Clear Sky Science · nl
MMU-STCNN-BDQ: een deep reinforcement learning-framework voor veilige en energiezuinige beamforming in 6G mMIMO-netwerken
Waarom het signaal van uw toekomstige telefoon slimere bundels nodig heeft
Nu draadloze netwerken naar 6G evolueren, moeten ze tegelijk aan drie lastige doelen voldoen: ultrahoge datasnelheden, laag energieverbruik en sterke bescherming tegen afluisteren. Dit artikel onderzoekt hoe geavanceerde leeralgoritmen radiogolven slimmer kunnen sturen, zodat signalen de juiste apparaten bereiken, minder energie verspillen en moeilijker door aanvallers te misbruiken zijn.
De uitdaging om meer data door de lucht te krijgen
De huidige mobiele netwerken raken uitgeput wat betreft eenvoudige manieren om meer data in het beperkte radiospectrum te proppen. Eén oplossing is overstap naar millimetergolf‑ en terahertzbanden, waar grote ongebruikte frequentiegebieden liggen. In deze hoge banden kunnen basisstations grote antennearrays gebruiken om smalle bundels te vormen die direct naar elke gebruiker wijzen. Deze “massive MIMO”-benadering versterkt het signaal en maakt het mogelijk dat veel mensen hetzelfde kanaal delen. Maar het brengt ook nieuwe problemen met zich mee: de hardware wordt complex en energieverslindend, de bundels moeten voortdurend aanpassen aan bewegende gebruikers en geblokkeerde paden, en juist de leersystemen die bepalen waar de bundels heen wijzen kunnen zelf een beveiligingszwakte vormen.
Waarom slimme bundels ook veiliger moeten zijn
In 6G zullen beamforming‑beslissingen naar verwachting sterk leunen op machine learning‑modellen die metingen van het radiokanaal verwerken en voorspellen hoe elke bundel te richten en te vormen. Dat maakt het systeem wendbaar maar ook kwetsbaar. Aanvallers kunnen proberen de modellen te misleiden, slechte data in te voeren of zich stilletjes te tappen in nauw gefocusseerde signalen. De auteurs bespreken deze risico’s, van adversariële aanvallen op de leeralgoritmen tot privacylekken die de locatie of identiteit van een gebruiker onthullen. Ze tonen aan dat bestaande methoden meestal kiezen voor nauwkeurigheid en snelheid of voor veiligheid, maar zelden alle drie tegelijk, zeker niet in drukke netwerken met veel gebruikers en snel veranderende omstandigheden.
Een hybride leerengine voor 6G‑basisstations
Om deze problemen aan te pakken, stelt het artikel een gecombineerd leerframework voor genaamd MMU‑STCNN‑BDQ. Eerst bekijkt een ruimtelijk‑tijdelijk neuraal netwerk ruwe kanaalmetingen over ruimte en tijd en leert patronen die beschrijven hoe signalen reflecteren, dempen en veranderen als gebruikers bewegen. Deze front‑end levert een initiële schatting van hoe bundels gevormd en gericht moeten worden voor veel gebruikers tegelijk. Daarna behandelt een tweede component, een reinforcement learning‑engine, elke beamforming‑beslissing als een actie in een spel: hij probeert verschillende strategieën, observeert de resulterende datasnelheid, het energieverbruik en de foutenrate, en leert geleidelijk welke keuzes het beste lange‑termijn compromis bieden tussen snelheid, betrouwbaarheid en geheimhouding.
