Clear Sky Science · it
Un metodo di suddivisione delle aree di intervento antincendio forestale basato sull’algoritmo SW-DBSCAN
Perché le linee di fuoco più intelligenti contano
Quando scoppia un grande incendio boschivo, i vigili del fuoco corrono non solo contro le fiamme ma anche contro la confusione. Un unico anello di fuoco può estendersi per molti chilometri, con alcune sezioni che avanzano rapidamente, altre che si estinguono e alcune che minacciano abitazioni o linee elettriche. Decidere dove inviare ogni squadra è un enigma di vita o di morte. Questo studio presenta un nuovo modo per suddividere automaticamente quel bordo di fuoco lungo e mutevole in aree operative pratiche, così da poter inviare persone, elicotteri e droni nel posto giusto al momento giusto.
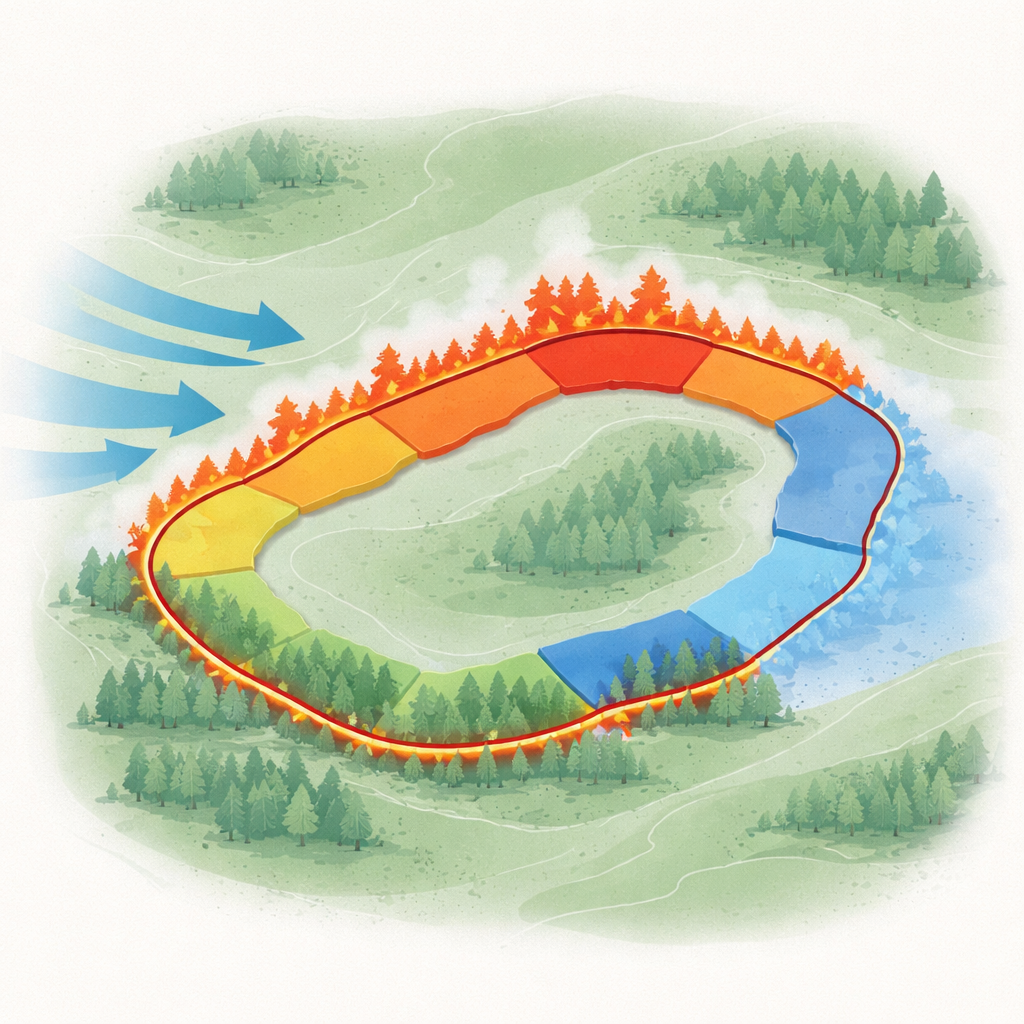
Trasformare un incendio in movimento in pezzi gestibili
Gli autori si concentrano su un passaggio chiave nella risposta agli incendi: dividere il fronte del fuoco in un insieme di aree operative continue, ciascuna con condizioni simili. Lungo qualsiasi linea di fuoco, alcune parti sono più pericolose di altre. La testa del fuoco avanza più velocemente con fiamme intense, la coda si muove più lentamente e i fianchi stanno nel mezzo. Inoltre, possono esserci case, siti culturali o cedui di valore che devono essere protetti per primi. L’obiettivo è raggruppare punti vicini sulla linea di fuoco che condividono comportamento, terreno, meteo e bisogni di protezione simili, in modo che ogni gruppo diventi un incarico coerente per una squadra antincendio.
