Clear Sky Science · nl
Interpreteerbaar machine learning-beslisboommodel voor het voorspellen van obstructieve luchtwegaandoeningen in een grote niet-rokende populatie tijdens gezondheidscontroles
Waarom verborgen longproblemen ertoe doen
Veel mensen denken dat ernstige longziekten vooral een bedreiging vormen voor langdurige rokers. Toch ontwikkelt een verrassend aantal niet-rokers in stilte ademhalingsproblemen die onopgemerkt blijven totdat ze ernstig worden. Deze studie stelde een praktische vraag: kunnen we routinegegevens uit gezondheidscontroles — zoals leeftijd, bloeddruk en gangbare bloedtesten — gebruiken om niet-rokende volwassenen te signaleren waarvan de longen mogelijk al moeite hebben, lang voordat ze kortademigheid voelen? De onderzoekers wilden ook dat de voorspellingen begrijpelijk zijn voor artsen, en geen mysterieus black box-model.
Zoeken naar waarschuwingssignalen in routinecontroles
Het team analyseerde gegevens uit een omvangrijk screeningsprogramma in Taiwan dat meer dan een half miljoen volwassenen volgde. Uit deze grote groep richtten ze zich op 81.055 personen die nooit gerookt hadden en volledige gegevens hadden van hun lichamelijk onderzoek, laboratoriumtests en longfunctietests. De longfunctie werd gemeten met een standaard ademtest die vergelijkt hoeveel lucht iemand in één seconde kan uitblazen met hun totale ademvolume. Wanneer deze verhouding onder een bepaalde grens zakt, duidt dat op luchtwegobstructie, een kenmerk van aandoeningen zoals astma en chronische obstructieve longziekte (COPD).
Computers leren longrisico te herkennen
In plaats van te vertrouwen op één computermethode, combineerden de onderzoekers zes bekende machine learning-benaderingen die vaak in medische voorspellingsstudies worden gebruikt. Deze methoden omvatten beslisbomen en verschillende gerelateerde technieken die grote verzamelingen bomen bouwen om de nauwkeurigheid te verhogen. Elke methode werd getraind om onderscheid te maken tussen mensen met normale ademtestresultaten en degenen met luchtwegobstructie, met gebruik van 25 veelvoorkomende gegevens zoals leeftijd, lengte, gewicht, bloeddruk, opleidingsniveau en routinematige bloedmetingen. Om de resultaten betrouwbaar te houden, splitste het team de data herhaaldelijk in trainings- en testsets, balanceerde zeldzame positieve gevallen met meer gangbare negatieve, en evalueerde hoe goed elk model presteerde.
De meest aanwijzende kenmerken vinden
Alle zes computermodellen deden het redelijk goed en behaalden vergelijkbare scores bij het scheiden van personen met en zonder obstructieve luchtwegen. Maar het echte doel was te achterhalen welke kenmerken uit het onderzoek het belangrijkst waren en die kennis om te zetten in eenvoudige regels die artsen kunnen volgen. Daartoe rangschikten de onderzoekers de belangrijkheid van elk kenmerk in elk model en middelen deze ranglijsten. Leeftijd kwam consequent bovenaan in alle methoden. Maatstaven die samenhang vertonen met lichaamsbouw — zoals lengte en gewicht — bleken ook belangrijk, net als bloeddruk en verschillende routinematige laboratoriumtests. Een daarvan, lactaatdehydrogenase (LDH), is een algemene marker voor weefselstress in het lichaam en leek nuttige informatie over longgezondheid te dragen, zelfs wanneer andere bloedtesten in aanmerking werden genomen.
