Clear Sky Science · it
Apprendimento few-shot per la classificazione di immagini SEM di nanoparticelle sintetizzate in modo green da Momordica cymbalaria
Piante, particelle minuscole e computer intelligenti
E se piante di uso comune potessero aiutare a produrre particelle minuscole per futuri farmaci, e programmi informatici intelligenti potessero classificare quelle particelle quasi quanto un esperto umano? Questo studio unisce chimica green e intelligenza artificiale usando estratti di una liana medicinale, Momordica cymbalaria, per creare nanoparticelle e poi allenare un modello compatto di riconoscimento delle immagini a distinguere diversi campioni usando solo poche immagini al microscopio.
Usare una pianta medicinale per ottenere particelle minute
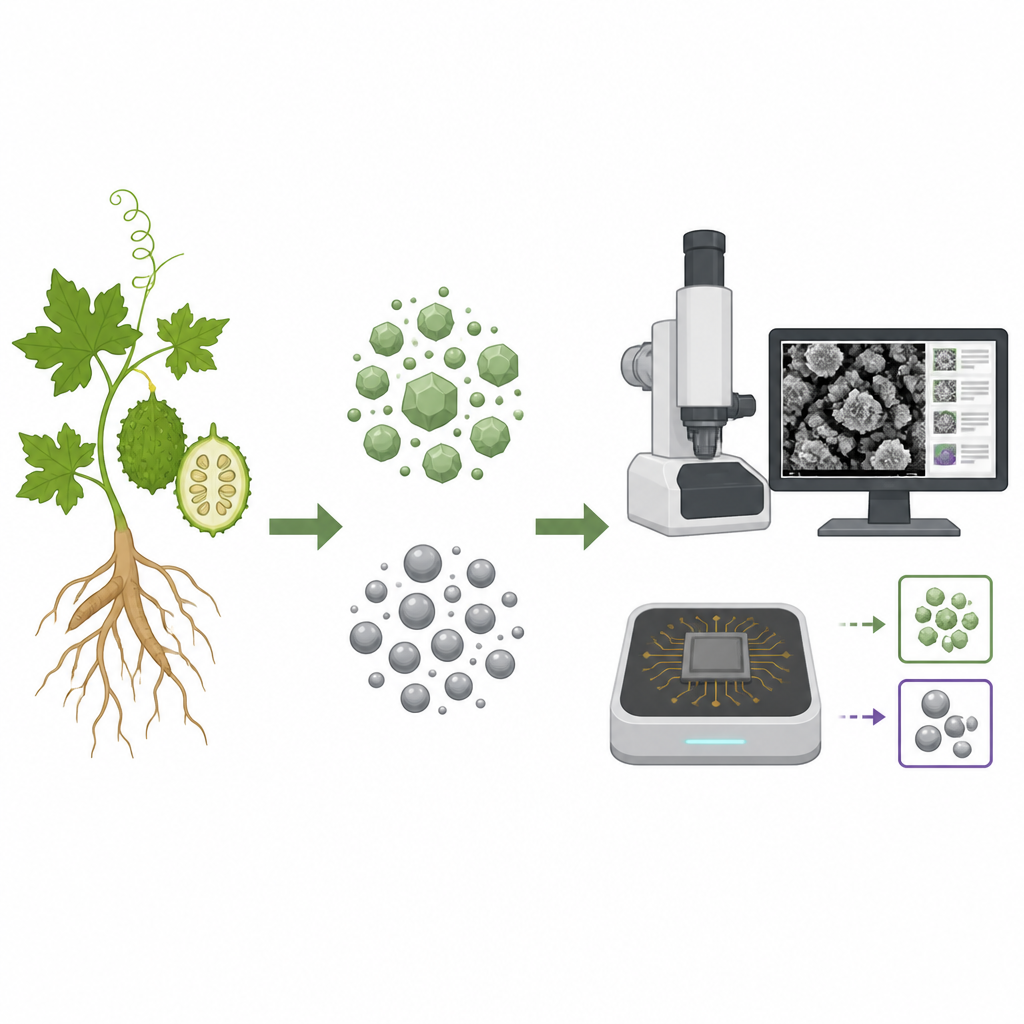
Invece di affidarsi a sostanze chimiche aggressive, i ricercatori hanno scelto una pianta già nota nella medicina tradizionale per il suo ruolo nel controllo della glicemia. Hanno usato radici e frutti come piccole “fabbriche” naturali per produrre due tipi di nanoparticelle: argento e carbonato di calcio. I composti della pianta hanno facilitato e stabilizzato queste reazioni, offrendo una via più pulita e potenzialmente più sicura rispetto ai metodi industriali convenzionali. Le polveri ottenute sono state esaminate con diversi strumenti per verificarne dimensione, forma e composizione chimica.
