Clear Sky Science · it
Analisi dello stato del reservoir distribuzionale per il rilevamento in tempo reale di anomalie in serie temporali multivariate
Perché individuare comportamenti anomali nei dati è importante
Dal mantenimento in salute dei veicoli spaziali al rilevamento di attacchi informatici e guasti alle apparecchiature, il nostro mondo dipende silenziosamente da sistemi che sorvegliano flussi di numeri e segnalano quando qualcosa sembra fuori posto. Queste misurazioni con marca temporale, note come serie temporali, possono cambiare rapidamente e i problemi possono durare solo pochi secondi prima di causare danni duraturi. La sfida è costruire rivelatori che apprendano in fretta, girino su hardware comune e reagiscano quasi istantaneamente quando qualcosa di insolito inizia — o smette — di accadere. Questo articolo presenta un nuovo metodo, chiamato MD-RS, che mira a diventare uno strumento pratico per il rilevamento di anomalie in tempo reale.
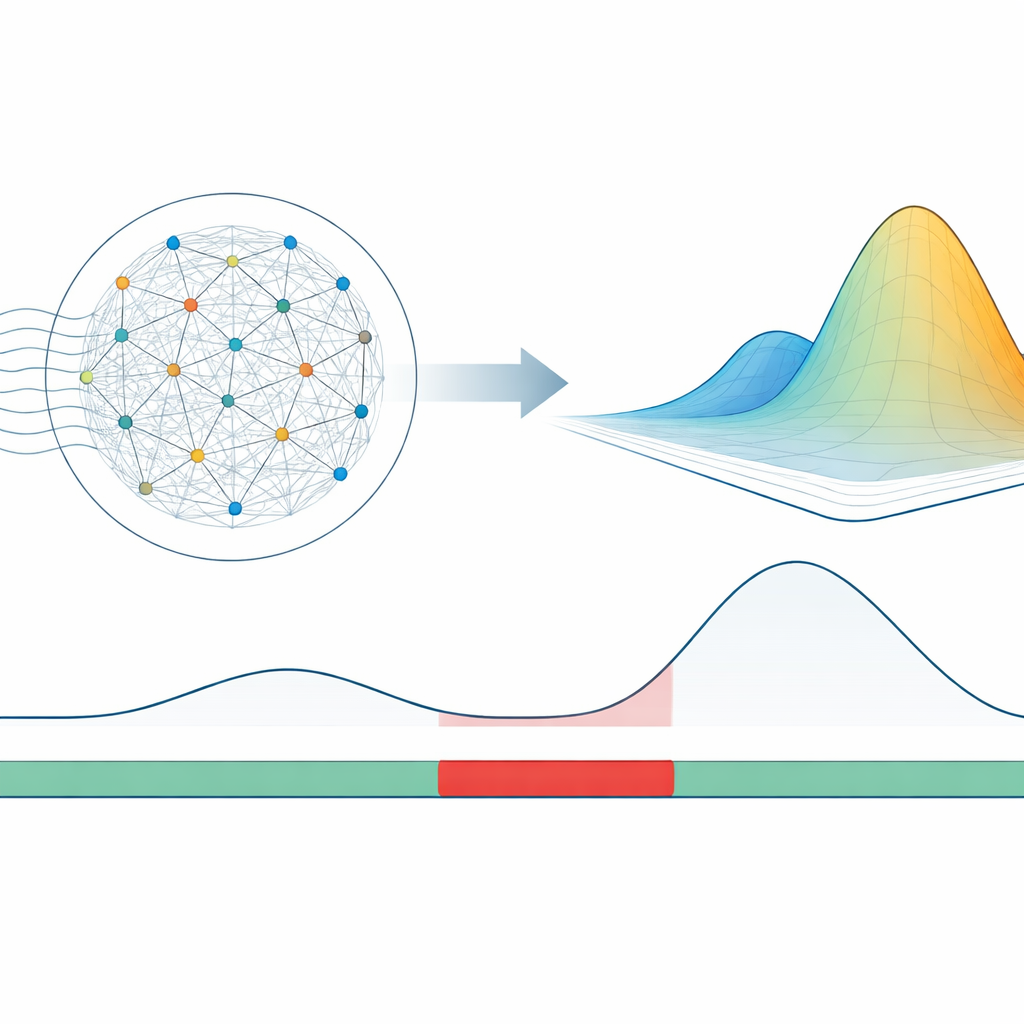
Un modo più rapido per ascoltare i flussi di dati
Molti strumenti esistenti analizzano i dati usando una finestra mobile: osservano l’ultimo blocco di punti, li trattano tutti allo stesso modo e decidono se quella finestra sia normale o sospetta. Questa idea semplice fallisce in pratica. Se la finestra è lunga, il rivelatore reagisce in ritardo quando il problema inizia e continua a segnalare a lungo dopo che il problema è terminato. Se la finestra è corta, reagisce rapidamente ma fatica con schemi che si sviluppano lentamente, come derive graduali o cambi di ritmo. Metodi di deep learning, come le moderne reti transformer, possono modellare schemi più ricchi ma spesso richiedono lunghi tempi di addestramento su potenti schede grafiche, rendendo difficile aggiornarli al volo quando il comportamento di un sistema cambia.
