Clear Sky Science · it
Apprendimento automatico interpretabile per la produzione ottimizzata di etere dimetilico da bio-metanolo
Trasformare gli scarti vegetali in carburante pulito
Immaginate di convertire un alcol di origine vegetale in un combustibile a combustione pulita usando un reattore chimico che può «imparare» a funzionare meglio nel tempo. Questo articolo esplora come la combinazione dell'ingegneria chimica tradizionale con l'apprendimento automatico moderno possa rendere la produzione di etere dimetilico — un promettente carburante a basse emissioni di fuliggine ottenuto da bio-metanolo — più efficiente, più facile da controllare e più semplice da comprendere.
Perché questo carburante e questo reattore contano
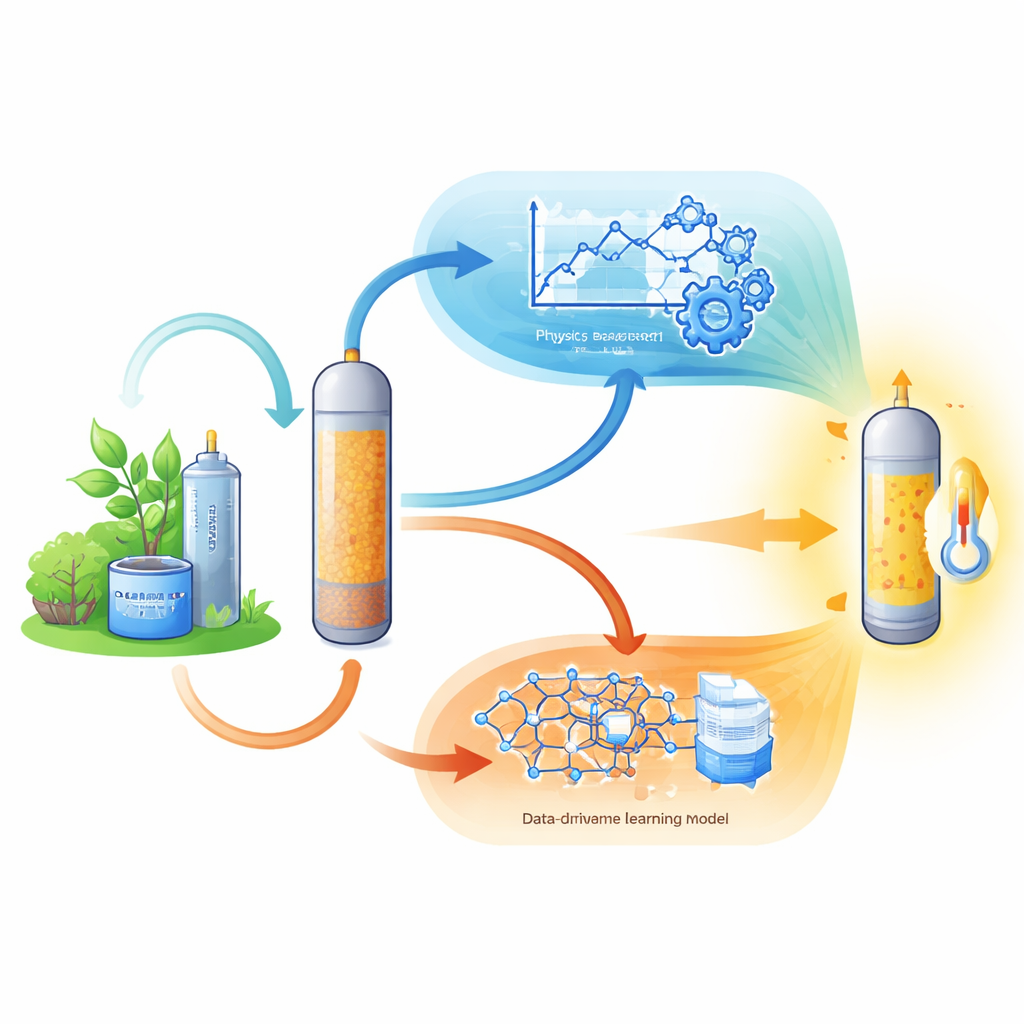
L'etere dimetilico (DME) sta attirando interesse come alternativa al gasolio perché brucia in modo pulito e può essere prodotto da fonti rinnovabili come il bio-metanolo. Al cuore di un impianto DME c'è un tubo riempito chiamato reattore a letto fisso, contenente un catalizzatore solido che favorisce l'unione delle molecole di metanolo con il rilascio di acqua e calore. Questa reazione è altamente esotermica, il che significa che la temperatura può salire rapidamente e incidere sia sulla sicurezza sia sulla qualità del carburante. La progettazione e la gestione di tali reattori si sono tradizionalmente basate su modelli «first-principles» complessi — sistemi di equazioni fondati su fisica e chimica — che sono accurati ma lenti e difficili da adattare quando il comportamento reale si discosta dalla teoria.
