Clear Sky Science · nl
Een effectieve, met AI verrijkte vraagvoorspellingsapplicatie voor de automobielreserveonderdelenindustrie: een casus uit Turkije
Waarom het raden van vraag naar reserveonderdelen ertoe doet
Wanneer een auto kapotgaat, verwachten bestuurders dat het juiste reserveonderdeel op voorraad ligt. Voor fabrikanten en servicewerkplaatsen is het een voortdurend balanceren: genoeg onderdelen hebben zonder magazijnen te vullen. Deze studie onderzoekt hoe slim gebruik van kunstmatige intelligentie bedrijven in de markt voor automobielreserveonderdelen kan helpen zeer onregelmatige vraag nauwkeuriger te voorspellen, waardoor kosten worden bespaard en klanten op weg blijven.
De uitdaging van stop-en-go vraag
Reserveonderdelen verkopen zich niet in een vloeiende, constante stroom. Veel artikelen liggen maandenlang zonder bestellingen en vertonen dan plotselinge vraagpieken. De auteurs noemen deze patronen intermitterende en klonterige vraag. In veel perioden is de vraag nul; wanneer er wel bestellingen zijn, kunnen de aantallen sterk schommelen. Klassieke voorspellingstools die goed werken voor alledaagse goederen hebben moeite in deze situatie, wat vaak leidt tot lege schappen of dure stapels ongebruikt voorraad. Omdat reserveonderdelen cruciaal zijn om apparatuur draaiende te houden, kunnen slechte voorspellingen de servicekwaliteit schaden en de kosten verhogen.
Van oude regels naar leren van data
Om dit aan te pakken, bekeken de onderzoekers zowel lang bestaande statistische methoden als nieuwere data-gedreven benaderingen. Traditionele technieken, bekend als Croston-gebaseerde methoden, zijn speciaal ontworpen voor reeksen met veel nullen, maar ze kennen beperkingen wanneer de vraag zeer grillig wordt. Nieuwere machine learning-methoden zoals support vector machines, random forests en lineaire regressie, en deep learning-methoden zoals multilayer perceptrons, recurrente neurale netwerken en long short-term memory-netwerken, kunnen automatisch complexe patronen uit data leren. Iedere methode heeft echter zijn eigen sterke en zwakke punten, en geen enkel model is in alle situaties het beste.
Reële data van een reserveonderdelenfabrikant
Het team werkte samen met een Turkse fabrikant die componenten voor elektrische aandrijfsystemen van voertuigen produceert. Ze richtten zich op twee hoogwaardige reserveonderdelen die bijzonder moeilijk te plannen zijn: één met intermitterende vraag en één met sterk klonterige vraag. Met 51 maanden aan echte maandelijkse verkoopgegevens werden de records opgeschoond en genormaliseerd, waarna de vraagpatronen werden geclassificeerd met standaardmaatstaven voor hoe vaak vraag voorkomt en hoeveel die varieert. De data werden gesplitst in trainings- en testsets zodat modellen werden beoordeeld op onzichtbare perioden, wat de echte wereld van voorspellingen weerspiegelt.
