Clear Sky Science · it
Metriche di somiglianza temporale basate sulla distanza per la selezione adattiva dei canali in framework BCI multimodali EEG-fNIRS
Aiutare i cervelli a parlare con le macchine
Per le persone che non possono muoversi o parlare, le interfacce cervello–computer promettono un modo per comunicare usando solo il pensiero. Ma trasformare i segnali cerebrali grezzi in comandi di controllo affidabili è come cercare di tenere una conversazione in uno stadio affollato: ci sono molti dati e ancora più rumore. Questo studio presenta un metodo semplice ma efficace per snellire quei flussi di dati in modo che i computer possano rispondere più rapidamente, senza perdere ciò che il cervello sta cercando di comunicare.
Perché troppi fili rallentano
I moderni sistemi cervello–computer spesso utilizzano due tipi di sensori non invasivi sul cuoio capelluto. L’elettroencefalografia (EEG) registra minuscoli impulsi elettrici dai neuroni, mentre la spettroscopia funzionale nel vicino infrarosso (fNIRS) monitora i cambiamenti di sangue e ossigenazione legati all’attività cerebrale. Insieme formano un sistema “ibrido” più accurato di ciascuno separato, ma con un costo: dozzine di sensori su registrazioni prolungate producono dataset enormi e difficili da gestire. Cercare per tentativi il sottoinsieme ottimale di sensori richiederebbe di testare combinazioni in quantità astronomiche, ben oltre ciò che i computer attuali possono gestire in tempo reale.
Capire quando i segnali vicini dicono la stessa cosa
Gli autori affrontano questo problema con un’idea intuitiva: se due sensori vicini sulla testa raccontano quasi la stessa storia nel tempo, non hai bisogno di entrambi. Accoppiano elettrodi adiacenti e misurano matematicamente quanto differiscono i loro segnali temporali. Se due canali divergono in modo marcato, entrambi vengono mantenuti perché probabilmente contengono informazioni distinte. Se sono molto simili, uno viene scartato come ridondante. Per decidere dove tracciare questa soglia, il team confronta la distanza di ogni coppia con una soglia complessiva, calcolata o dalla media (Mean) o dal valore centrale (Median) di tutte le distanze.
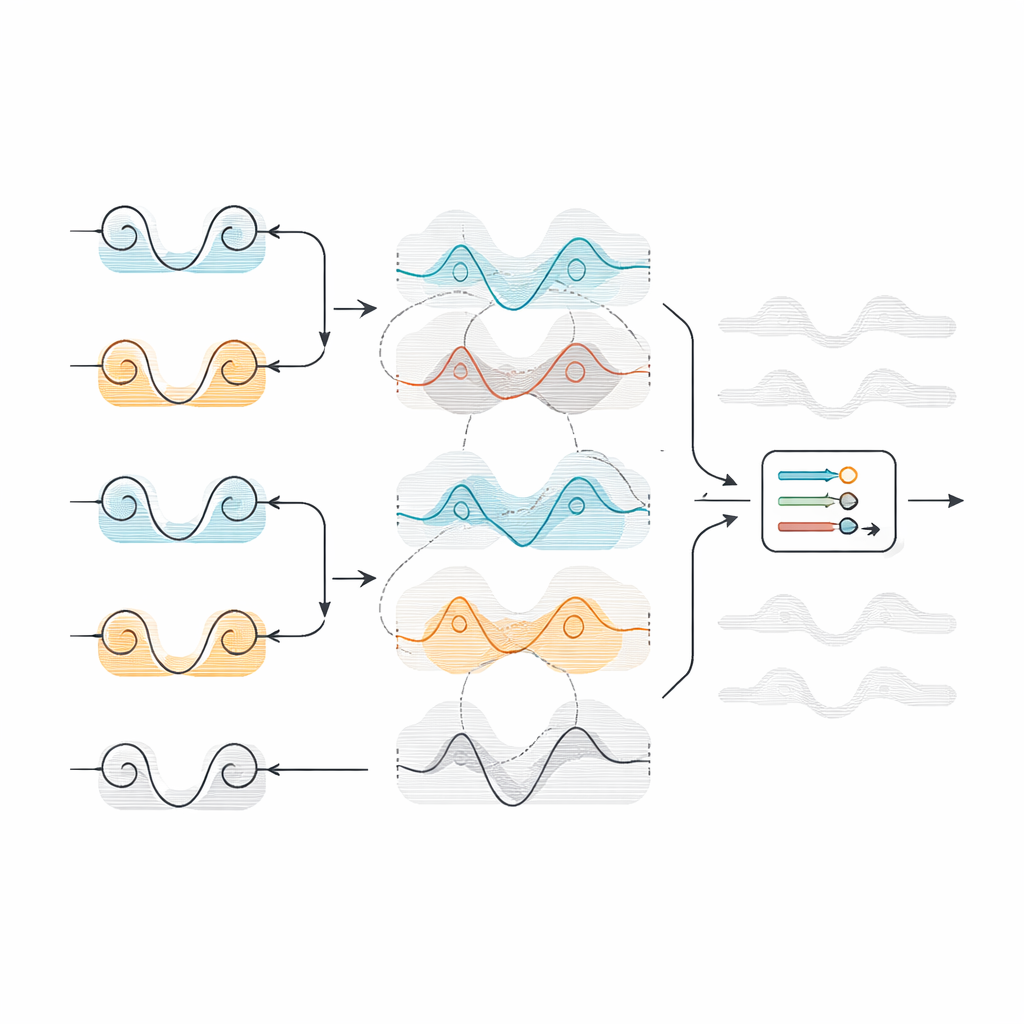
Testare la scorciatoia su diversi compiti mentali
Per verificare se questa scorciatoia funziona davvero, i ricercatori l’hanno applicata a due dataset pubblici. Uno conteneva registrazioni EEG e fNIRS mentre i volontari immaginavano di muovere le mani o risolvevano problemi di aritmetica mentale. L’altro era il classico compito “speller”, in cui gli utenti si concentrano su lettere lampeggianti e un’onda cerebrale distinta, la risposta P300, rivela la loro scelta. Dopo aver pulito i segnali, il team ha estratto caratteristiche statistiche semplici da ciascun canale, oppure ha utilizzato finestre temporali brevi direttamente, e poi ha addestrato tre noti strumenti di machine learning per classificare i compiti. Hanno confrontato le prestazioni con e senza il metodo di riduzione dei canali.
