Clear Sky Science · nl
Machine learning-gebaseerde voorspelling van het aantal trombocyten uit ROTEM-metingen
Waarom snelle controles van bloedplaatjes belangrijk zijn
Wanneer iemand bloedt tijdens een operatie of op de intensivecare, moeten artsen snel beslissen of ze trombocytentransfusies geven om de bloedstolling te ondersteunen. Standaard laboratoriumtests kunnen trombocyten nauwkeurig tellen, maar duren vaak een uur of langer, wat dringende beslissingen vertraagt. Bedzijde-apparaten die in real time volgen hoe een stolsel vormt zijn veel sneller, maar tonen niet rechtstreeks hoeveel trombocyten er in het bloed zitten. Deze studie onderzoekt of computermodellen die snelle bedzijde-metingen kunnen vertalen naar betrouwbare informatie over gevaarlijk lage trombocytenniveaus.
Een korte blik op stolling in real time
Moderne point-of-care-tests zoals rotational thromboelastometry, of ROTEM, volgen hoe een bloedmonster stolt vanaf het eerste begin van stolling tot het punt waarop het stolsel stevig wordt en later afbreekt. Deze tests leveren curven en cijfers die weerspiegelen hoe sterk en stabiel het stolsel wordt, maar niet het werkelijke aantal trombocyten. Eerder onderzoek toonde aan dat sommige ROTEM-waarden gerelateerd zijn aan trombocytenniveaus, maar eenvoudige formules die één enkele ROTEM-waarde gebruiken voorspelden de trombocytenaantallen niet goed genoeg om behandeling te sturen. De auteurs vroegen zich af of meer geavanceerde computermethoden die veel ROTEM-kenmerken tegelijk meenemen, het beter zouden doen.
Computermodellen bouwen met ziekenhuisdata
Het team verzamelde 2.333 gekoppelde bloedtesten uit vier universitaire ziekenhuizen, allemaal afgenomen bij operatie- of intensivecarepatiënten tussen 2014 en 2023. Voor elk geval hadden ze een volledige set ROTEM-metingen en een laboratoriumtrombocytenaantal dat binnen drie uur was bepaald. Na zorgvuldige schoonmaak van de data en het invullen van ontbrekende waarden voerden ze 29 ROTEM-gerelateerde variabelen in verschillende machine learning-methoden. Sommige modellen probeerden de exacte trombocytenconcentratie te voorspellen, terwijl andere eenvoudigere vragen aanpakte: ligt het trombocytenaantal onder 100 miljard per liter, of onder 50 miljard per liter — niveaus die veelal als veiligheidsdrempels in chirurgie en kritisch bloedverlies worden gebruikt.
Hoe goed de modellen trombocyten konden schatten
Wanneer de modellen werd gevraagd het exacte trombocytenaantal te schatten, versloegen alle machine learning-modellen de oudere eendimensionale formules die op één ROTEM-waarde vertrouwden. De beste aanpak, een stacked ensemble-model dat meerdere methoden combineert, liet echter nog steeds slechts matige nauwkeurigheid zien. De voorspellingen weekten gemiddeld ongeveer 40 miljard trombocyten per liter af van het werkelijke aantal, wat de auteurs te onprecies achten voor betrouwbare doseringsbeslissingen. Grafieken die voorspelde en werkelijke tellingen vergelijken, evenals statistische controles op bias en spreiding, bevestigden dat de modellen vaak voor individuele patiënten de plank misslaan, ook al vangen ze brede trends op.
