Clear Sky Science · it
MOFMeld: un framework di fusione struttura–linguaggio per la predizione delle proprietà dei MOF nella cattura del carbonio
Perché materiali più intelligenti sono importanti per pulire l’aria
Ridurre i gas serra come l’anidride carbonica è essenziale per rallentare il riscaldamento globale, ma catturare efficacemente la CO2 dall’aria e dai fumi industriali è ancora molto difficile. Una classe promettente di cristalli porosi chiamata metal–organic frameworks (MOF) può assorbire CO2 come una spugna, eppure solo una frazione minima dei MOF possibili è stata testata. Questo articolo presenta MOFMeld, un nuovo sistema di intelligenza artificiale che aiuta gli scienziati a esplorare molto più rapidamente e con maggiore trasparenza un numero enorme di MOF candidati combinando ciò che sappiamo da misure di laboratorio, modelli al computer e dalla letteratura scientifica.

Dalla sfida climatica alla ricerca di materiali
Le tecnologie per la cattura del carbonio, incluse le centrali per la cattura diretta dall’aria, dipendono da materiali speciali in grado di legare fortemente la CO2, rilasciarla con poca energia e resistere all’uso ripetuto in condizioni umide e reali. I MOF sono attraenti perché i loro blocchi costitutivi possono essere combinati per regolare la dimensione dei pori, l’area superficiale e la chimica. Tuttavia, testare ogni progetto sperimentalmente o con pesanti simulazioni al computer è lento e costoso. La maggior parte dei dati disponibili è sparsa in migliaia di articoli, spesso sepolta in testi e figure anziché in database ordinati. Di conseguenza, gran parte della conoscenza acquisita su quali MOF funzionano bene — e perché — resta sotto-utilizzata.
Fondere la struttura con il linguaggio scientifico
MOFMeld affronta questo problema mettendo insieme due punti di forza dell’IA. Da una parte utilizza un large language model chiamato MOFLLaMA, addestrato appositamente su circa 1.500 articoli su MOF–CO2 e oltre 20.000 coppie domanda–risposta ricavate da questi lavori. Questo modello linguistico è ulteriormente ancorato a un “knowledge graph” che collega i MOF a proprietà sperimentali riportate e ai dettagli di sintesi, in modo che le risposte possano essere ricondotte alle fonti invece di essere ipotesi non fondate. Dall’altra, MOFMeld impiega una rete neurale basata su grafi che legge la vera disposizione atomica tridimensionale di un cristallo di MOF, trasformando la sua rete di pori e connettività in un’impronta numerica compatta. Un modulo “bridge” leggero collega poi queste impronte al modello linguistico in modo che il sistema possa rispondere a domande e fare previsioni tenendo conto della struttura cristallina reale.
Predire quanto bene i MOF catturano il carbonio
Gli autori hanno testato MOFMeld su una grande collezione di MOF ipotetici con proprietà calcolate al computer. Al sistema è stato chiesto di predire sei grandezze importanti: due misure della dimensione dei pori, l’area superficiale complessiva, la porosità (quanto spazio vuoto contiene il solido) e l’assorbimento di CO2 sia a pressioni moderate sia a pressioni molto basse. Anche se MOFMeld è stato addestrato su solo circa 30.000 strutture — molto meno rispetto ai tradizionali modelli basati su grafi — ha eguagliato o superato potenti reti neurali basate esclusivamente sulla struttura nella maggior parte degli obiettivi. In particolare, è risultato molto accurato per caratteristiche geometriche come le dimensioni dei pori e la porosità, e si è distinto nella previsione della cattura di CO2 a bassa pressione, dove la prestazione dipende da siti di legame chimico sottili piuttosto che dal solo volume di poro complessivo.
