Clear Sky Science · nl
Toestandbewaking en voorspelling van logistieke apparatuur op basis van digitale tweeling en machine learning
Waarom slimere magazijnen ertoe doen
Achter elke online bestelling schuilt een doolhof van heftrucks, transportbanden, robots en sorteersystemen die bijna continu moeten draaien. Wanneer een van deze machines onverwacht uitvalt, lopen leveringen vertraging op, stijgen de kosten en kunnen werknemers in gevaar komen. Dit artikel onderzoekt hoe een krachtige combinatie van virtuele replica’s, sensoren en machine learning logistieke apparatuur langer gezonder kan houden—en onderhoud verandert van een paniekreactie in een goed geplande, vrijwel onzichtbare achtergrondactiviteit.
Virtuele spiegels van echte machines
De auteurs bouwen hun aanpak rond “digitale tweelingen” van magazijnapparatuur: gedetailleerde virtuele versies van heftrucks, transportbanden, automatisch geleide voertuigen, kranen en robots. Deze tweelingen worden synchroon gehouden met de echte machines via netwerken van sensoren die trillingen, temperatuur, geluid, elektrische stroom, locatie en belasting meten. Datastromen lopen via lichtgewicht communicatieprotocollen zodat de virtuele modellen ongeveer elke tiende van een seconde worden bijgewerkt. Deze constante spiegeling maakt dat de digitale tweeling zich gedraagt als een vluchtsimulator voor elk object, die niet alleen de huidige staat weergeeft maar ook voorspelt hoe het zal verouderen en uiteindelijk kan falen.
Machines leren vroegtijdig problemen te signaleren
Bovenop deze live digitale laag voegen de onderzoekers machine learning-modellen toe die zich specialiseren in drie kerntaken. Ten eerste voeren ze anomaliedetectie uit: leren hoe “normaal” eruitziet en subtiele afwijkingen signaleren die kunnen duiden op vroege slijtage, uitlijningproblemen of sensorstoringen. Hiervoor gebruiken ze technieken die zeldzaam, vreemd gedrag in de data isoleren, evenals neurale netwerken die getraind zijn om gezonde patronen te reconstrueren en grote reconstructiefouten als waarschuwingssignalen te behandelen. Ten tweede schatten ze de resterende nuttige levensduur, waarbij ze inschatten hoeveel bedrijfscycli of uren er nog resten voordat een component waarschijnlijk faalt. Hiervoor vertrouwen ze op modellen die sequenties goed begrijpen, zoals recurrente neurale netwerken, samen met boomgebaseerde methoden die aangeven welke sensorwaarden het meest relevant zijn. Ten derde classificeren ze het waarschijnlijke fouttype—bijvoorbeeld onderscheid maken tussen een versleten riem, een defect lager, een hydraulische lekkage of een elektrisch probleem—zodat technici de juiste onderdelen en vaardigheden kunnen meenemen.
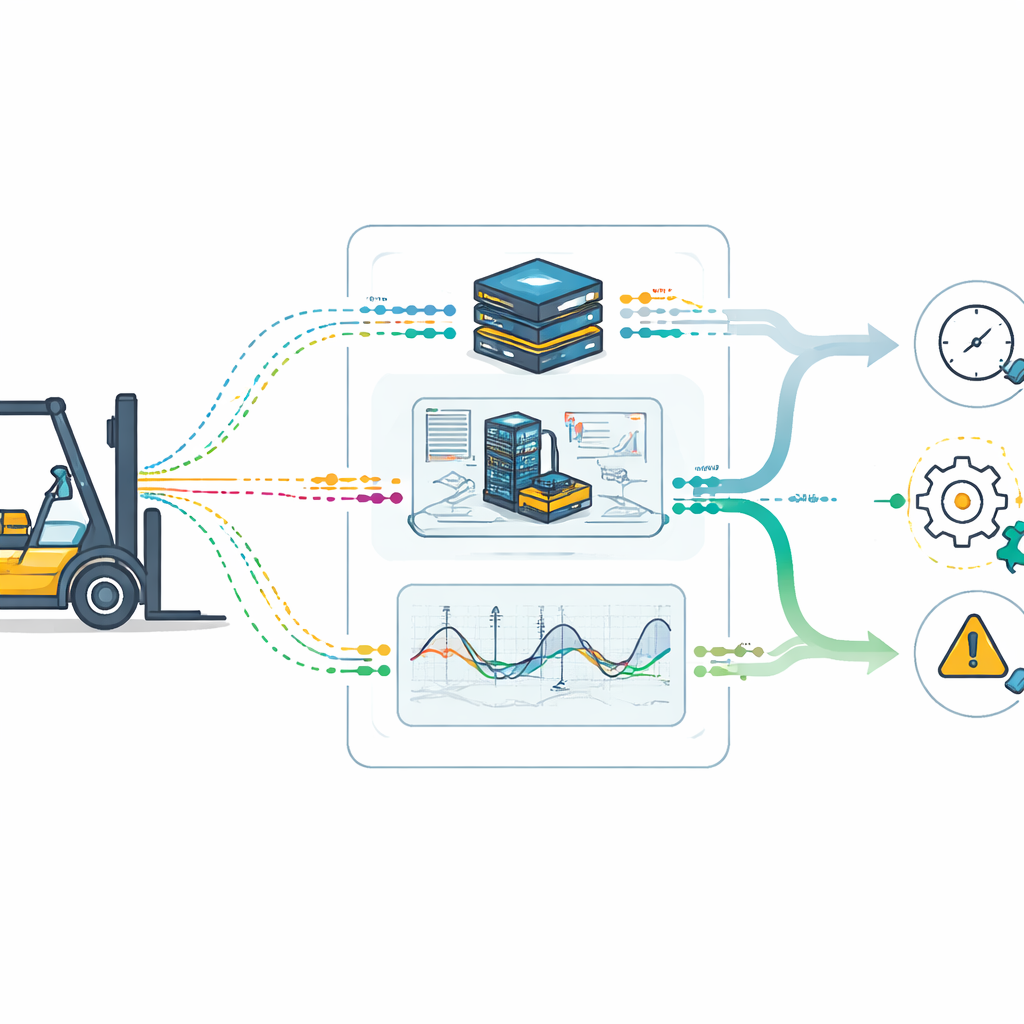
Van ruwe data naar betrouwbare voorspellingen
