Clear Sky Science · fr
Une application de prévision de la demande enrichie par l’IA pour l’industrie des pièces détachées automobiles : un cas réel de Turquie
Pourquoi il est important d’estimer la demande de pièces détachées
Lorsqu’une voiture tombe en panne, les conducteurs s’attendent à trouver la bonne pièce en stock. Pour les fabricants et les ateliers, maintenir des pièces suffisantes sans surcharger les entrepôts est un exercice permanent d’équilibriste. Cette étude examine comment l’utilisation intelligente de l’intelligence artificielle peut aider les acteurs de l’industrie des pièces détachées automobiles à mieux prédire une demande très irrégulière, économisant ainsi de l’argent tout en maintenant les clients sur la route.
Le défi d’une demande en mode stop-and-go
Les pièces détachées ne se vendent pas de façon régulière et continue. De nombreux articles restent des mois sans commande, puis subissent des pics soudains de demande. Les auteurs qualifient ces schémas de demande d’intermittents et en bosses. Pendant de nombreuses périodes, la demande est nulle ; lorsque des commandes surviennent, les quantités peuvent varier fortement. Les outils de prévision classiques, efficaces pour des biens courants, peinent dans ce contexte, conduisant souvent à des ruptures de stock ou à des accumulations coûteuses d’invendus. Comme les pièces détachées sont essentielles pour maintenir les équipements en fonctionnement, de mauvaises prévisions peuvent dégrader la qualité du service et augmenter les coûts.
Des règles anciennes à l’apprentissage à partir des données
Pour répondre à ce problème, les chercheurs ont passé en revue des méthodes statistiques éprouvées et des approches plus récentes fondées sur les données. Les techniques traditionnelles basées sur Croston ont été conçues spécifiquement pour des séries comportant beaucoup de zéros, mais elles montrent leurs limites quand la demande devient très erratique. Des méthodes d’apprentissage automatique plus récentes, telles que les machines à vecteurs de support, les forêts aléatoires et la régression linéaire, ainsi que des méthodes de deep learning comme les perceptrons multicouches, les réseaux neuronaux récurrents et les réseaux à mémoire long terme (LSTM), peuvent apprendre automatiquement des schémas complexes à partir des données. Toutefois, chaque méthode a ses forces et ses faiblesses, et aucun modèle unique n’est optimal dans toutes les situations.
Données réelles d’un fabricant de pièces
L’équipe a travaillé avec un fabricant turc produisant des composants de systèmes d’entraînement électrique pour véhicules. Ils se sont concentrés sur deux pièces détachées à forte valeur, particulièrement difficiles à planifier : l’une présentant une demande intermittente et l’autre une demande fortement en bosses. En utilisant 51 mois de données réelles de ventes mensuelles, ils ont nettoyé et normalisé les enregistrements, puis classé les schémas de demande à l’aide de mesures standards de la fréquence d’apparition de la demande et de sa variabilité. Les données ont été séparées en ensembles d’entraînement et de test afin que les modèles soient évalués sur des périodes non vues, reproduisant la prévision en conditions réelles.