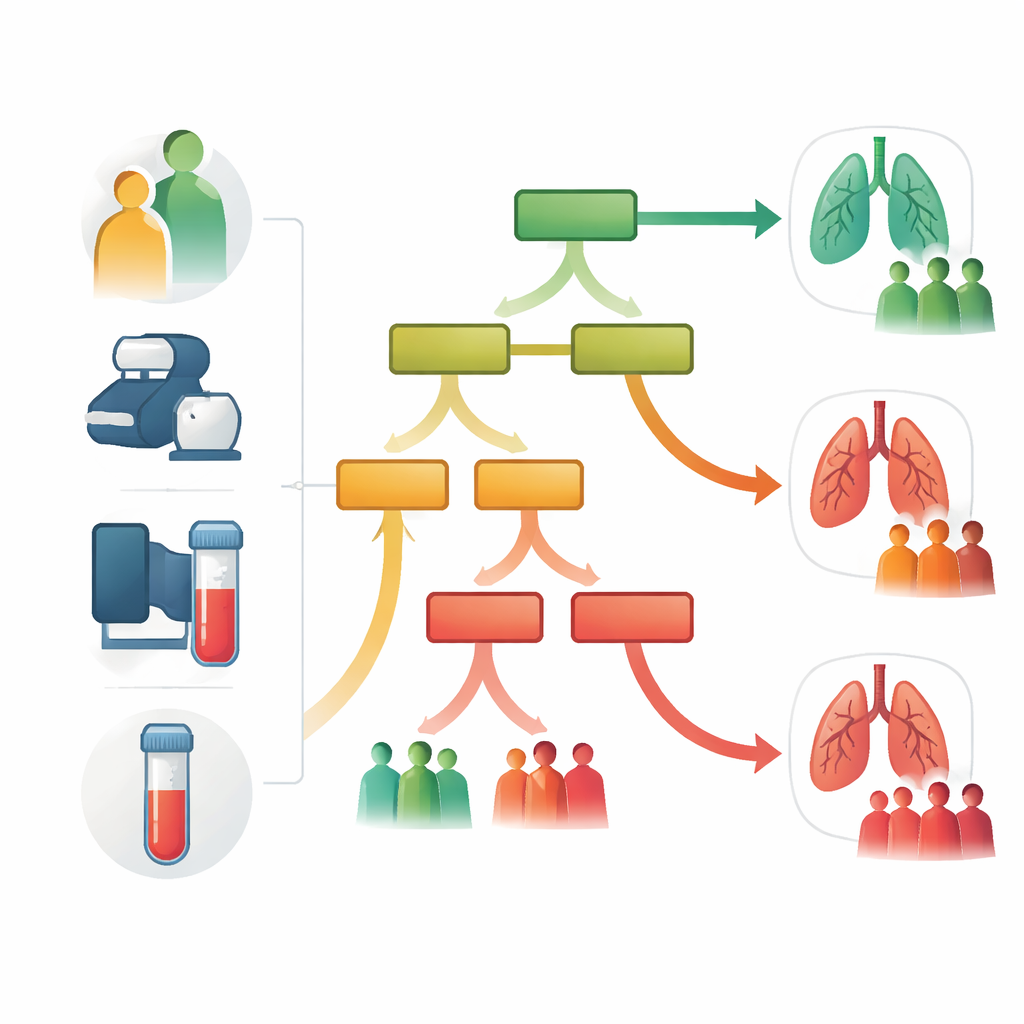
Van complexe modellen naar eenvoudige beslisregels
Nadat de sterkste voorspellers waren vastgesteld, bouwde het team een enkele, goed leesbare beslisboom die slechts het bovenste 30 procent van de kenmerken gebruikte. Dit eenvoudigere model presteerde bijna even goed als modellen die alle 25 variabelen gebruikten, maar met een structuur die clinici visueel kunnen inspecteren. De boom begint met leeftijd bovenaan en vertakt vervolgens op basis van factoren zoals lengte, LDH-niveaus, lichaamsgewicht en opleidingsniveau. Door elke tak te volgen kom je bij ‘blad’-groepen met een hogere of lagere kans op luchtwegobstructie. Bijvoorbeeld: oudere volwassenen boven een bepaalde leeftijd, of jongere maar kortere volwassenen met specifieke labpatronen, vormden groepen waarin obstructieve luchtwegproblemen vaker voorkwamen. De auteurs benadrukken dat sommige van deze markers, met name LDH, niet specifiek voor de longen zijn en waarschijnlijk eerder de algehele gezondheid dan directe longschade weerspiegelen.
Wat dit betekent voor routinecontroles
De studie toont aan dat het mogelijk is om routinematige gegevens uit gezondheidscontroles om te zetten in een interpreteerbare set regels die niet-rokers markeren die mogelijk een nauwere longevaluatie nodig hebben, zoals volledige longfunctietesten of verwijzing naar een specialist. Het model is niet bedoeld om longfunctietesten te vervangen of een definitieve diagnose te geven, maar fungeert als een slimme triage-assistent die artsen helpt risicovolle personen op te merken die anders over het hoofd gezien zouden kunnen worden. Omdat de aanpak gebaseerd is op veelvoorkomende metingen en nadruk legt op duidelijke, stapsgewijze beslispaden, kan ze worden aangepast aan screeningsomgevingen in de praktijk. Toekomstig onderzoek moet deze bevindingen over tijd en in meer diverse populaties bevestigen, maar dit onderzoek biedt een veelbelovend voorbeeld van hoe transparante kunstmatige intelligentie vroegtijdige opsporing van stille longproblemen kan ondersteunen.
Bronvermelding: Chang, CY., Shen, HS., Kuo, YL. et al. Interpretable machine learning based decision tree model for predicting obstructive airway disease in a large non-smoking health screening population. Sci Rep 16, 12807 (2026). https://doi.org/10.1038/s41598-026-43633-2
Trefwoorden: obstructieve luchtwegaandoening, longgezondheid niet-rokers, interpreteerbare machine learning, beslisboom screening, gegevens van gezondheidscontrole