Dal dato grezzo del simulatore a una mappa intelligente
Per testare il metodo, i ricercatori hanno utilizzato una simulazione dettagliata dell’incendio per la regione di Oak Knoll nella contea di Napa, California. Hanno estratto dieci linee di fuoco separate, per un totale di circa 282 chilometri, dal simulatore di incendi FlamMap. Per ogni punto lungo queste linee hanno compilato una descrizione in dieci parti che includeva direzione e velocità del vento, intensità del fuoco, orientamento e pendenza del terreno, densità della chioma forestale, tipo di combustibile, se il fuoco si muoveva in salita, se quel punto era testa, coda o fianco, e se era presente un obiettivo di protezione chiave. Tutti questi valori sono stati scalati in un intervallo comune in modo che nessun fattore dominasse solo perché espresso con numeri più grandi.
Uno strumento di clustering su misura per il fronte di fuoco
Il fulcro del lavoro è una tecnica di clustering migliorata chiamata SW‑DBSCAN. Il DBSCAN standard è un metodo popolare per trovare gruppi densi di punti dati ignorando il rumore sparso, ma presenta due limiti in questo contesto: può unire parti distanti della linea di fuoco che per caso hanno numeri simili e non considera le posizioni chiave — come una testa di fuoco o un edificio protetto — come particolarmente importanti. La nuova versione introduce due modifiche. Primo, utilizza una “finestra scorrevole” che limita ogni punto a considerare solo i suoi vicini lungo un breve tratto della linea di fuoco, il che aiuta a mantenere le aree operative continue nello spazio. Secondo, attribuisce un peso numerico maggiore alle caratteristiche che segnalano oggetti chiave e il tipo di parte del fuoco, aumentando la distanza effettiva tra, per esempio, una testa di fuoco e una coda anche se per il resto sono simili. Questo rende più facile separare segmenti critici che dovrebbero ricevere tattiche diverse.

Testare le prestazioni e regolare i parametri
Gli autori hanno esaminato come diverse impostazioni influenzano il comportamento del loro algoritmo. Aumentando i pesi su oggetti chiave e tipi di parte del fuoco, hanno constatato che il metodo migliorava molto nell’identificare correttamente teste, code, fianchi e zone protette, sebbene ciò producesse anche leggermente più punti isolati trattati come outlier. Regolare la lunghezza della finestra scorrevole ha mostrato un compromesso: troppo corta e molti punti diventavano isolati; troppo lunga e i cluster perdevano continuità lungo la linea di fuoco. Hanno inoltre variato il raggio di vicinato e il numero minimo di vicini necessari per formare un nucleo, ognuno dei quali ha influenzato quanto finemente la linea di fuoco veniva suddivisa e quanti punti venivano scartati come rumore. Le impostazioni ottimali hanno bilanciato riconoscibilità, continuità e un basso tasso di outlier.
Come il nuovo metodo si confronta con gli altri
Per valutare se SW‑DBSCAN sia davvero utile nella pratica, i ricercatori lo hanno confrontato con altri tre metodi di clustering spaziale: il DBSCAN standard, OPTICS e HDBSCAN. Hanno misurato quanto fosse continua ogni cluster lungo la linea di fuoco, quanto accuratamente fossero identificate le zone chiave, quanti punti rimanessero outlier, quanto fossero compatti e ben separati i cluster e quanto tempo impiegassero gli algoritmi a eseguire. SW‑DBSCAN ha prodotto cluster molto più continui rispetto agli altri metodi, pur identificando correttamente quasi tutti gli oggetti chiave e le parti di fuoco. È risultato più veloce delle alternative e ha mostrato comportamento stabile su dieci diverse linee di fuoco. Sebbene il suo tasso di outlier fosse leggermente superiore a quello del DBSCAN standard, è rimasto sotto circa il dieci percento, valore che gli autori considerano accettabile per questa applicazione.
Che cosa significa per le persone in prima linea
In termini semplici, questo lavoro offre un modo più intelligente di tracciare linee su una mappa dell’incendio. Invece di affidarsi agli ingegneri che suddividono manualmente il bordo del fuoco in zone basandosi su esperienza e giudizio approssimativo, il metodo SW‑DBSCAN può suggerire automaticamente aree operative continue e chiaramente distinguibili che evidenziano fronti in rapido movimento e posizioni sensibili. Ciò può a sua volta supportare un dispiegamento più preciso di squadre, velivoli e mezzi, riducendo potenzialmente i danni e salvando vite. Gli autori osservano che saranno necessari più dati reali, più regioni e futuri miglioramenti — come il riconoscimento di diversi tipi di oggetti protetti e la gestione di linee di fuoco che cambiano nel tempo — prima che il sistema possa essere pienamente operativo. Nonostante ciò, rappresenta un passo importante verso tattiche antincendio basate sui dati che tengono sotto controllo la complessità pericolosa.
Citazione: Huang, Q., Huang, Y. A forest firefighting task area division method based on the SW-DBSCAN algorithm. Sci Rep 16, 14089 (2026). https://doi.org/10.1038/s41598-026-42407-0
Parole chiave: gestione incendi boschivi, pianificazione operazioni antincendio, algoritmo di clustering, DBSCAN, risposta alle emergenze