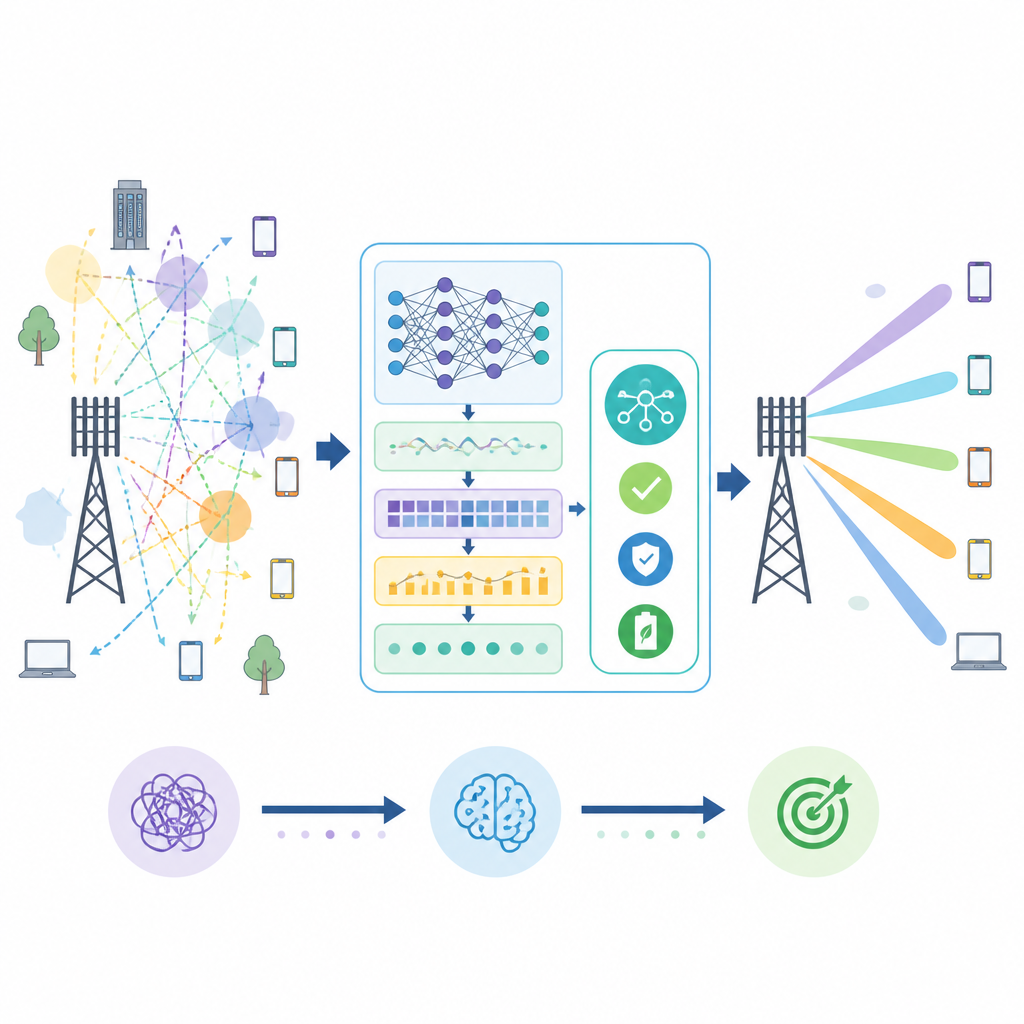
Hoe de nieuwe methode presteert in drukke radiogolven
De auteurs testen hun aanpak met een realistische simulatiedataset waarin een basisstation met 256 antennes tot 50 gebruikers bedient op millimetergolf‑frequenties. Ze vergelijken hun framework met drie sterke referenties: een standaard deep neural network, een conventionele deep reinforcement learner en een adversarieel getrainde veilige beamforming‑methode. In veel scenario’s en signaal‑tegen‑ruisniveaus voorspelt hun systeem consequent betere bundels, vermindert de mismatch tussen gewenste en daadwerkelijke bundels, verlaagt de bitfoutpercentages en verhoogt de throughput. Het gebruikt ook energie efficiënter en levert meer data per eenheid vermogen. Belangrijk is dat bij uiteenlopende gesimuleerde aanvallen die proberen het leerproces of de kanaaldata te verstoren, het voorgestelde framework geleidelijk degradeert en het grootste deel van zijn prestaties behoudt.
Wat dit betekent voor alledaagse draadloze gebruikers
Voor niet‑experts is de belangrijkste conclusie dat toekomstige 6G‑basisstations een gelaagde leerengine kunnen gebruiken die zowel “ziet” hoe de radio‑omgeving zich ontwikkelt als “handelt” op een doelgerichte manier om verbindingen snel, zuinig en privé te houden. Door patroonherkenning te verenigen met trial‑and‑error‑leren helpt deze aanpak bundels nauwkeuriger op gebruikers te richten, terwijl er minder energie wordt verspild en afluisteraars het moeilijker wordt gemaakt. De auteurs merken op dat real‑world uitrol nog lichtere versies van de algoritmen en tests in echte breedbandige en imperfecte omstandigheden zal vereisen, maar hun resultaten wijzen op een veelbelovende weg naar 6G‑netwerken die niet alleen sneller, maar ook slimmer en veiliger zijn.
Bronvermelding: Ramudu, K., Medasani, S., Addepalli, T. et al. MMU-STCNN-BDQ: a deep reinforcement learning framework for secure and energy-efficient beamforming in 6G mMIMO networks. Sci Rep 16, 15684 (2026). https://doi.org/10.1038/s41598-025-26572-2
Trefwoorden: 6G beamforming, massive MIMO, draadloze beveiliging, energiezuinige netwerken, deep reinforcement learning