Clear Sky Science · it
Apprendimento federato con aggiornamento continuo per la predizione di eventi clinici preservando la privacy attraverso ospedali distribuiti usando MCN-GNN
Perché questo è importante per la tua salute
Gli ospedali moderni raccolgono enormi quantità di cartelle cliniche digitali, ma regole stringenti sulla privacy e questioni di fiducia rendono difficile mettere insieme i dati e apprendere da essi in modo collettivo. Questo articolo presenta un metodo che permette a molti ospedali di addestrare congiuntamente strumenti di predizione potenti per condizioni come insufficienza cardiaca, ictus, malattia epatica, malattia renale e diabete—senza mai condividere i dati grezzi dei pazienti. Affronta anche un problema nascosto in molti sistemi di intelligenza artificiale: la tendenza a “dimenticare” conoscenze pregresse quando arrivano nuove informazioni.
Molti ospedali, un cervello condiviso
Gli autori si basano su un’idea chiamata apprendimento federato: invece di inviare le cartelle dei pazienti a un server centrale, ogni ospedale addestra il proprio modello locale e invia solo gli aggiornamenti appresi a un modello globale condiviso. In questo lavoro, dozzine di ospedali possono concentrarsi su problemi diversi—per esempio, uno predice l’insufficienza cardiaca, un altro l’ictus, un altro la cirrosi—ma tutti contribuiscono a un modello comune più forte. Questa impostazione mantiene i dati all’interno delle strutture ospedaliere pur permettendo a tutti di beneficiare dell’esperienza combinata di migliaia di pazienti.
Trasformare le storie cliniche in reti
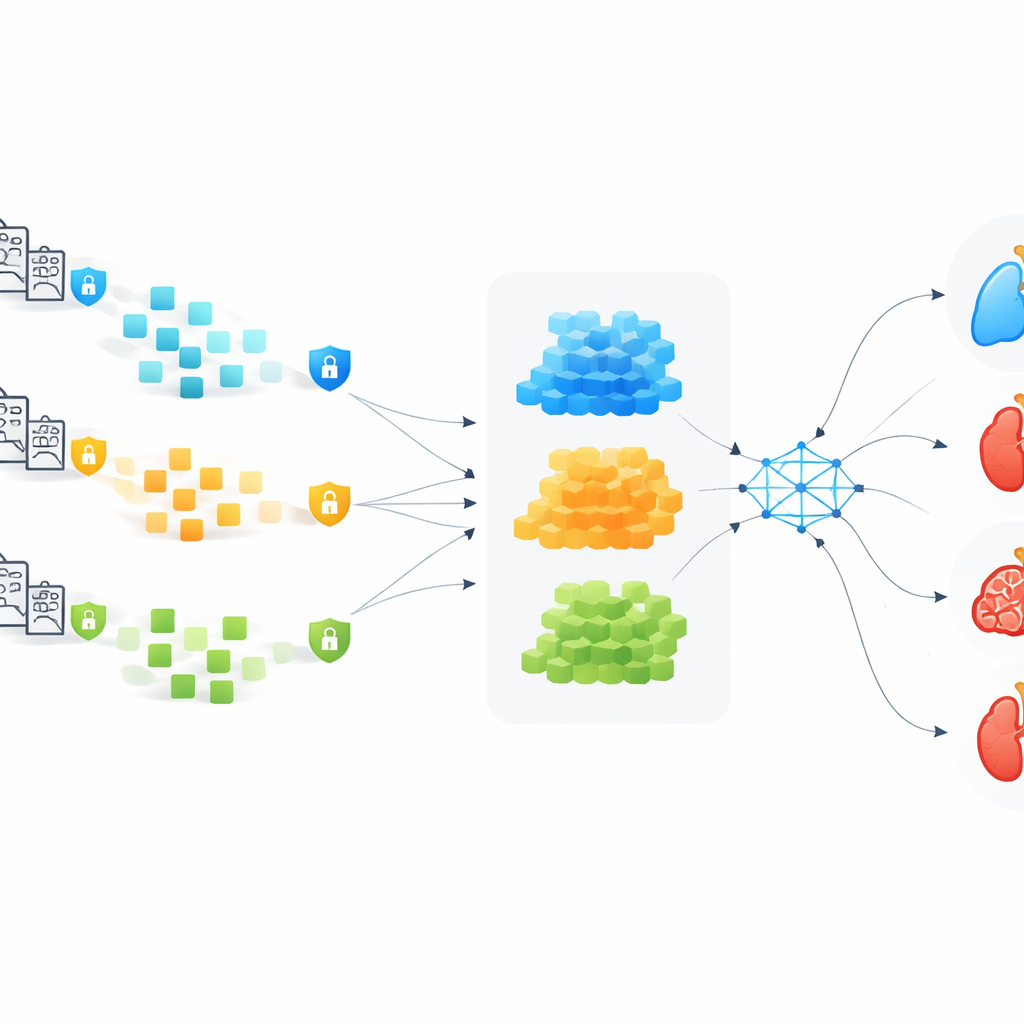
Per sfruttare al massimo le cartelle cliniche elettroniche, il team converte le informazioni di ciascun paziente in una rete di eventi nel tempo. In questa rete, le caratteristiche mediche—come età, pressione sanguigna, risultati di laboratorio e sintomi—sono trattate come nodi, e i collegamenti tra di esse catturano come eventi precedenti influenzino quelli successivi. Questa struttura, chiamata grafo temporale‑causale, è pensata per mettere in luce schemi di causa‑effetto piuttosto che semplici correlazioni. Un modello specializzato basato sui grafi apprende da queste reti utilizzando un passaggio di “mean‑centering” per evitare che le diverse caratteristiche si mescolino eccessivamente, una debolezza comune di molti metodi su grafi.