Osservare le particelle con luce ed elettroni
Per capire cosa avevano prodotto, il team ha fatto passare luce attraverso i campioni e ha registrato come venivano assorbiti diversi colori, un indizio che le strutture nanoscale si erano formate come previsto. Hanno inoltre usato un potente microscopio elettronico per ottenere immagini dettagliate in bianco e nero, mostrando che le particelle di carbonato di calcio erano per lo più rotonde e raggruppate, mentre quelle d’argento tendevano a formare aggregati più grandi e irregolari. Test aggiuntivi hanno confermato che i campioni ricchi di calcio contenevano principalmente calcio, ossigeno e carbonio, mentre nei campioni d’argento si rilevavano forti segnali di argento insieme a materiale organico proveniente dall’estratto vegetale. Nel complesso, queste misure indicano che il processo green ha funzionato bene per il carbonato di calcio, mentre la sintesi delle particelle d’argento richiede ulteriori ottimizzazioni.
Insegnare a un computer a leggere immagini al microscopio
Raccogliere migliaia di foto microscopiche è difficile e richiede tempo, specialmente in laboratori piccoli. Per affrontare questo problema, gli autori si sono rivolti a uno stile di intelligenza artificiale chiamato few-shot learning, progettato per funzionare con set di addestramento molto piccoli. Si sono concentrati su immagini da microscopio elettronico a scansione provenienti da quattro gruppi: argento da radici, argento da frutti, carbonato di calcio da radici e carbonato di calcio da frutti. Prima dell’addestramento, le immagini sono state pulite e ridimensionate e sono state create ulteriori varianti ruotandole e ribaltandole per aumentare il piccolo dataset. Due reti note per l’analisi delle immagini, MobileNetV2 e ResNet50, sono state adattate per trasformare ogni immagine in un’impronta numerica compatta.
Come il modello few-shot prende decisioni
Invece di inserire semplicemente tutte le immagini in un classificatore standard, il sistema ha appreso tramite piccoli compiti che simulano situazioni reali a bassa disponibilità di dati. In ogni compito vedeva solo pochi esempi per classe, li usava per trovare un “centro” tipico di quella classe e poi decideva dove collocare le immagini nuove. Le distanze tra immagini e questi centri venivano misurate in modo da tenere conto di quanto fosse diffusa ogni classe, rendendo più facili da cogliere differenze sottili. Ripetendo molti di questi episodi, il modello ha gradualmente appreso caratteristiche che separano i quattro gruppi di nanoparticelle, nonostante il dataset complessivo fosse esiguo.
