Clear Sky Science · ja
神経科学と心理学に触発されたスパイキングニューラルネットワークによる西洋音楽の調(モード・キー)条件付き学習と作曲
コンピュータに「調」を聞かせる意義
ほとんどの人は、曲が最終音に向かって「帰着」したと感じたり、不適切な和音で全体が不穏に聞こえたりすることがあります。その直感は、西洋音楽の下にある調とモードの隠れたルール、つまり音楽の調性の骨格に基づいています。現代の人工知能は無限の旋律を生成できますが、これらの規則を無視したり原始的にハードコードしたりすることが少なくありません。本稿は、人間の聴き手に近いかたちで調とモードを学習し、その知識を用いて四声の和声を作曲する、新しい脳に着想を得たモデルを紹介します。目的は音楽機械をより音楽的にするだけでなく、より理解可能にすることです。
日常の聴取から音の内部地図へ
音楽を聴くと、どの音が安定して感じられ、どの音が緊張を生み、どのようにパターンが展開するかを脳が徐々に内部地図として作り上げます。心理学では、各12のピッチクラスがある調にどれだけ属するかを測るKrumhansl–Schmucklerモデルなどでこの現象が捉えられています。神経科学は、この種のスキーマ的知識が、内側前頭前野や海馬のような時間的に経験を組織する脳領域と結びつくことを示しています。著者らは、多くの深層学習を使った音楽システムがこれらの心理学的・生物学的洞察を飛ばしてしまうと論じます。多くはすべての曲を基準の調に無理やり合わせたり、調を単純なラベルとして扱ったりし、その内部挙動は解釈しにくいのです。本研究は代わりに、その内部結合を人間の調性知覚と直接比較できるネットワークの構築を目指します。
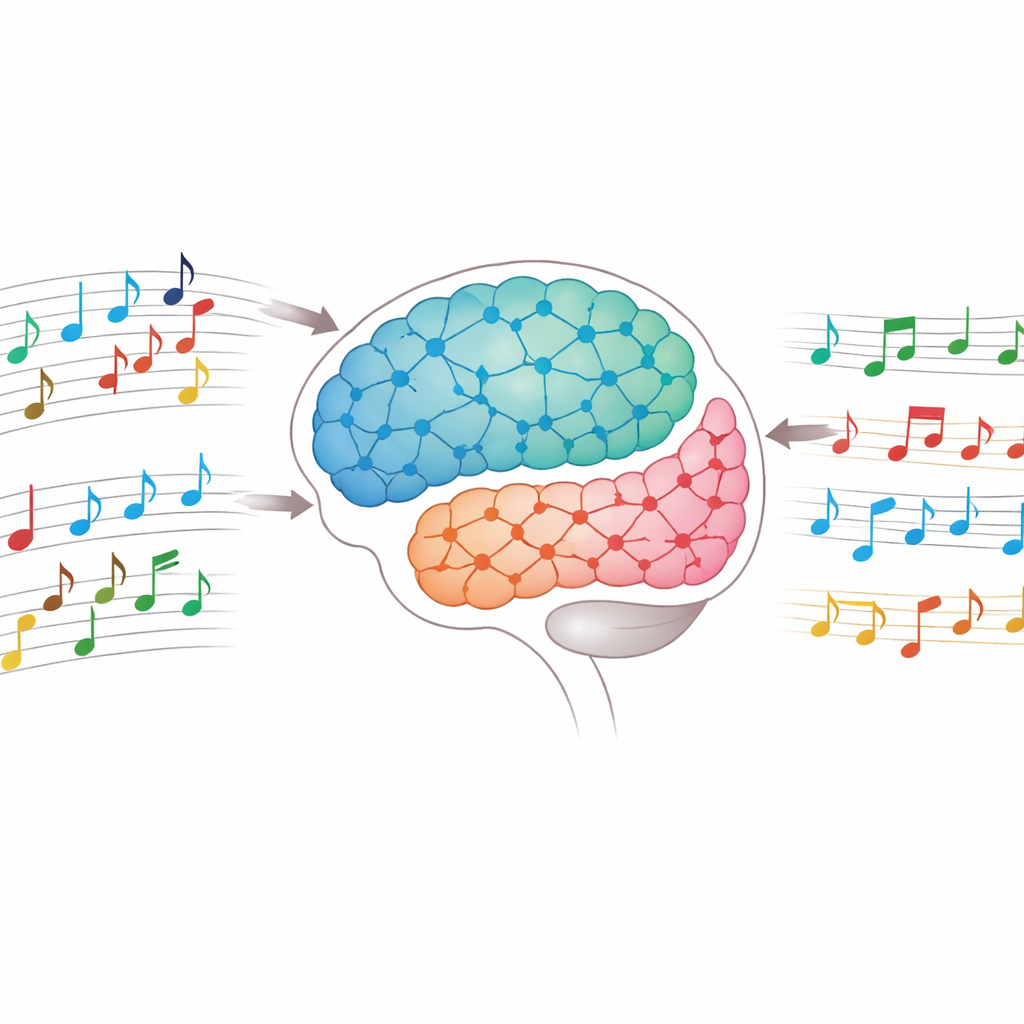
音階と連続性の両方を聞き取る脳風ネットワーク
研究者たちは、実際のニューロンのように短い電気パルスで情報をやり取りするモデルであるスパイキングニューラルネットワークを設計しました。これを大きく二つのサブシステムに分けています。ひとつは「調性(トーナル)」サブシステムで、メジャーとマイナーのモードおよび西洋調性音楽で用いられる24のキーを表現し、脳が抽象的なスキーマを格納する方法を彷彿とさせる階層構造になっています。