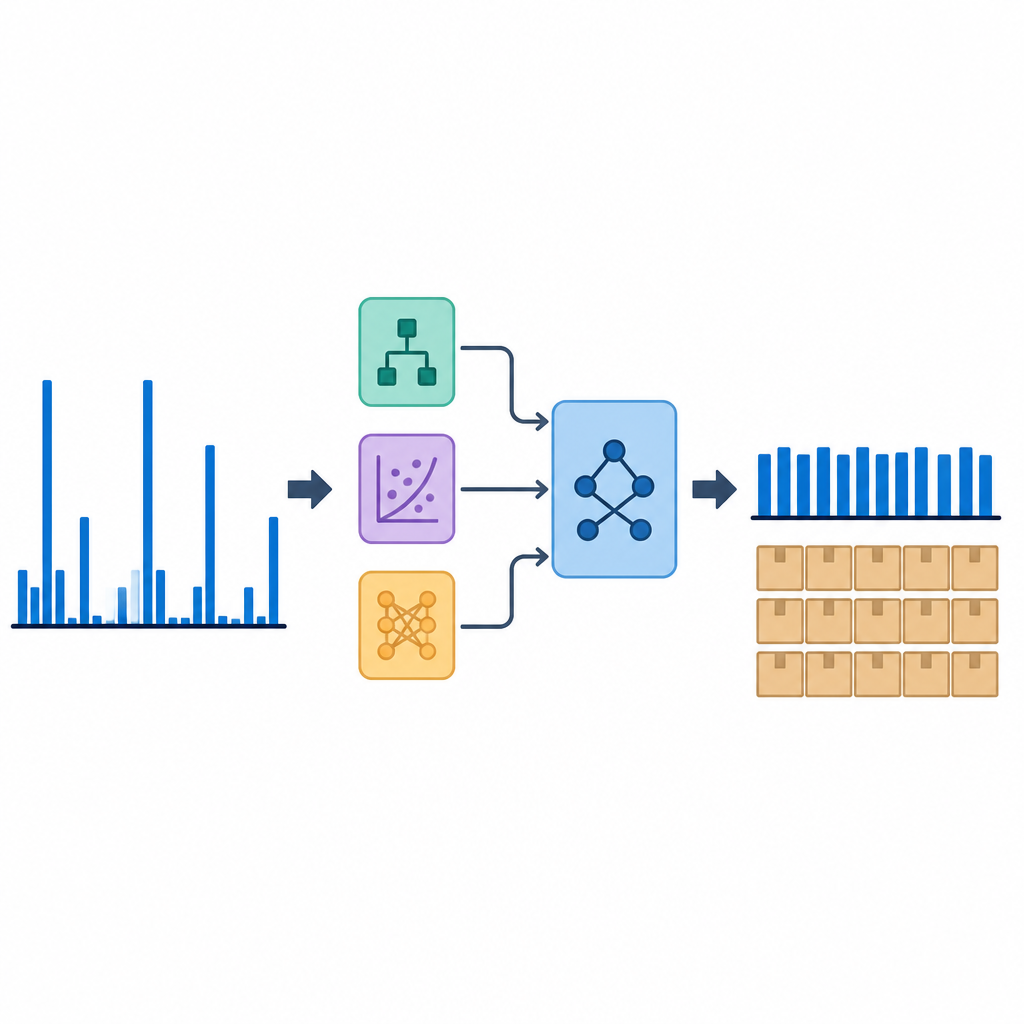
Veel modellen laten samen stemmen
In plaats van te vertrouwen op één enkel voorspellingsinstrument bouwden de auteurs een stacking-ensemble, te zien als een team van modellen waarvan de uitkomsten worden gecombineerd door een eenvoudige tweedelige modellaag. Eerst produceerden verschillende machine learning- en deep learning-modellen onafhankelijk voorspellingen. Hun voorspellingen werden vervolgens gevoed aan een lineair regressiemodel dat leerde hoeveel het elk model moest vertrouwen. Dit gelaagde model werd vergeleken met Croston-gebaseerde methoden en elk individueel leermodel, met foutmaten die typische fouten vastleggen en hoe groot ze zijn ten opzichte van de gemiddelde vraag. De onderzoekers gebruikten ook grafische samenvattingen en statistische toetsen om te controleren of prestatieverschillen betekenisvol waren en niet door toeval veroorzaakt.
Wat de slimmer voorspellingen voor bedrijven betekenen
Het gelaagde model produceerde consequent de meest nauwkeurige en stabiele voorspellingen voor zowel intermitterende als klonterige vraag. Deep learning-methoden op zichzelf presteerden over het algemeen beter dan traditionele benaderingen, maar het combineren van meerdere methoden werkte het beste. Voor het partnerbedrijf resulteerde dit in lagere veiligheidsvoorraden, minder verouderde artikelen in de schappen en een verminderd risico om klanten niet op tijd te kunnen leveren. Simpel gezegd toont de studie aan dat het gebruik van een zorgvuldig ontworpen mix van AI-modellen rommelige, stop-en-go vraag naar reserveonderdelen kan omzetten in voorspellingen die goed genoeg zijn om slankere voorraden en betrouwbaardere service te ondersteunen.
Bronvermelding: Albayrak Ünal, Ö., Erkayman, B. & Usanmaz, B. An effective AI infused demand forecasting application for automotive spare parts industry: a real case from Turkey. Sci Rep 16, 15661 (2026). https://doi.org/10.1038/s41598-026-44461-0
Trefwoorden: vraag naar reserveonderdelen, intermitterende vraag, ensemble learning, autosector toeleveringsketen, vraagvoorspelling