Mantenere le aree cerebrali importanti
Il metodo ha ridotto il numero di canali di oltre la metà in tutti i compiti: approssimativamente 15–17 su 30 canali EEG e circa 18–24 su 36 canali fNIRS nel primo dataset, e solo circa 31–40 su 64 canali EEG nello speller. Crucialmente, l’accuratezza è rimasta uguale o è persino migliorata. Per lo speller, l’accuratezza ha raggiunto circa il 94% con un classificatore leggero; per i compiti ibridi di aritmetica, è salita attorno al 73%. Quando il team ha tracciato la frequenza con cui ciascun sensore veniva mantenuto, i canali sopravvissuti si sono allineati con quanto prevedibile dalla neuroscienza: aree motorie per l’immaginazione del movimento, regioni prefrontali per l’aritmetica e zone parieto-occipitali per la risposta P300. In altre parole, l’algoritmo ha individuato automaticamente regioni funzionalmente importanti senza ricevere indicazioni sulla loro posizione.
Scegliere il modo giusto per gestire il rumore
Un elemento importante dello studio è il modo in cui la soglia viene impostata. Usare la distanza mediana (Median), meno influenzata dai valori estremi, ha spesso prodotto risultati più stabili e talvolta un’accuratezza superiore rispetto all’uso della media (Mean), specialmente per compiti rumorosi o ad alta domanda come l’aritmetica mentale e lo speller P300. I test statistici hanno mostrato che questa scelta non è solo cosmetica: per quei compiti, le soglie basate sulla Median hanno chiaramente superato quelle basate sulla Mean, mentre per l’immaginazione del movimento la differenza è stata minore. Allo stesso tempo, i modelli che hanno utilizzato i set di canali ridotti sono stati in grado di prendere decisioni nell’ordine di un decimo o un quinto di secondo, un’accelerazione significativa rispetto ai diversi secondi richiesti quando si includevano tutti i canali.
Cosa significa per le future interfacce cerebrali
In termini pratici, questo lavoro dimostra che è possibile scartare oltre la metà dei sensori in un sistema ibrido EEG–fNIRS, mantenere quelli più informativi e raggiungere comunque la stessa accuratezza o una migliore — il tutto riducendo i tempi di reazione a un vero intervallo in tempo reale. Facendo affidamento su calcoli di distanza semplici invece di complessi schemi di ottimizzazione o deep learning, il framework proposto è più facile da implementare su dispositivi portatili con potenza di calcolo limitata. Per le future interfacce cervello–computer destinate a uscire dal laboratorio e entrare nelle case, nelle cliniche o persino in dispositivi indossabili, questo tipo di potatura intelligente dei canali potrebbe essere un passo chiave per rendere la tecnologia controllata dal pensiero pratica e ampiamente accessibile.
Citazione: Alhudhaif, A. Distance-based temporal similarity metrics for adaptive channel selection in multi-modal EEG-fNIRS BCI frameworks. Sci Rep 16, 13702 (2026). https://doi.org/10.1038/s41598-026-44052-z
Parole chiave: interfaccia cervello-computer, EEG, fNIRS, selezione dei canali, speller P300