もうひとつは「逐次記憶」サブシステムで、四声の楽曲の実際の音高とその持続を保持します。これらはソプラノ、アルト、テノール、バスに対応する別々の流れに分かれており、各流れ内で音高と持続は小さなニューロン列(コラム)の配列によって符号化されます。これは聴覚皮質の組織や時間感覚に関する研究で見られる時間敏感な細胞の配置にゆるく着想を得たものです。
経験とともに結合を育てる
あらかじめすべてを配線するのではなく、モデルは曲が入力されている間にニューロンが繰り返し同時に発火すると、調性サブシステムと逐次記憶サブシステムの間に新しいシナプスが形成されるようにしました。これは学習中に神経回路が出現・変化する様子を模しています。一度結合ができると、その強さはスパイクタイミング依存可塑性(STDP)というルールで調整されます。すなわち、送信側ニューロンが受信側ニューロンより先に発火する傾向があれば結合は強化され、順序が逆なら弱化します。教則本の練習課題のように特定の和声を強調する教材や、J.S.バッハのコラール集の大規模コレクションなど多数の曲にわたって学習することで、ネットワーク内部の配線は各モード・キーにおいてどの音が中心的か、支持的か、稀かを反映するようになります。
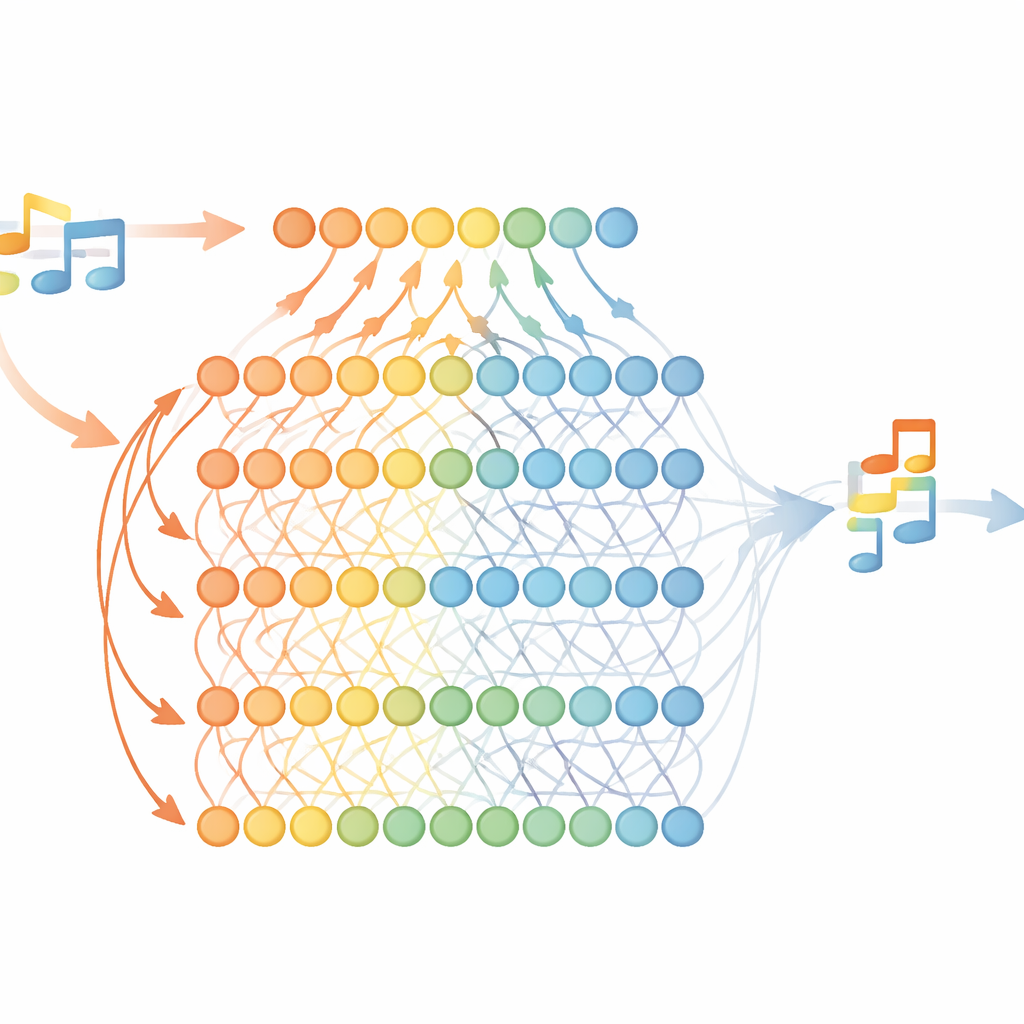
機械の「調」感覚の内部
モデルが人間のような調的期待を本当に獲得したかを検証するため、著者らは学習された結合の二つの特徴を測定しました:各ピッチクラスが蓄えたシナプスの数と、それらシナプスの平均的な強さです。これらのパターンをよく知られた心理学的キー・プロファイルと比較したところ、メジャー・マイナーの両モードおよび多くの個別キーにわたって一致度は非常に高かった。人間が「帰着」音や主要な支持音と聞く音は、ネットワーク内でも最も結合が多く現れました。微妙な差異は訓練素材に由来することが示されました。たとえば特定の和音を強調する練習課題はその音をより強く重みづけさせる方向に影響しました。これはモデルが普遍的な調性則とコーパス特有の習慣の両方を、人間の文化化と同様に取り込んでいることを示唆します。