Mantenere i segreti mentre i modelli viaggiano
Anche se gli ospedali inviano solo aggiornamenti dei modelli, questi aggiornamenti possono comunque rivelare informazioni private se un attaccante li analizza con astuzia. Per prevenire ciò, gli autori cifrano le modifiche apportate dai singoli ospedali usando uno schema che permette al server centrale di eseguire calcoli direttamente su numeri oscurati senza mai vedere i valori sottostanti. Una tecnica di scalatura speciale mantiene sotto controllo il “rumore” matematico aggiunto, in modo che l’addestramento cifrato rimanga accurato. Prima che gli aggiornamenti di un ospedale vengano accettati, una firma digitale rinforzata verifica che il mittente sia genuino e che gli aggiornamenti non siano stati manomessi. Tutti i passaggi principali—registrazione, addestramento, aggregazione e aggiornamenti—sono registrati su un registro in stile blockchain per fornire una traccia di verifica che nessuna singola parte possa riscrivere di nascosto.
Fare in modo che l’apprendimento non invecchi mai
Gli ospedali del mondo reale non stanno fermi: emergono nuove malattie, le linee guida cambiano e le popolazioni dei pazienti si evolvono. Una grande sfida per i sistemi di apprendimento è il “catastrophic forgetting”, cioè l’assorbimento di nuovi schemi che cancella ciò che era stato appreso prima. Gli autori propongono un metodo di aggiornamento continuo che miscela con cura le conoscenze più vecchie con le informazioni fresche ogni volta che il modello globale viene rimandato agli ospedali. Gli esempi più vecchi vengono riproposti con minore frequenza nel tempo, ma non scompaiono mai completamente, aiutando ogni ospedale a conservare ciò che ha già imparato pur adattandosi a nuove tendenze.
Quanto funziona in pratica?
Il framework è stato testato utilizzando cinque dataset pubblici che coprono insufficienza cardiaca, ictus, cirrosi, malattia renale cronica e diabete. In questi diversi compiti, il sistema ha raggiunto accuratezze di predizione attorno al 99%, superando nettamente una serie di modelli esistenti basati su deep learning e su grafi. Ha inoltre mostrato forte resistenza a vari attacchi informatici, ha mantenuto prestazioni equilibrate tra ospedali con tipi di dati molto diversi e si è scalato su molti round di addestramento senza costi di comunicazione o computazione insostenibili.
Cosa significa per pazienti e clinici
In termini semplici, questo lavoro dimostra che gli ospedali possono costruire congiuntamente strumenti di allerta precoce altamente accurati per eventi clinici gravi mantenendo le cartelle dei pazienti al sicuro dietro i propri firewall. Combinando addestramento che preserva la privacy, controlli di sicurezza robusti, apprendimento continuo e registrazione trasparente, il sistema proposto potrebbe supportare avvisi di rischio in tempo reale e piani di cura più personalizzati su reti ospedaliere estese—senza costringere a un compromesso tra intuizione medica e privacy dei dati.
Citazione: Jagdeesh, K., Kanimozhi, N., Sardar, T.H. et al. Federated learning with continual update for privacy-preserving clinical event prediction across distributed hospitals using MCN-GNN. Sci Rep 16, 12608 (2026). https://doi.org/10.1038/s41598-026-40964-y
Parole chiave: apprendimento federato, cartelle cliniche elettroniche, predizione di eventi clinici, IA che preserva la privacy, reti neurali su grafi