Una memoria dinamica al posto di una finestra rigida
Il metodo MD-RS sostituisce le finestre rigide con una memoria dinamica ispirata al cervello, nota come reservoir. Immaginate di alimentare un flusso di misurazioni in una rete fissa di unità semplici tutte connesse tra loro. All’arrivo di nuovi valori, questa rete si agita e si stabilizza in un pattern di attività che ricorda naturalmente eventi recenti dimenticando gradualmente il passato lontano. Poiché le connessioni interne non cambiano, va addestrata solo una piccola parte del modello, il che mantiene l’apprendimento veloce anche su computer standard. Questo “eco” mobile dei dati fornisce un ricco riassunto di quanto è accaduto di recente, senza dover scegliere manualmente una lunghezza di finestra fissa.
Misurare quanto gli stati si discostano dal normale
Invece di tentare di ricostruire il segnale originale e usare l’errore di ricostruzione come allarme, MD-RS osserva direttamente i pattern formati dal reservoir stesso. Durante l’addestramento, il metodo vede soltanto comportamenti normali e registra come l’attività del reservoir tende a raggrupparsi nel suo spazio ad alta dimensione. Quindi adatta una forma statistica semplice a questo ammasso, riassunta dalla posizione media e dalla sua dispersione. Quando arrivano nuovi dati, il metodo misura quanto l’attuale pattern del reservoir si è discostato da questa “nuvola” appresa di attività normale, usando una misura di distanza che tiene conto sia della posizione che della dispersione. Distanze grandi segnalano che il sistema è entrato in un regime non familiare. Poiché questo punteggio dipende dallo stato interno del reservoir piuttosto che da misurazioni grezze rumorose, varia in modo fluido nel tempo, facilitando la scelta di soglie stabili ed evitando allarmi nervosi.
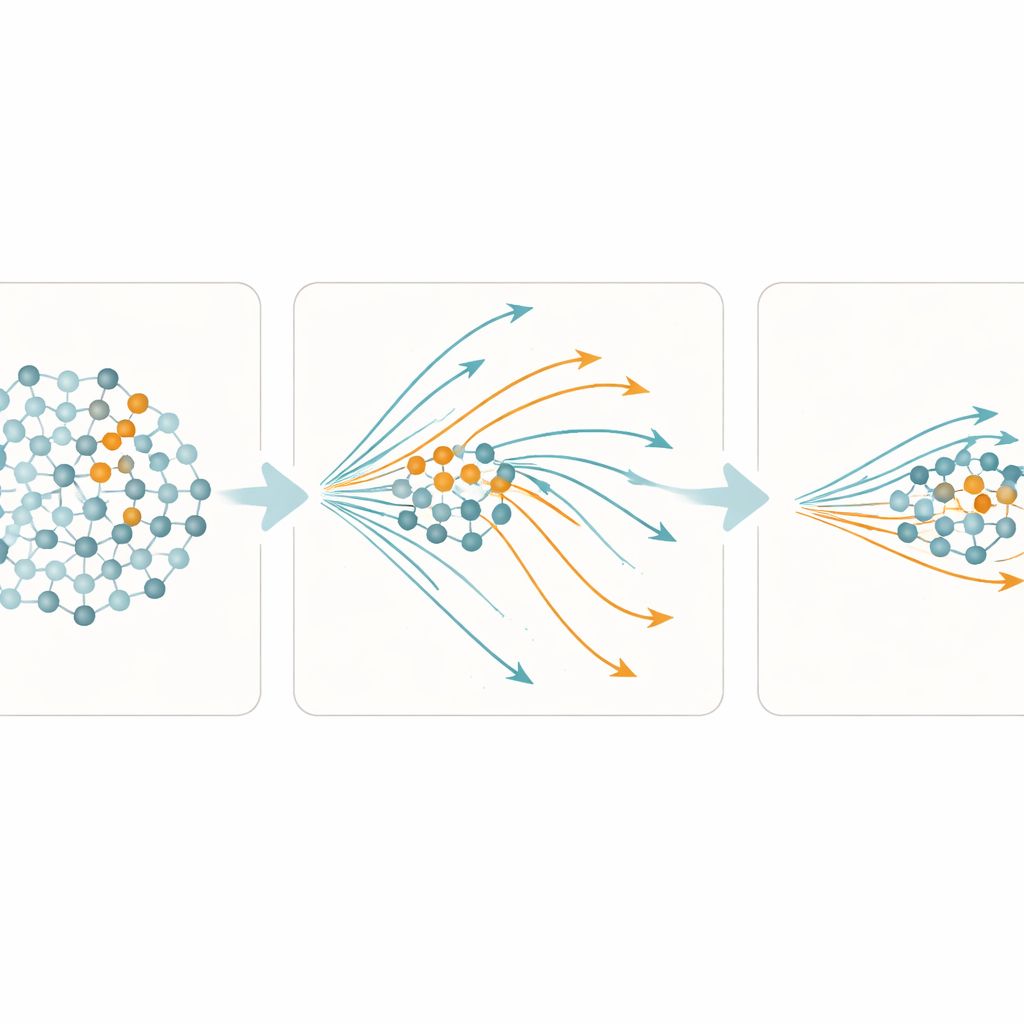
Combinare reazioni veloci e lente
Un’ulteriore variazione di MD-RS è mescolare due tipi di unità nel reservoir: la maggior parte risponde lentamente e mantiene una memoria lunga, mentre una frazione minore risponde rapidamente e dimentica altrettanto in fretta. Le unità lente sono adatte a catturare schemi estesi e tendenze, il che aiuta quando le anomalie si estendono su molti passi temporali o alterano ritmi a lungo termine. Le unità veloci, al contrario, permettono al sistema di tornare rapidamente alla normalità una volta che le condizioni si ristabiliscono, riducendo nettamente il tempo in cui il rivelatore rimane in allerta elevata dopo la fine di un evento. Scegliendo con cura il mix — circa nove unità lente per ogni unità veloce — gli autori mostrano che il modello può rilevare anomalie sia corte sia lunghe con alta precisione temporale, senza dover riaggiustare i parametri per ogni nuovo set di dati.