選ばれたキーで新しい音楽を作る
作曲を行う際、システムには目標のモードとキー、そして短い出だしの和音が与えられます。キー特異的なニューロンの活動が学習された結合を通じて逐次記憶サブシステムにバイアスをかけます。競合する音のニューロンが発火し、シンプルな「勝者総取り」ルールが各声部の次の音を選びます。一歩ずつ、モデルは意図したキー内に留まりつつ多様な旋律形を探る四声和声を生成します。再帰ネットワーク、トランスフォーマー、拡散モデルなどの一般的な深層学習モデル群と比較して、スパイキングモデルは音域、音階音の使用、およびその他の構造的統計が参照データセットにより近い作品を生み出しました。特に、単調にならずにキー内音の比率を非常に高く維持する点が際立ちます。
将来の音楽機械にとっての意義
一般読者にとっての主要な結論は、脳に着想を得たネットワークが私たちの直感的な調・音階感覚に近いものを学習でき、その知識を配線のかたちで直接確認できるということです。モデルはまだ変化する和声、リズムの多様性、表現的タイミングなど実際の音楽のすべての豊かさを扱えているわけではありません。それでも、音楽理論、心理学、神経計算を具体的に橋渡しする可能性を提供します。生物学的に動機づけられたシステムが説得力のある調性を意識した和声を生成し、そこに至る過程を明らかにできることを示すことで、本研究はより音楽的で、かつ音の解釈過程が透明な将来の音楽生成AIの方向性を示しています。
引用: Liang, Q., Zeng, Y. & Tang, M. A spiking neural network inspired by neuroscience and psychology for Western mode- and key-conditioned music learning and composition. Sci Rep 16, 12956 (2026). https://doi.org/10.1038/s41598-026-43529-1
キーワード: スパイキングニューラルネットワーク, 音楽生成, 音楽の調とモード, 計算音楽認知, 脳に着想を得たAI