Clear Sky Science · it
Un modello ibrido di deep learning per il rilevamento robusto ed efficiente delle malattie delle foglie usando ResNet50, PCA e SVM
Perché individuare presto le foglie malate è importante
Per molti agricoltori, un singolo focolaio di malattia delle piante può significare la perdita del reddito di un’intera stagione. Individuare precocemente la malattia osservando le foglie aiuta a proteggere i raccolti, ma farlo ad occhio è lento e spesso poco affidabile. Questo studio esplora come un sistema informatico progettato con cura possa analizzare foto di foglie e dire rapidamente se sono sane o malate, senza necessitare di computer potenti o di enormi quantità di dati di addestramento. L’obiettivo è uno strumento che un giorno possa girare su dispositivi modesti e supportare le decisioni nell’agricoltura di precisione.
Un modo più intelligente di leggere le foto delle foglie
I ricercatori si concentrano su una questione pratica: come ottenere un rilevamento delle malattie efficace dalle immagini delle foglie mantenendo basso il carico computazionale? Molti metodi moderni di riconoscimento delle immagini usano reti neurali molto grandi che richiedono hardware potente e lunghi tempi di addestramento. Questi possono funzionare bene nei laboratori di ricerca, ma sono difficili da distribuire su telefoni, piccoli computer agricoli o sensori a basso costo. Invece di inventare un algoritmo completamente nuovo, gli autori combinano componenti ben conosciuti in modo da bilanciare accuratezza, velocità e semplicità. Il loro sistema lavora su una collezione pubblica popolare di 38 tipologie di foglie sane e malate chiamata dataset PlantVillage.

Costruire una pipeline di rilevamento snella
La pipeline inizia con una preparazione semplice delle immagini. Le foto delle foglie sono ridimensionate a una forma standard e leggermente elaborate; in alcuni test viene applicata una fase opzionale di segmentazione del colore per evidenziare chiazze rossastre o brune che spesso segnalano malattia. Il cuore del sistema è una rete di immagini pre-addestrata nota come ResNet50, che ha già imparato a riconoscere molti pattern da una vasta raccolta di foto generiche. Qui ResNet50 non viene riaddestrata da zero; agisce come un lettore di feature “congelato”, trasformando ogni immagine di foglia in un lungo fingerprint numerico che cattura forme, colori e texture legati alla malattia.
Ridurre i dati mantenendo il significato
Quei fingerprint sono molto lunghi e contengono informazioni ridondanti, il che rallenta l’elaborazione successiva e può portare a overfitting, quando un modello memorizza i dati di addestramento invece di apprendere regole generali. Per affrontare questo, il team applica l’Analisi delle Componenti Principali (PCA), un metodo classico che comprime il lungo fingerprint in uno molto più corto conservando la maggior parte della variazione significativa. Questo passaggio riduce drasticamente quanto il computer deve memorizzare ed elaborare. I fingerprint compatti vengono poi passati a una Support Vector Machine, un classificatore tradizionale che traccia confini tra i diversi tipi di malattia e le foglie sane in questo spazio ridotto.