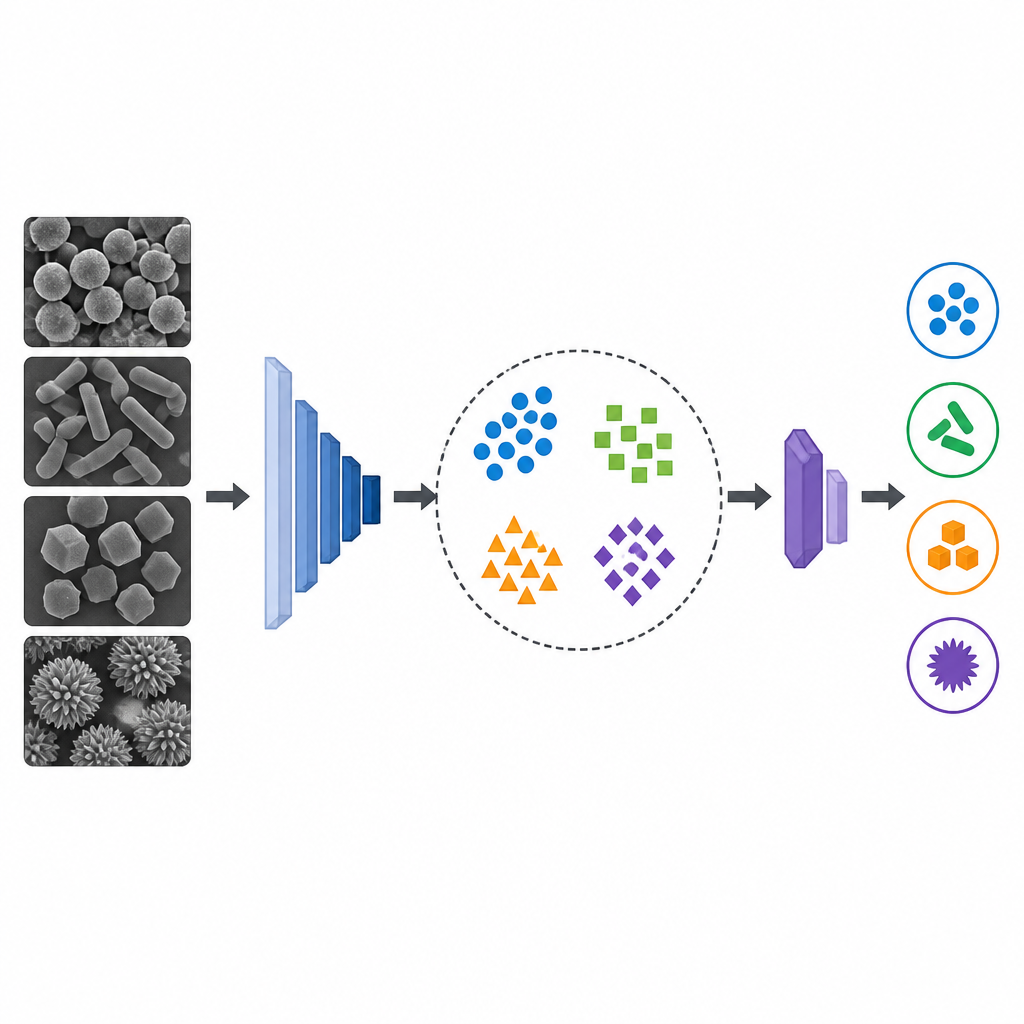
Un modello compatto con buone prestazioni
Quando i ricercatori hanno confrontato diversi setup di addestramento, l’approccio few-shot più avanzato, basato su MobileNetV2, ha dato i risultati migliori. Questa versione combinava addestramento episodico, centri di classe raffinati tramite clustering e una misura di distanza sensibile ai pattern nei dati. Ha raggiunto circa il 95 percento di accuratezza rimanendo sufficientemente leggero da poter funzionare su computer modesti o persino su dispositivi edge. Metodi più semplici che si basavano su transfer learning standard o misure di distanza basiche hanno fatto sensibilmente peggio, evidenziando il vantaggio di adattare la strategia di addestramento alle condizioni di pochi dati.
Cosa significa per il lavoro di laboratorio futuro
Per un non specialista, il messaggio chiave è che la produzione ecocompatibile di nanoparticelle può essere abbinata a un’analisi delle immagini intelligente ed efficiente in termini di dati per accelerare i flussi di lavoro di laboratorio. Mentre il metodo a base vegetale per il carbonato di calcio appare promettente e la via dell’argento necessita ancora di perfezionamenti, il quadro few-shot dimostra già che una classificazione affidabile delle particelle non richiede librerie di immagini enormi. Approcci come questo potrebbero un giorno aiutare piccoli gruppi di ricerca o cliniche a controllare rapidamente la qualità e il tipo di materiali nanoparticellari, favorendo un uso più sicuro e coerente in medicina e altre tecnologie.
Citazione: Venkatappa, U., Bhat, S., Dixit, M. et al. Few-shot learning for classification of SEM images from green-synthesized nanoparticles of Momordica cymbalaria. Sci Rep 16, 16185 (2026). https://doi.org/10.1038/s41598-026-46307-1
Parole chiave: nanotecnologia verde, few-shot learning, classificazione immagini SEM, Momordica cymbalaria, sintesi di nanoparticelle