Clear Sky Science · en
A forest firefighting task area division method based on the SW-DBSCAN algorithm
Why smarter fire lines matter
When a major forest fire breaks out, firefighters race not just against the flames but against confusion. A single ring of fire can stretch for many kilometers, with some sections racing forward, others dying down, and some threatening homes or power lines. Deciding where each crew should go is a life‑or‑death puzzle. This study presents a new way to automatically carve that long, shifting fire edge into practical work zones, so that people, helicopters, and drones can be sent to the right place at the right time.
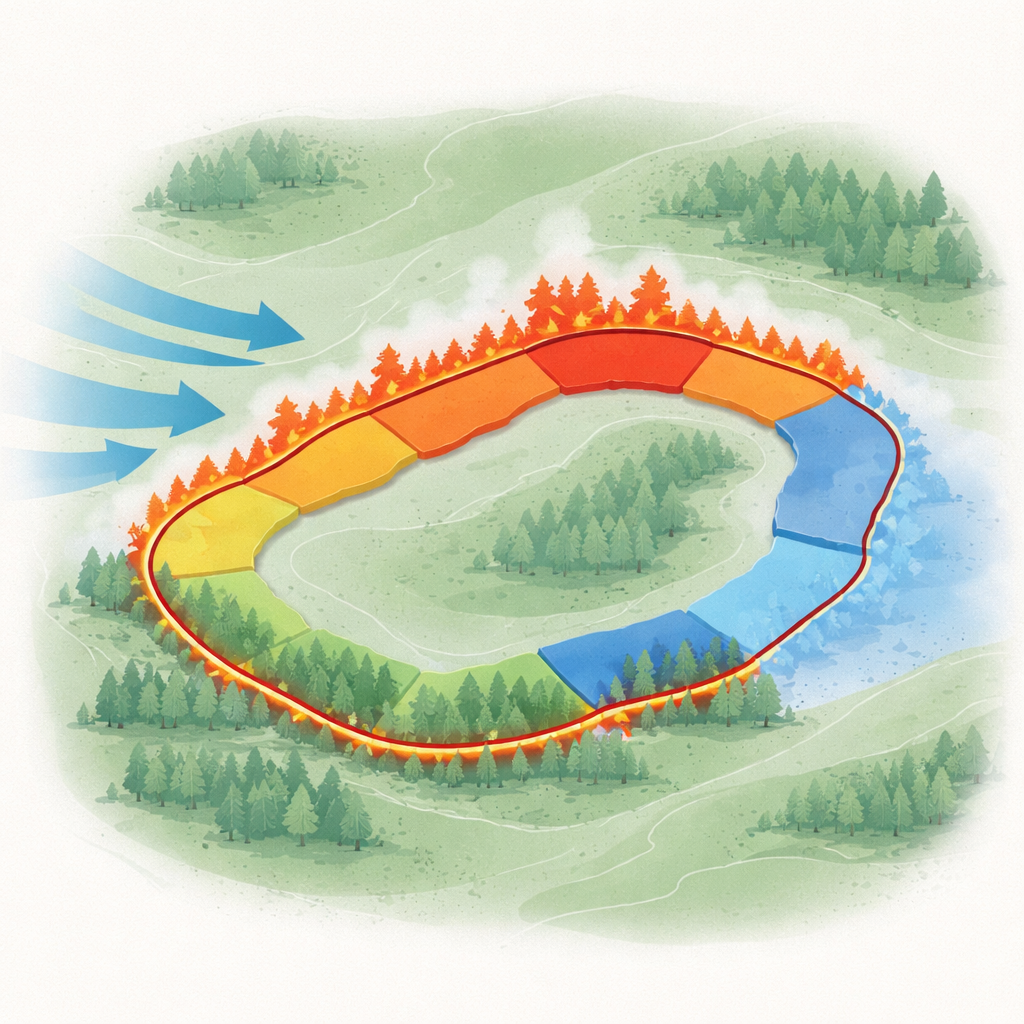
Turning a moving fire into manageable pieces
The authors focus on a key step in wildfire response: dividing the fire edge into a set of continuous task areas, each with similar conditions. Along any fire line, some parts are more dangerous than others. The fire head charges fastest with intense flames, the tail creeps along more slowly, and the flanks lie in between. In addition, there may be houses, cultural sites, or valuable forest stands that must be protected first. The goal is to group neighboring points on the fire line that share similar behavior, terrain, weather, and protection needs, so that each group becomes one coherent assignment for a firefighting team.