Om deze modellen betrouwbaar te maken, combineert het team een jaar aan echte gebruikslogboeken van 150 apparatuurstukken met synthetische faalscenario’s die binnen de digitale tweeling worden gegenereerd. Ze maken de data zorgvuldig schoon en uitgelijnd, dempen ruis, vullen ontbrekende waarden aan en normaliseren metingen zodat geen enkele sensor het leerproces domineert. Het resultaat is een rijk beeld van hoe verschillende componenten verouderen onder wisselende belastingen en omstandigheden. In tests detecteert een ensemble van anomaliedetectiemethoden meer dan 90% van de echte problemen terwijl het aantal valse alarmen laag blijft. Voorspellingen van resterende levensduur zijn doorgaans nauwkeurig binnen een klein deel van de levensduur van een component, vooral voor onderdelen zoals lagers en motorwikkelingen die consistente slijtagepatronen tonen. Modellen voor foutclassificatie behalen in totaal ongeveer 90% nauwkeurigheid en presteren bijzonder goed op de meest voorkomende en ontwrichtende mechanische problemen.
Wat dit betekent voor magazijnen en kosten
Wanneer het volledige systeem in een distributiecentrum wordt ingezet, is de impact opvallend. Ongeplande stilstand neemt met meer dan 40% af en noodreparatie-oproepen halveren bijna, omdat meer werkzaamheden naar geplande onderhoudsvensters verschuiven. Machines draaien langer tussen storingen en reparatietijden verkorten omdat monteurs arriveren met een goed idee van wat er waarschijnlijk mis is. Overall equipment effectiveness, een belangrijke industriële maat die beschikbaarheid, snelheid en kwaliteit combineert, stijgt met bijna 11%. Financieel bespaart de locatie ongeveer 1,4 miljoen dollar per jaar aan vermeden productieverlies, spoedonderdelen, overuren en veiligheidsincidenten, waarmee de initiële investering in slechts enkele maanden is terugverdiend en op langere termijn een veelvoud van de aanvangskosten oplevert.
Waarnaartoe deze technologie zich ontwikkelt
Voor niet-specialisten is de kernboodschap dat magazijnen en distributiecentra steeds meer op levende, lerende systemen gaan lijken. Elke heftruck of transportband kan binnenkort een virtuele schaduw hebben die ongewoon gedrag opmerkt, inschat hoe lang hij veilig kan blijven werken en het beste moment voor ingrijpen aangeeft. De studie laat zien dat een dergelijke opzet realistisch gezien de stilstand met 30–50% kan verminderen en de onderhoudskosten met 20–40% kan verlagen, terwijl de veiligheid verbetert en de levensduur van machines wordt verlengd. Vooruitkijkend zien de auteurs digitale tweelingen voor zich die over meerdere locaties samenwerken, veilig van elkaar leren en niet alleen storingen voorspellen maar ook helpen bij het plannen van voorraad, personeelsinzet en energiegebruik—en zo stilletjes de wereldwijde goederenstroom veerkrachtiger en efficiënter maken.
Bronvermelding: Han, F., Liu, L. & Sun, J. Logistics equipment condition monitoring and prediction based on digital twin and machine learning. Sci Rep 16, 12790 (2026). https://doi.org/10.1038/s41598-026-43380-4
Trefwoorden: digitale tweeling, voorspellend onderhoud, logistieke automatisering, IoT-sensoren, machine learning