Dimostrare le prestazioni in tempo reale nella pratica
Per testare MD-RS, i ricercatori lo hanno confrontato con metodi classici basati su finestre, diversi sistemi avanzati di deep learning e altri approcci basati su reservoir su una vasta collezione di dataset di riferimento. Questi includono archivi univariati con frazioni minime di anomalie e flussi multivariati complessi provenienti da veicoli spaziali, server e impianti industriali. Hanno valutato non solo se le anomalie venivano rilevate, ma anche quanto velocemente i rivelatori reagivano all’inizio di un’anomalia e quanto presto si calmavano al suo termine, usando una metrica specializzata che premia un buon tempismo. Sulla maggior parte dei dataset e delle misure di valutazione, MD-RS ha eguagliato o superato le migliori tecniche esistenti, addestrandosi in secondi o minuti su una singola CPU — spesso ordini di grandezza più veloce rispetto ai modelli di deep learning che dipendono da GPU.
Cosa significa per i sistemi reali
In termini semplici, questo lavoro mostra che non serve una rete neurale massiccia e lenta da addestrare per ottenere un rilevamento di anomalie in tempo reale di alta qualità. Utilizzando una memoria dinamica fissa ed efficiente da simulare e monitorando come la sua attività interna si allontana dal comportamento normale appreso, MD-RS fornisce allarmi tempestivi e stabili, pratici da distribuire e aggiornare. La sua capacità di gestire sia guasti rapidi sia problemi a lenta evoluzione, unita a requisiti hardware modesti, suggerisce che potrebbe diventare un approccio di riferimento per il monitoraggio di tutto, dai sensori medicali e i centri dati ai veicoli spaziali e agli impianti industriali.
Citazione: Tamura, H., Fujiwara, K., Aihara, K. et al. Distributional reservoir state analysis for real-time anomaly detection in multivariate time series data. npj Artif. Intell. 2, 41 (2026). https://doi.org/10.1038/s44387-026-00090-6
Parole chiave: rilevamento anomalie serie temporali, monitoraggio in tempo reale, computazione a reservoir, distanza di Mahalanobis, dati in streaming