Clear Sky Science · it
Dataset multimodale e iperspettrale per la segmentazione dei rifiuti ingombranti usando imaging VIS, IR, NIR e terahertz
Perché una selezione dei rifiuti più intelligente è importante
I rifiuti domestici ingombranti — dagli armadi rotti ai divani sprofondati — contengono spesso legno riutilizzabile. Tuttavia, gran parte finisce bruciata o in discarica perché le macchine fanno fatica a distinguere il legno da plastiche, metalli e imbottiture, soprattutto quando questi materiali sono sovrapposti o nascosti l’uno nell’altro. Questo articolo presenta WoodVIT, un dataset di immagini dettagliato pensato per aiutare l’intelligenza artificiale a “vedere” più a fondo in questi cumuli disordinati, così che i futuri sistemi di separazione possano riciclare più legno in modo sicuro ed efficiente.
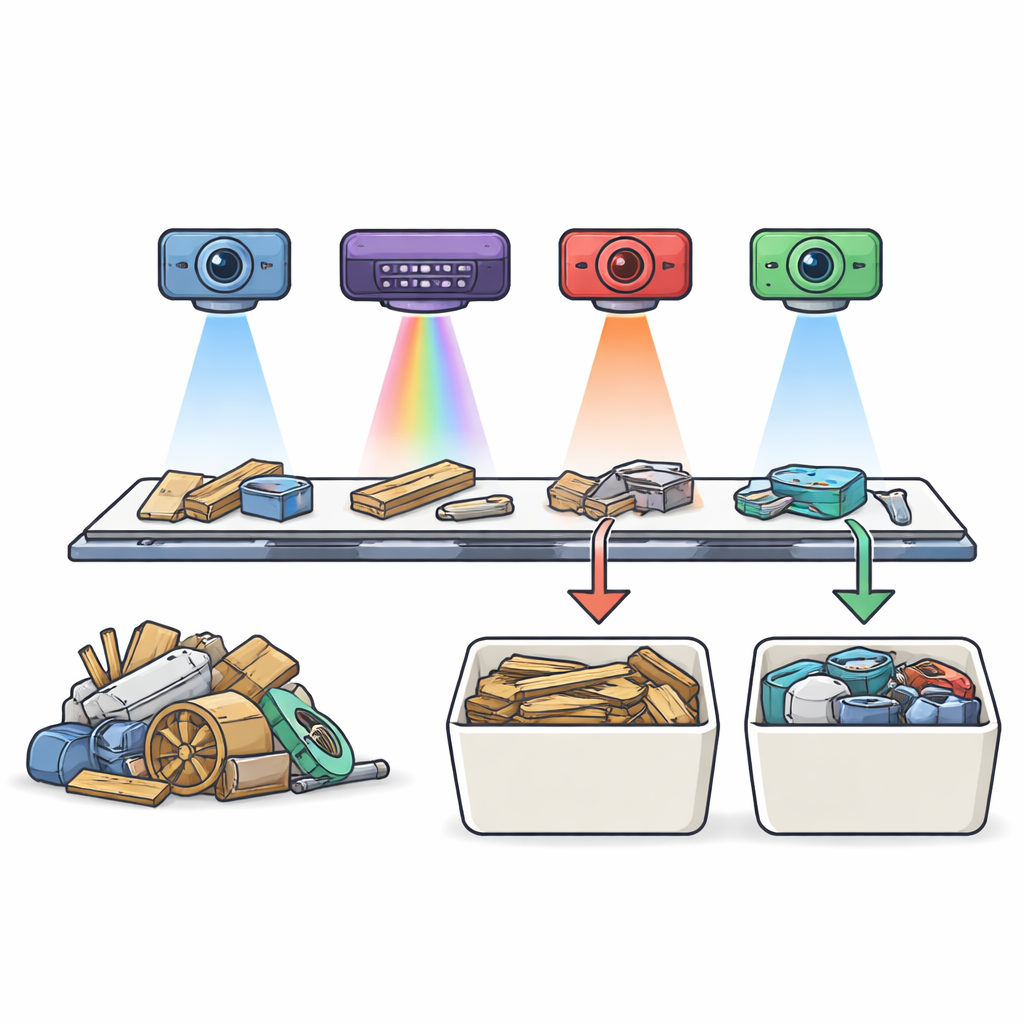
Osservare i rifiuti con nuovi tipi di occhi
Le macchine di riciclo convenzionali si affidano di solito a telecamere che vedono più o meno come il nostro occhio. Questo funziona bene per oggetti puliti e singoli, ma i rifiuti ingombranti sono disordinati: il legno può essere verniciato, coperto da tessuto, avvolto nella plastica o rinforzato con metallo. Gli autori affrontano il problema combinando quattro diverse “visioni” degli stessi oggetti. Utilizzano una camera a luce visibile (immagini a colori), una camera nel vicino infrarosso che cattura impronte spettrali specifiche dei materiali, una camera termica che osserva come gli oggetti si riscaldano e si raffreddano, e un sensore terahertz capace di rilevare strutture sepolte sotto la superficie. Ogni tecnologia cattura proprietà fisiche diverse e, insieme, offrono un quadro più completo di quello che potrebbe fornire un singolo sensore.
