Clear Sky Science · it
Trasformatore per apprendimento consapevole delle allucinazioni e ottimizzazione della latenza (HALL-OPT) per l’intelligenza in tempo reale ai margini
Perché un’AI più veloce e più affidabile conta
I dispositivi di uso quotidiano stanno diventando silenziosamente più intelligenti, dai sensori di fabbrica e i monitor ospedalieri alle automobili e agli apparecchi domestici. Molti di questi sistemi si basano su modelli linguistici — lo stesso tipo di intelligenza artificiale dietro i chatbot moderni — per leggere istruzioni, rispondere a domande o riassumere rapporti. Ma due problemi ostacolano l’adozione: questi modelli sono lenti e richiedono molta energia, e talvolta “allucinano” affermazioni convincenti ma false. Questo articolo presenta HALL-OPT, una riprogettazione dei modelli linguistici basati su transformer che mira a renderli sia più veloci sia più affidabili, così da poter funzionare in sicurezza su dispositivi edge piccoli e a basso consumo invece che in lontani data center.
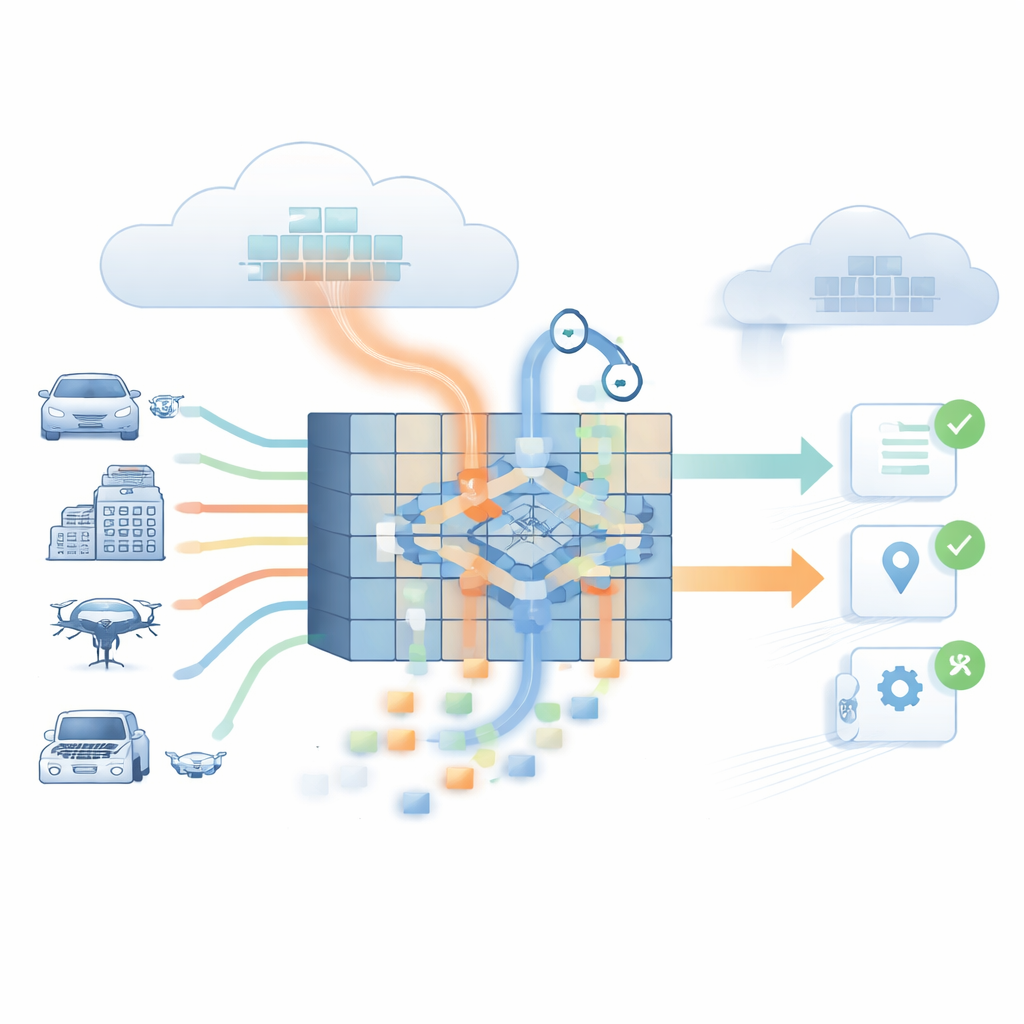
La sfida dei dispositivi intelligenti ai margini
La maggior parte dei modelli linguistici ad alte prestazioni risiede nel cloud, dove possono sfruttare grandi quantità di potenza di calcolo. Ciò li rende difficili da usare in contesti in cui decisioni rapide sono vitali e le connessioni di rete sono imperfette o costose, come veicoli autonomi, robot industriali o dispositivi medici al letto del paziente. Quando tali sistemi inviano dati al cloud e attendono una risposta, ritardi anche di poche centinaia di millisecondi possono essere inaccettabili. Allo stesso tempo, modelli più leggeri che possono girare sui dispositivi edge spesso rispondono più velocemente ma sono più inclini a inventare fatti o a interpretare erroneamente le informazioni. Lo studio mostra che ciò genera un compromesso: bassa incidenza di allucinazioni di solito comporta alta latenza, mentre bassa latenza spesso significa più allucinazioni, lasciando un vuoto per un’intelligenza edge affidabile e in tempo reale.