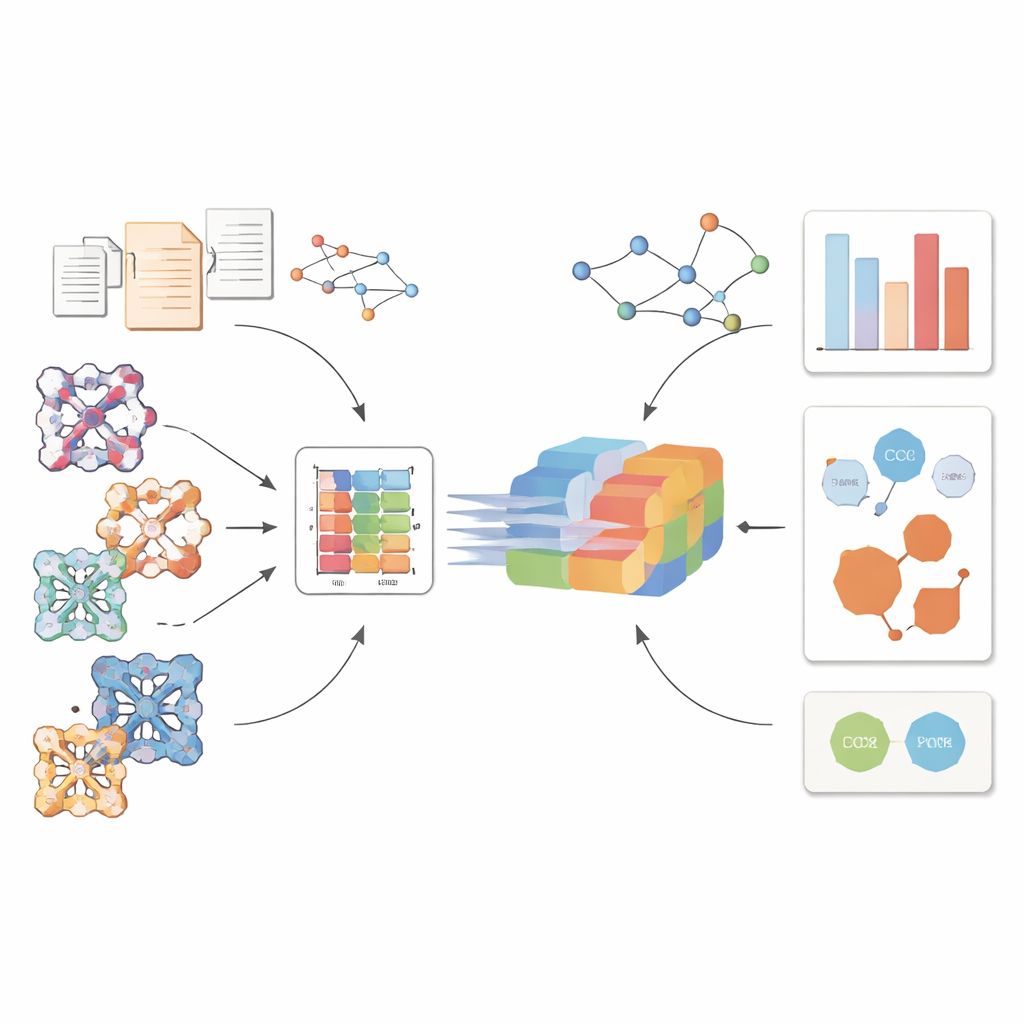
Testare su materiali reali e scrutare dentro il modello
Per valutare come MOFMeld si comporta oltre le strutture simulate, il team lo ha applicato a migliaia di MOF sperimentalmente riportati in un database curato. Il sistema ha classificato i candidati in base all’assorbimento di CO2 previsto e, quando il gruppo migliore è stato verificato con simulazioni dettagliate, molti hanno effettivamente mostrato elevata capacità di cattura. Sebbene gli errori numerici fossero maggiori rispetto al set di test puramente ipotetico — riflettendo la chimica più ampia e disordinata dei MOF reali — lo strumento ha comunque indirizzato l’attenzione verso materiali promettenti. Gli autori hanno inoltre visualizzato le rappresentazioni interne apprese dal modulo bridge. I MOF con porosità simile si sono raggruppati in modo coerente e, quando hanno alterato i segnali strutturali forniti al modello linguistico, la qualità delle predizioni è peggiorata. Questo suggerisce che il modello si affida realmente a indizi strutturali significativi e non si limita a memorizzare schemi testuali.
Cosa significa questo per la futura cattura del carbonio
In termini pratici, MOFMeld funziona come un assistente di ricerca specializzato che non solo legge la letteratura sui MOF ma anche “vede” l’architettura interna di ciascun cristallo, quindi combina entrambe le prospettive per stimare quanto bene un materiale intrappolerà la CO2. Essendo accurato, relativamente efficiente nei dati e interpretabile, offre un modo scalabile per concentrare gli esperimenti e le simulazioni più costose sui candidati più promettenti. Pur richiedendo ulteriori lavori per gestire meglio l’intera diversità dei MOF reali e query utente più naturali, il framework indica la via verso strumenti più intelligenti e consapevoli della letteratura che possono accelerare la scoperta di materiali avanzati per la cattura del carbonio e, in ultima analisi, contribuire a portare sul mercato tecnologie più pulite più rapidamente.
Citazione: You, H., Zhang, S., Du, L. et al. MOFMeld: a structure–language fusion framework for MOF property prediction in carbon capture. npj Artif. Intell. 2, 47 (2026). https://doi.org/10.1038/s44387-026-00106-1
Parole chiave: materiali per la cattura del carbonio, metal–organic frameworks, apprendimento automatico per i materiali, large language models, fusione struttura–linguaggio