Clear Sky Science · fr
Transformeur optimisé pour la latence et conscient des hallucinations (HALL-OPT) pour l’intelligence embarquée en temps réel
Pourquoi une IA plus rapide et plus fiable est importante
Les appareils du quotidien deviennent discrètement plus intelligents, des capteurs d’usine et moniteurs hospitaliers aux voitures et aux objets domestiques. Nombre de ces systèmes reposent sur des modèles de langage — le même type d’IA derrière les chatbots modernes — pour lire des instructions, répondre à des questions ou résumer des rapports. Mais deux problèmes se posent : ces modèles sont lents et énergivores, et ils « hallucinent » parfois des assertions convaincantes mais fausses. Cet article présente HALL-OPT, une refonte des modèles de langage basés sur les transformeurs qui vise à les rendre à la fois plus rapides et plus fiables afin qu’ils puissent s’exécuter en toute sécurité sur de petits dispositifs à faible consommation plutôt que dans des centres de données éloignés.
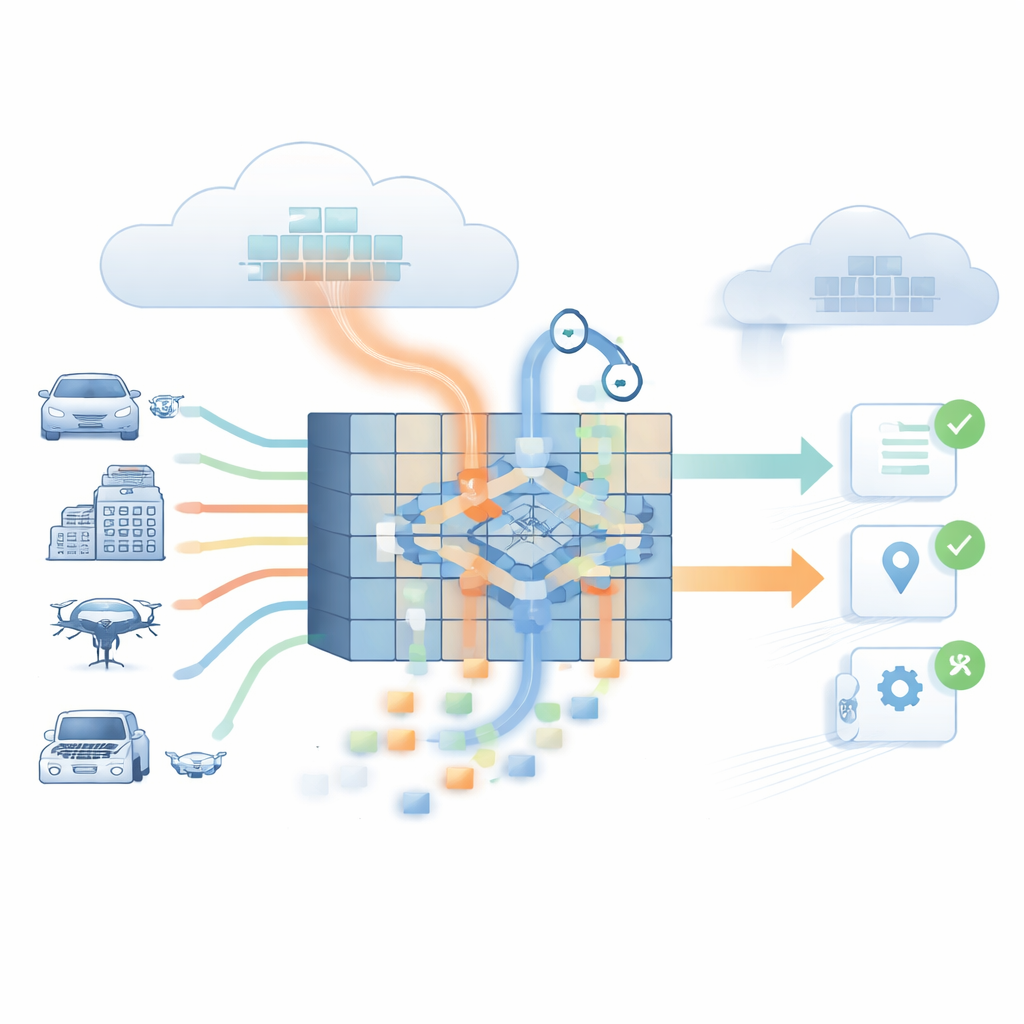
Le défi des appareils intelligents en périphérie
La plupart des modèles de langage performants résident dans le cloud, où ils peuvent exploiter d’importantes ressources de calcul. Cela les rend difficiles à utiliser dans des contextes où des décisions rapides sont vitales et où les connexions réseau sont imparfaites ou coûteuses, comme les véhicules autonomes, les robots industriels ou les dispositifs médicaux au chevet. Lorsque ces systèmes envoient des données au cloud et attendent une réponse, des délais de quelques centaines de millisecondes peuvent être inacceptables. Dans le même temps, les modèles allégés qui tiennent sur des appareils en périphérie répondent souvent plus vite mais ont davantage tendance à inventer des faits ou à mal interpréter l’information. L’étude montre que cela crée un compromis : une faible hallucination s’accompagne généralement d’une latence élevée, tandis qu’une faible latence signifie souvent plus d’hallucinations, laissant un vide pour une intelligence embarquée, fiable et en temps réel.