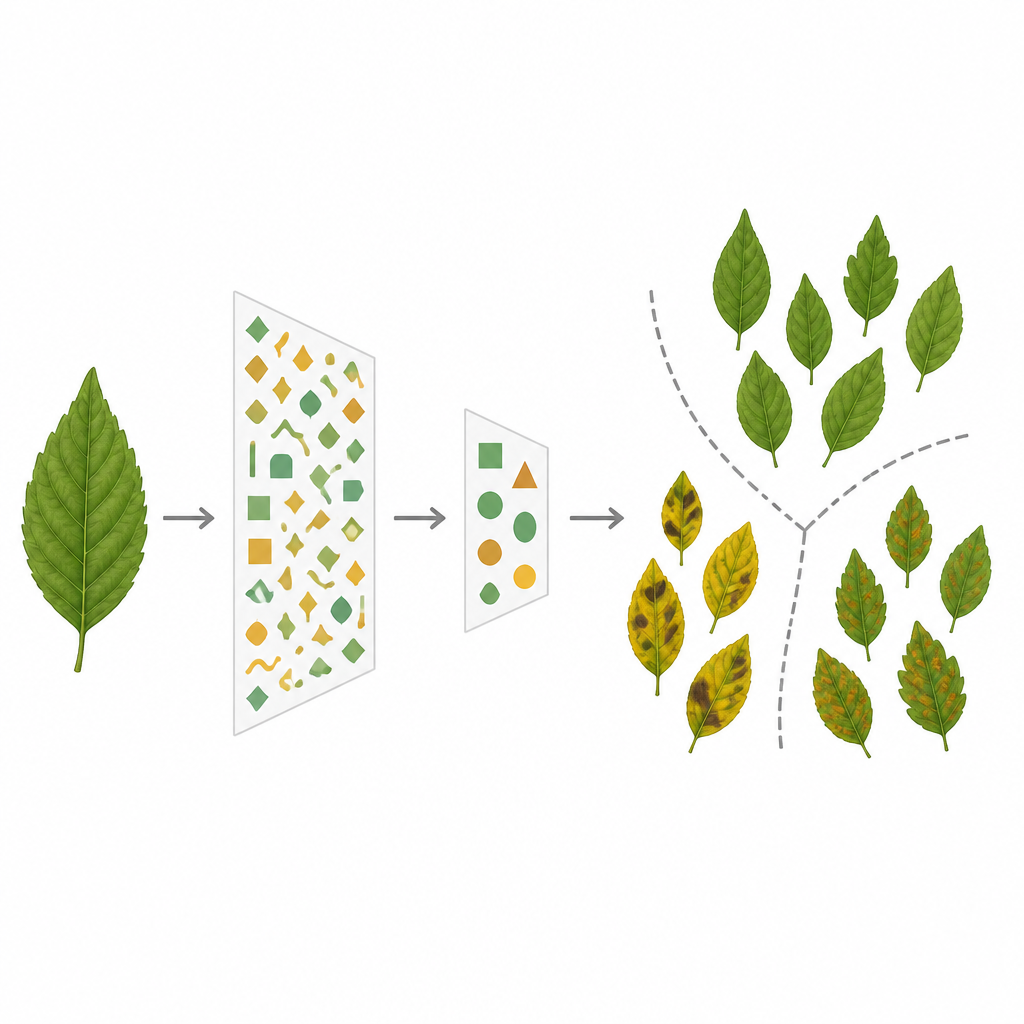
Quanto bene funziona il sistema
Il progetto ibrido è stato testato in diversi modi. Usando una singola suddivisione train–validation, il sistema ha raggiunto quasi il 99% di accuratezza sui dati di addestramento e circa l’89% sulle immagini di validazione, con punteggi dettagliati per precisione, recall e F1 su tutte le 38 classi. Per verificarne l’affidabilità, gli autori hanno eseguito una validazione incrociata a cinque fold, in cui i dati vengono ripetutamente rimescolati in nuovi set di addestramento e test. Questo ha prodotto un’accuratezza media di circa il 98,6%, suggerendo che il metodo è stabile e non dipende da una singola suddivisione favorevole. Uno studio di ablazione, che disattiva o attiva componenti, ha mostrato che la combinazione completa di feature ResNet50, riduzione di dimensionalità e classificatore SVM supera configurazioni più semplici che saltano la PCA o usano lo strato finale di una rete neurale.
Limitazioni, robustezza e uso futuro sul campo
Lo studio esplora anche il comportamento del sistema in condizioni più realistiche simulando variazioni di illuminazione e aggiungendo rumore alle immagini. La performance è rimasta solida con variazioni di luminosità ma è diminuita quando è stato aggiunto rumore casuale, evidenziando una debolezza che lavori futuri potrebbero affrontare. La segmentazione opzionale basata sul colore, che evidenzia macchie rosse o brune, ha avuto solo un impatto minore sull’accuratezza complessiva per questo dataset pulito in stile laboratorio, quindi è trattata come una fase interpretabile ma non essenziale. È importante sottolineare che gli autori ribadiscono come i loro esperimenti utilizzino immagini controllate, non foto caotiche scattate sul campo, e che le prestazioni nel mondo reale devono ancora essere testate.
Cosa significa per gli agricoltori e gli strumenti
In termini semplici, questo lavoro mostra che una combinazione ben tarata di strumenti esistenti può riconoscere molte malattie delle foglie con alta accuratezza mantenendo sotto controllo l’uso di memoria e il calcolo. Congelando una rete di immagini potente, riducendo le sue uscite e affidandosi a un classificatore snello, il framework offre un progetto per sistemi di rilevamento delle malattie che potrebbero un giorno funzionare su hardware modesto nelle aziende agricole con risorse limitate. Non pretende di risolvere tutte le sfide del campo, ma pone una base pratica per costruire strumenti economici e affidabili di scansione delle foglie a supporto dell’agricoltura di precisione.
Citazione: Begum, S., E, N. & N. N., S. A hybrid deep learning model for robust and efficient plant leaf disease detection using ResNet50, PCA, and SVM. Sci Rep 16, 15805 (2026). https://doi.org/10.1038/s41598-026-46085-w
Parole chiave: rilevamento delle malattie delle piante, analisi delle immagini delle foglie, deep learning, agricoltura di precisione, modello ibrido