Fondere la fisica con i dati
Gli autori propongono un approccio ibrido che fonde modelli basati sulla fisica con metodi data-driven di apprendimento automatico. Prima costruiscono e convalidano rigorosamente un modello dettagliato del reattore che tiene traccia di come variano temperatura, pressione e le quantità di metanolo, DME e acqua lungo la lunghezza del reattore. Usando questo gemello digitale, generano 7.000 scenari operativi realistici, aggiungendo deliberatamente rumore per imitare l'incertezza sperimentale. Su questo set di dati sintetico ma coerente con la fisica, addestrano diversi metodi di machine learning — tra cui K-Nearest Neighbors e due popolari modelli ensemble basati su alberi — per prevedere il comportamento del reattore direttamente dalle condizioni operative come portata di alimentazione, temperatura di ingresso e pressione.
Insegnare al modello a correggere e spiegare se stesso
Piuttosto che sostituire completamente la fisica, lo studio utilizza l'apprendimento automatico in due ruoli ibridi complementari. In una modalità di «correzione», una rete neurale specializzata che gestisce sequenze impara a perfezionare le previsioni del modello di primo principio lungo la lunghezza del reattore, catturando tendenze sottili che le equazioni non colgono. In una modalità di «stima», il machine learning sostituisce leggi cinetiche difficili da misurare prevedendo la velocità di reazione locale a partire da variabili osservabili; la velocità viene poi reinserita nel modello fisico. In entrambi i casi, il nucleo del quadro fisico è preservato, così i risultati restano interpretabili in termini ingegneristici familiari — conversione, aumento di temperatura e caduta di pressione — mentre si ottengono miglioramenti di accuratezza dove le formule empiriche sono più deboli.

Trovare il punto operativo ottimale
Una volta disponibile un modello surrogato rapido e accurato, diventa praticabile cercare il modo migliore di gestire il reattore. Gli autori collegano il loro modello di machine learning più accurato a un algoritmo di ottimizzazione evolutiva progettato per esplorare automaticamente molte condizioni operative. Il loro obiettivo è massimizzare la quantità di metanolo convertita in DME mantenendo l'aumento di temperatura il più basso possibile per evitare punti caldi e stress sui materiali. Le condizioni ottimizzate identificate in questo modo raggiungono circa l'84% di conversione con un incremento di temperatura molto inferiore rispetto al caso di riferimento, e i modelli appresi possono valutare ciascuno scenario candidato circa venti volte più velocemente del simulatore completo basato sulla fisica.
Cosa significa per i processi puliti del futuro
Per un non specialista, il messaggio chiave è che non dobbiamo più scegliere tra un'intelligenza artificiale opaca e difficile da interpretare e modelli lenti e basati su equazioni. Combinandoli in modo ponderato, questo lavoro dimostra che un reattore chimico che produce un carburante pulito da un alcol rinnovabile può essere simulato, compreso e regolato più efficacemente. La spina dorsale basata sulla fisica mantiene il modello ancorato al comportamento reale, mentre l'apprendimento automatico colma le lacune e accelera i calcoli. Questa strategia ibrida offre una roadmap per progettare processi chimici più puliti, sicuri ed efficienti — non solo per il DME, ma in molte tecnologie necessarie per un futuro a basse emissioni di carbonio.
Citazione: Mokari, M., Rahmani, M. & Atashrouz, S. Interpretable machine learning for optimized dimethyl ether production from bio-methanol. Sci Rep 16, 9889 (2026). https://doi.org/10.1038/s41598-026-38090-w
Parole chiave: etere dimetilico, modellazione ibrida, apprendimento automatico, reattore a letto fisso, ottimizzazione di processo