Une conception unifiée au lieu de correctifs séparés
Les travaux existants traitent généralement la fiabilité et l’efficacité comme deux objectifs distincts. Certaines méthodes se concentrent sur la détection des hallucinations en vérifiant les réponses contre des bases de données externes ou en effectuant plusieurs passes du modèle, ce qui ajoute du temps et de la consommation d’énergie. D’autres méthodes réduisent la taille des modèles par élagage, quantification ou distillation de connaissances, les rendant plus rapides mais parfois moins précis et moins dignes de confiance. HALL-OPT emprunte une voie différente : il intègre la conscience des hallucinations directement dans le fonctionnement interne du modèle et utilise cette même information pour décider ce qu’il faut calculer et ce qu’il peut omettre. Plutôt que d’ajouter des vérifications externes ou de tailler aveuglément le réseau, il coordonne fiabilité et vitesse dans un seul cadre adapté au matériel périphérique.
Comment le système filtre les contenus à risque
Au cœur de HALL-OPT se trouve un module d’attention conscient des hallucinations qui surveille comment le modèle répartit son attention sur les mots et à quel point il est confiant dans ses prédictions. Lorsque l’attention est dispersée, que la confiance est faible ou que le sens d’un token entre en contradiction avec le contexte environnant, le token reçoit un score de « risque » plus élevé. Un détecteur à double voie identifie ensuite ces éléments risqués comme des hallucinations potentielles. Le modèle utilise ces signaux pour piloter une étape d’élagage dynamique : les tokens à faible valeur et à haut risque sont supprimés, tandis que les tokens importants et dignes de confiance sont conservés. Cela réduit le nombre d’éléments que le modèle doit traiter à chaque couche, diminuant le coût quadratique lourd de l’attention sans perdre le sens essentiel du texte.
Intégrer un grand modèle dans un petit modèle efficace
Pour condenser un comportement puissant dans un format plus petit, HALL-OPT applique la distillation de connaissances, où un grand modèle « enseignant » entraîne un modèle « étudiant » compact. Contrairement à la distillation standard, l’étudiant apprend non seulement à reproduire les réponses de l’enseignant, mais aussi à imiter sa sensibilité aux sorties susceptibles d’être erronées. Un entraînement supplémentaire encourage l’étudiant à éviter les prédictions trop confiantes et propices aux hallucinations. Enfin, une couche d’optimisation pour la périphérie prépare le modèle aux calculs en basse précision, convertit ses poids en valeurs 8 bits et restructure les opérations pour correspondre aux dispositifs réels en périphérie tels que les cartes NVIDIA Jetson et le TPU Coral de Google. Cette combinaison préserve la majeure partie de la précision d’origine tout en réduisant fortement l’utilisation de mémoire, la consommation d’énergie et le temps de réponse.

Impact réel sur la vitesse, l’énergie et la sécurité
Des tests sur deux benchmarks exigeants — l’un pour la réponse à des questions incluant des questions sournoises non répondables, et l’autre pour le résumé d’articles — montrent que HALL-OPT détecte les hallucinations avec environ 94 % de précision et maintient les performances des tâches proches d’un modèle BERT standard. Parallèlement, il réduit la latence d’inférence d’environ deux tiers et diminue la consommation d’énergie d’environ 40 % ou plus en moyenne sur des charges réalistes. Sur les appareils en périphérie, il répond souvent en moins de 50 millisecondes et utilise sensiblement moins de mémoire. Des tests de résistance sur de nombreuses plateformes et scénarios de type industriel, des usines intelligentes aux moniteurs de santé, confirment que le système conserve des temps d’exécution prévisibles et un taux favorable d’« inférences par watt », ce qui le rend adapté à une utilisation continue et en temps réel.
Ce que cela signifie pour l’IA du quotidien
Pour le grand public, le message essentiel est que l’on n’a pas à choisir entre une IA rapide et une IA fiable sur de petits appareils. En apprenant au modèle à reconnaître ses propres points faibles et en laissant cette conscience guider la quantité de calcul réalisée, HALL-OPT fournit des réponses à la fois rapides et moins susceptibles d’être fabriquées. Cela en fait une base prometteuse pour les futures applications en périphérie où des réponses erronées ou des réactions lentes pourraient avoir des conséquences graves, comme la conduite d’un véhicule, le contrôle de machines industrielles ou la détection de changements critiques dans l’état d’un patient.
Citation: Algawiaz, D. Hallucination-aware learning and latency optimization transformer (HALL-OPT) for real-time edge intelligence. Sci Rep 16, 12245 (2026). https://doi.org/10.1038/s41598-026-42981-3
Mots-clés: IA en périphérie, détection des hallucinations, modèles transformeurs, inférence en temps réel, informatique économe en énergie