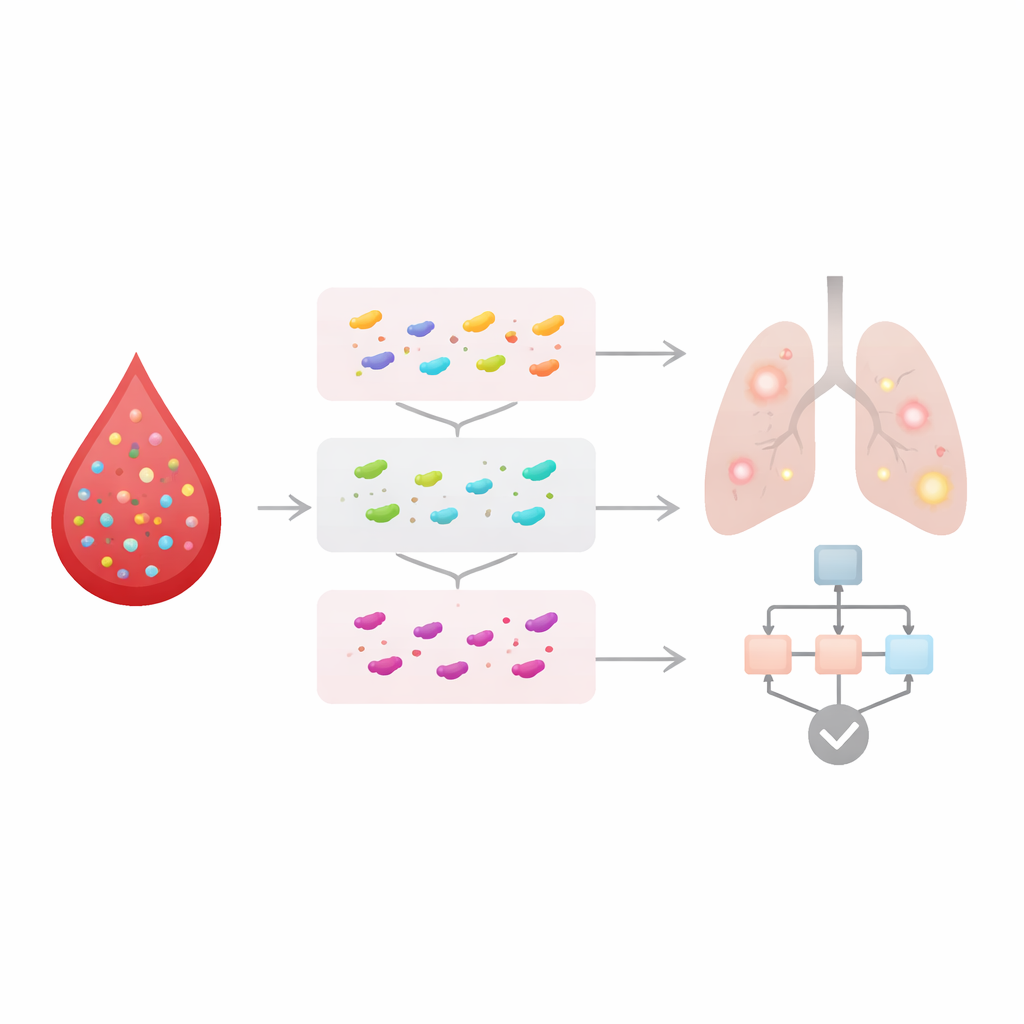
Wat de sleutelproteïnen onthullen
Over de verschillende tijdvensters heen identificeerden de onderzoekers herhaaldelijk een kernset van 22 eiwitten waarvan de niveaus sterk samenhingen met toekomstige longkanker. Veertien daarvan waren eerder al aan longkanker gekoppeld, terwijl acht als nieuwe kandidaten naar voren kwamen. Veel van de eiwitten zijn betrokken bij immuunreacties, ontsteking en littekenvorming in longweefsel, wat suggereert dat vroege longkanker het afweersysteem van het lichaam kan hervormen lang voordat het op beeldvorming zichtbaar is. Bij mensen van wie het bloed 5–9 jaar vóór diagnose werd afgenomen, gingen hogere niveaus van meerdere eiwitten ook samen met slechtere overleving zodra de kanker zichtbaar werd, wat suggereert dat diezelfde vroege markers informatie kunnen dragen over hoe agressief een toekomstige tumor mogelijk zal zijn.
Wat dit betekent voor patiënten
Dit werk levert nog geen kant-en-klare bloedtest op, en het bewijst niet dat deze eiwitten longkanker veroorzaken. In plaats daarvan biedt het een gedetailleerde kaart van hoe genen en bloedchemie veranderen in de jaren vóór diagnose, en licht het specifieke circulerende eiwitten uit die nader onderzoek verdienen als vroege waarschuwingsmarkers. Als vervolgonderzoek deze bevindingen bevestigt en verfijnt, zou een eenvoudige bloedafname op een dag kunnen helpen hoogrisicopersonen — inclusief sommige levenslange niet-rokers — jaren vóór het ontstaan van symptomen te identificeren, wat kan leiden tot gerichtere scans, nauwere monitoring en uiteindelijk meer geredde levens.
Bronvermelding: Johnson, M.A., Nieves-Rodriguez, S., Hou, L. et al. Machine learning-based proteogenomic data modeling identifies circulating plasma biomarkers for early detection of lung cancer. Commun Med 6, 253 (2026). https://doi.org/10.1038/s43856-026-01500-1
Trefwoorden: longkanker, biomerkers in bloed, proteomica, genetisch risico, vroege opsporing