From raw simulator data to a smart map
To test their method, the researchers used a detailed fire simulation for the Oak Knoll region of Napa County, California. They extracted ten separate fire lines, together covering about 282 kilometers, from the FlamMap fire simulator. For every point along these lines, they assembled a ten‑part description that included wind direction and speed, fire intensity, slope direction and steepness, forest canopy density, fuel type, whether the fire was moving uphill, whether that point was head, tail, or flank, and whether a key protection target was present. All these values were scaled into a common range so that no single factor dominated just because it used larger numbers.
A tailored clustering tool for the fire front
The core of the work is an improved clustering technique called SW‑DBSCAN. Standard DBSCAN is a popular method for finding dense groups of data points while ignoring scattered noise, but it has two drawbacks in this setting: it can join distant parts of the fire line that happen to share similar numbers, and it does not treat key locations—such as a fire head or a protected building—as especially important. The new version adds two changes. First, it uses a “sliding window” that restricts each point to consider only its neighbors along a short stretch of the fire line, which helps keep resulting task areas continuous in space. Second, it gives extra numerical weight to the features that mark key objects and fire part type, increasing the effective distance between, say, a head fire and a tail fire even if they are otherwise similar. This makes it easier to separate critical segments that should receive different tactics.

Testing performance and tuning the knobs
The authors examined how several settings shape the behavior of their algorithm. By increasing the weights on key objects and fire part types, they found that the method became much better at correctly flagging fire heads, tails, flanks, and protected zones, though this also produced slightly more isolated points that were treated as outliers. Adjusting the length of the sliding window showed a trade‑off: too short, and many points became isolated; too long, and clusters lost their continuity along the fire line. They also varied the neighborhood radius and the minimum number of neighbors needed to form a core group, each of which affected how finely the fire line was split and how many points were discarded as noise. The best settings balanced recognizability, continuity, and a low outlier rate.
How the new method stacks up against others
To judge whether SW‑DBSCAN truly helps in practice, the researchers compared it with three other spatial clustering methods: standard DBSCAN, OPTICS, and HDBSCAN. They measured how continuous each cluster was along the fire line, how accurately key zones were identified, how many points were left as outliers, how compact and well‑separated the clusters were, and how long the algorithms took to run. SW‑DBSCAN produced clusters that were far more continuous than the other methods, while still identifying almost all key objects and fire parts correctly. It ran faster than the alternatives and showed stable behavior across ten different fire lines. Although its outlier rate was a bit higher than that of standard DBSCAN, it stayed below about ten percent, which the authors consider acceptable for this application.
What this means for people on the fire line
In simple terms, this work offers a smarter way to draw lines on a fire map. Instead of engineers manually carving the fire edge into zones based on experience and rough judgment, the SW‑DBSCAN method can automatically suggest continuous, clearly distinguishable task areas that highlight fast‑moving fronts and sensitive locations. That, in turn, can support more precise deployment of crews, aircraft, and equipment, potentially reducing damage and saving lives. The authors note that more real‑world data, more regions, and future improvements—such as recognizing different types of protected objects and handling changing fire lines over time—will be needed before the system can be fully operational. Nonetheless, it marks an important step toward data‑driven wildfire tactics that keep dangerous complexity manageable.
Citation: Huang, Q., Huang, Y. A forest firefighting task area division method based on the SW-DBSCAN algorithm. Sci Rep 16, 14089 (2026). https://doi.org/10.1038/s41598-026-42407-0
Keywords: forest fire management, wildfire task planning, clustering algorithm, DBSCAN, emergency response