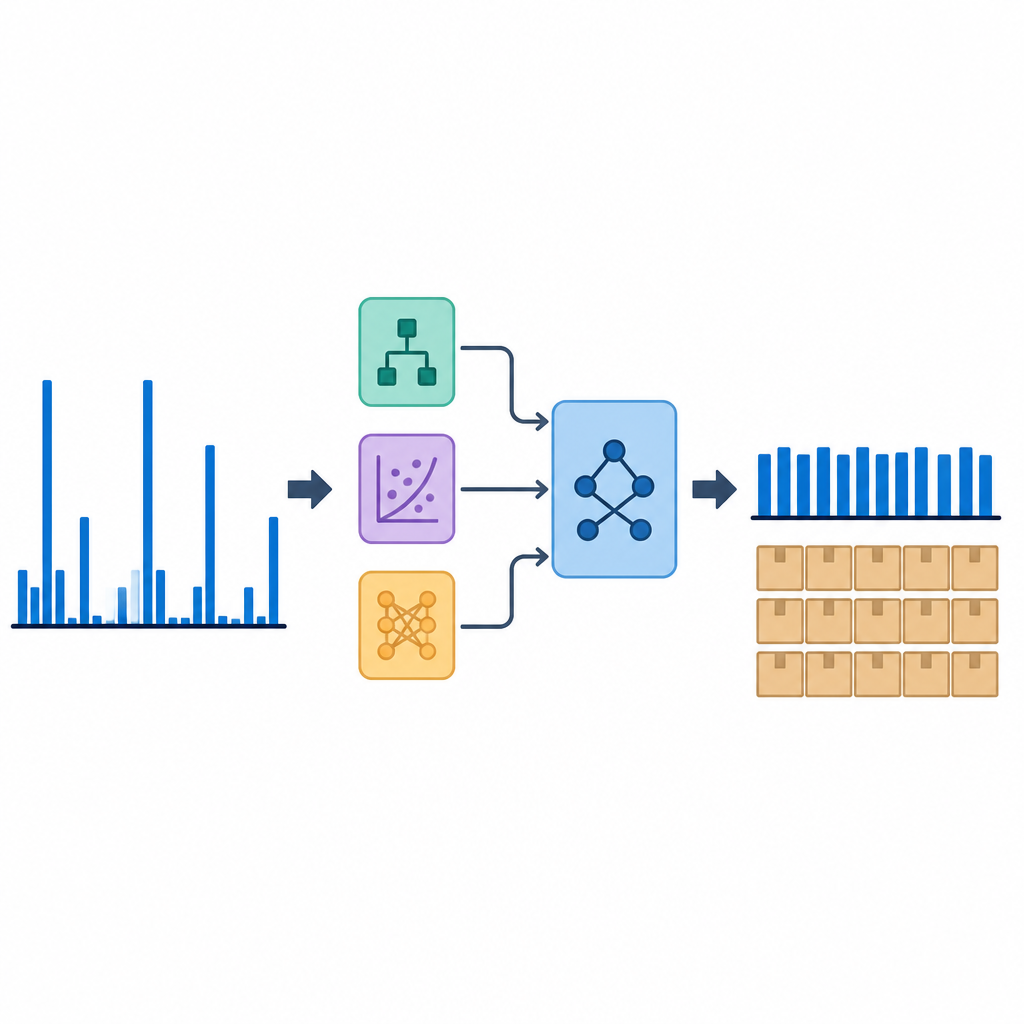
Laisser plusieurs modèles voter ensemble
Plutôt que de s’appuyer sur un seul outil de prévision, les auteurs ont construit un empilement (stacking), que l’on peut voir comme une équipe de modèles dont les sorties sont combinées par un modèle de second niveau simple. D’abord, plusieurs modèles d’apprentissage automatique et de deep learning ont produit indépendamment des prévisions. Leurs prédictions ont ensuite été introduites dans un modèle de régression linéaire qui a appris à quelle valeur accorder confiance pour chacune. Ce modèle empilé a été comparé aux méthodes basées sur Croston et à chaque méthode individuelle, en utilisant des mesures d’erreur qui captent les erreurs typiques et leur amplitude relative à la demande moyenne. Les chercheurs ont aussi utilisé des résumés graphiques et des tests statistiques pour vérifier si les différences de performance étaient significatives et non dues au hasard.
Ce que des prévisions plus intelligentes signifient pour l’entreprise
Le modèle empilé a produit de façon constante les prévisions les plus précises et les plus stables pour la demande intermittente comme pour la demande en bosses. Les méthodes de deep learning isolées ont généralement surpassé les approches traditionnelles, mais la combinaison de plusieurs méthodes a donné les meilleurs résultats. Pour l’entreprise partenaire, cela s’est traduit par des stocks de sécurité réduits, moins d’articles obsolètes sur les étagères et un risque moindre de ne pas approvisionner les clients à temps. En termes simples, l’étude montre qu’un mélange soigneusement conçu de modèles d’IA peut transformer une demande chaotique et saccadée de pièces détachées en prévisions suffisamment bonnes pour soutenir des stocks plus fins et un service plus fiable.
Citation: Albayrak Ünal, Ö., Erkayman, B. & Usanmaz, B. An effective AI infused demand forecasting application for automotive spare parts industry: a real case from Turkey. Sci Rep 16, 15661 (2026). https://doi.org/10.1038/s41598-026-44461-0
Mots-clés: demande de pièces détachées, demande intermittente, apprentissage en ensemble, chaîne d’approvisionnement automobile, prévision de la demande