Un progetto unificato invece di rimedi separati
La ricerca esistente di solito tratta affidabilità ed efficienza come due obiettivi separati. Alcuni metodi si concentrano sul rilevamento delle allucinazioni controllando le risposte con database esterni o eseguendo più passaggi del modello, il che aggiunge tempo e consumo energetico. Altri metodi riducono i modelli tramite pruning, quantizzazione o distillazione della conoscenza, rendendoli più veloci ma a volte meno accurati e meno affidabili. HALL-OPT percorre una strada diversa: integra la consapevolezza delle allucinazioni direttamente nel funzionamento interno del modello e utilizza le stesse informazioni per decidere cosa calcolare e cosa saltare. Invece di aggiungere controlli esterni o ridurre la rete in modo indiscriminato, coordina affidabilità e velocità in un unico framework pensato per l’hardware edge.
Come il sistema filtra contenuti rischiosi
Al centro di HALL-OPT c’è un modulo di attenzione consapevole delle allucinazioni che monitora come il modello distribuisce il proprio focus tra le parole e quanto sia sicuro nelle sue predizioni. Quando l’attenzione è dispersa, la fiducia è bassa o il significato di un token confligge con il contesto circostante, al token viene assegnato un punteggio di “rischio” più elevato. Un rivelatore a doppio flusso segnala quindi questi pezzi rischiosi come potenziali allucinazioni. Il modello usa questi segnali per guidare una fase di pruning dinamico: i token che sono sia di scarso valore sia ad alto rischio vengono rimossi, mentre i token importanti e affidabili vengono mantenuti. Questo riduce il numero di elementi che il modello deve processare ad ogni layer, tagliando il costo quadratico dell’attenzione senza perdere il nucleo del significato testuale.
Imballare un grande modello in uno piccolo ed efficiente
Per trasferire capacità elevate in un pacchetto più piccolo, HALL-OPT applica la distillazione della conoscenza, dove un grande modello “insegnante” allena un modello “studente” compatto. Diversamente dalla distillazione standard, lo studente non viene insegnato solo a riprodurre le risposte dell’insegnante, ma anche a imitare la sua percezione di quando le uscite potrebbero essere sbagliate. Un addestramento supplementare spinge lo studente a evitare predizioni troppo sicure e inclini all’allucinazione. Infine, uno strato di ottimizzazione per l’edge prepara il modello per l’aritmetica a bassa precisione, convertendo i pesi in valori a 8 bit e ristrutturando i calcoli per adattarli ai dispositivi edge reali come le schede NVIDIA Jetson e la TPU Coral di Google. Questa combinazione preserva gran parte dell’accuratezza originale riducendo nettamente uso della memoria, consumo energetico e tempi di risposta.

Impatto reale su velocità, energia e sicurezza
I test su due benchmark impegnativi — uno per question answering con domande ingannevolmente non rispondibili e un altro per il riassunto di notizie — mostrano che HALL-OPT rileva le allucinazioni con circa il 94% di accuratezza e mantiene le prestazioni sui compiti vicino a quelle di un modello BERT standard. Contemporaneamente riduce la latenza di inferenza di circa due terzi e abbassa il consumo energetico di circa il 40% o più in media su carichi di lavoro realistici. Sui dispositivi edge risponde spesso in meno di 50 millisecondi e utilizza significativamente meno memoria. Test di stress su più piattaforme e scenari in stile industriale, dalle fabbriche intelligenti ai monitor sanitari, confermano che il sistema mantiene tempi prevedibili e un favorevole rapporto “inferenze per watt”, rendendolo adatto all’uso continuo e in tempo reale.
Cosa significa per l’AI di tutti i giorni
Per i non specialisti, il messaggio chiave è che non dobbiamo scegliere tra un’AI veloce e un’AI affidabile su dispositivi piccoli. Insegnando al modello a riconoscere i propri punti deboli e lasciando che quella consapevolezza guidi quanto calcola, HALL-OPT fornisce risposte che sono sia rapide sia meno propense a essere inventate. Questo lo rende una base promettente per future applicazioni edge in cui risposte errate o reazioni lente potrebbero avere conseguenze serie, come il controllo di un veicolo, la gestione di macchinari industriali o il segnalare cambiamenti critici nelle condizioni di un paziente.
Citazione: Algawiaz, D. Hallucination-aware learning and latency optimization transformer (HALL-OPT) for real-time edge intelligence. Sci Rep 16, 12245 (2026). https://doi.org/10.1038/s41598-026-42981-3
Parole chiave: edge AI, rilevamento delle allucinazioni, modelli transformer, inferenza in tempo reale, calcolo a basso consumo energetico