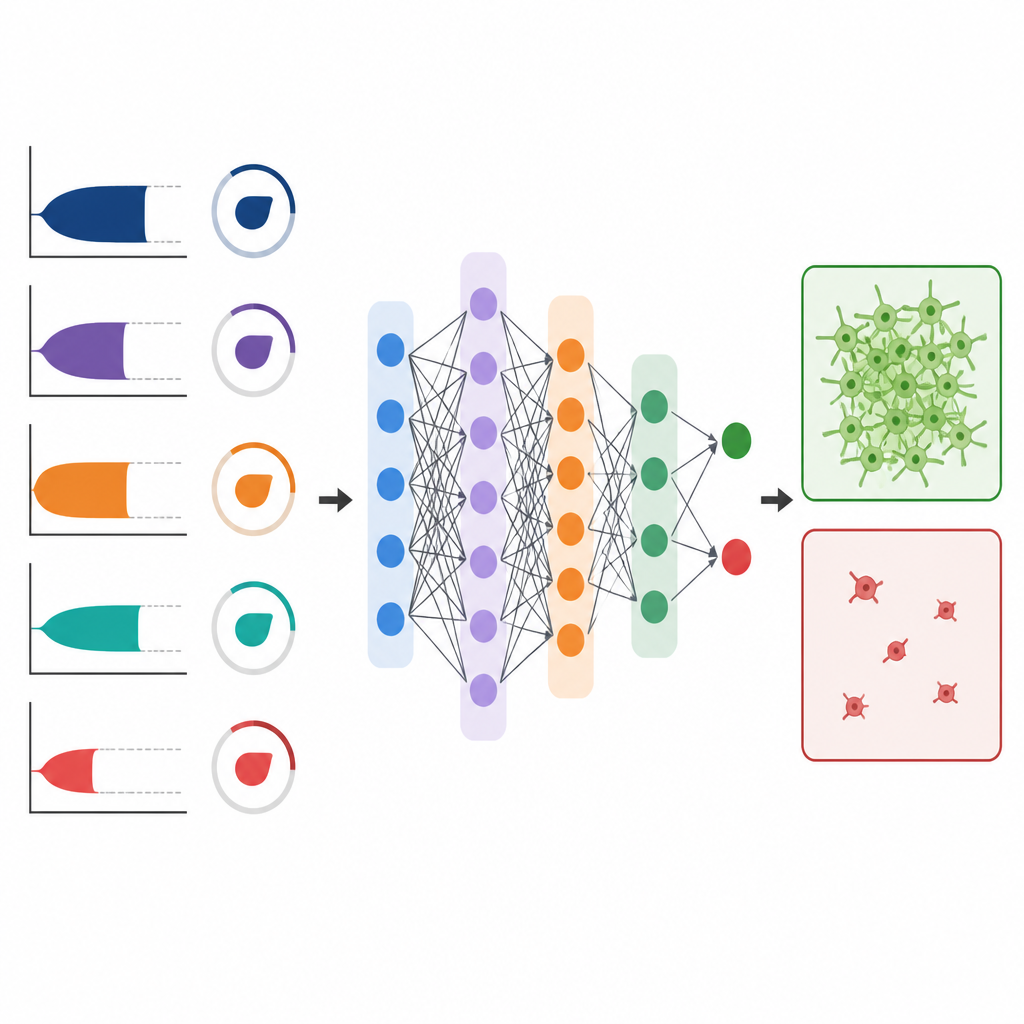
Gevaarlijk lage niveaus opsporen werkt beter
De modellen presteerden veel beter bij een eenvoudiger en klinisch cruciale taak: het signaleren van patiënten met duidelijk lage trombocytenaantallen. Voor het detecteren van aantallen onder 100 miljard per liter bereikten random forest- en ensemblemodellen hoge waarden voor een standaard maat voor testkwaliteit, de area under the curve. Ze waren vooral sterk in het uitsluiten van lage trombocyten, met zeer hoge waarschijnlijkheid dat een "veilig" resultaat daadwerkelijk betekende dat de patiënt boven de drempel lag. De prestaties waren nog beter voor detectie van aantallen onder 50 miljard per liter, waarbij opnieuw het ensemblemodel eruit sprong. Deze resultaten hielden stand over verschillende manieren om nauwkeurigheid te beoordelen en waren duidelijk superieur aan het vertrouwen op de enkele ROTEM-afgeleide waarde alleen.
Wat dit aan het bed kan betekenen
De auteurs concluderen dat huidige machine learning-modellen nog niet nauwkeurig genoeg zijn om een laboratoriumtrombocytentelling te vervangen, omdat hun schattingen van het exacte aantal te sterk variëren voor individuele patiënten. Tegelijkertijd zijn dezelfde modellen zeer goed in het beantwoorden van de ja/nee-vraag of trombocyten onder belangrijke veiligheidsdrempels zijn gezakt. In urgente bloedsituaties kan dergelijke snelle bedzijde-ondersteuning artsen helpen trombocytentransfusies veilig uit te stellen of te vermijden terwijl ze wachten op labuitslagen, waardoor zowel vertragingen in de zorg als onnodige blootstelling aan bloedproducten worden verminderd.
Bronvermelding: Brooks, R., Noitz, M., Mahečić, T.T. et al. Machine learning based prediction of platelet concentration from ROTEM measurements. Sci Rep 16, 15854 (2026). https://doi.org/10.1038/s41598-026-45743-3
Trefwoorden: trombocytenaantal, trombocytopenie, ROTEM, machine learning, trombocytentransfusie