Dal mobilio rotto ai dati per le macchine
Per costruire il dataset, il team ha raccolto mobili schiacciati e altri scarti ingombranti da un impianto di smaltimento locale. Hanno posizionato questi pezzi misti su pannelli standardizzati che passavano sotto i quattro sensori su un nastro trasportatore, imitando una linea di selezione industriale. Ogni pannello è stato immaginato una volta da ciascun sensore, quindi tutte e quattro le immagini sono state accuratamente allineate in modo che ogni pixel in un’immagine corrispondesse allo stesso punto fisico nelle altre. Annotatori umani hanno tracciato contorni dettagliati sulle immagini a colori, segnando legno, metalli, plastiche, minerali, imbottiture e diverse situazioni “coperte” come metallo nascosto sotto il legno o legno nascosto sotto il tessuto. Queste etichette sono state trasferite alle altre viste dei sensori, producendo 56 scene completamente allineate e 22.659 piccole patch di immagine pronte per l’addestramento e il test dei modelli di machine learning.
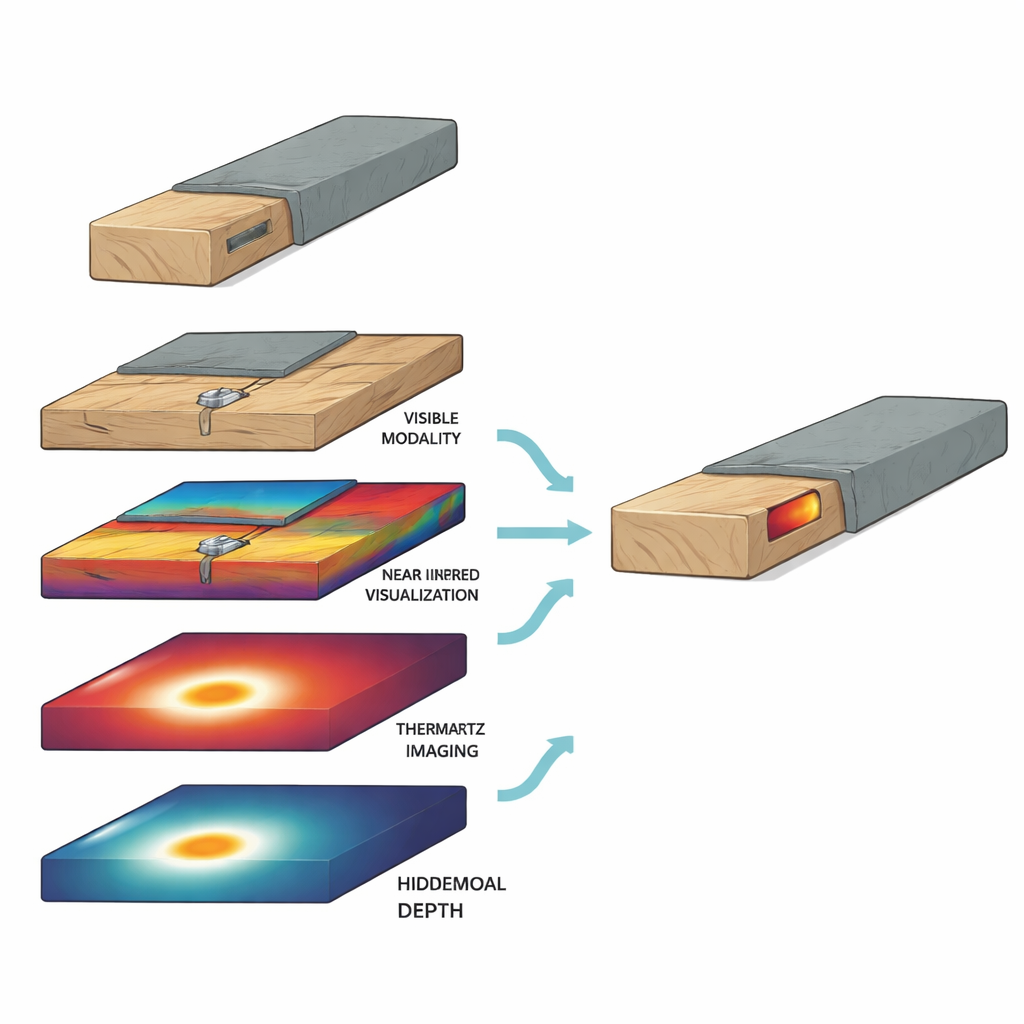
Insegnare ai computer a riconoscere il legno e i pericoli nascosti
Il compito centrale in WoodVIT è semplice da enunciare: decidere se ciascuna piccola patch di immagine è “legno” o “non‑legno”. Sotto la superficie, ciò comporta la gestione di 717 canali di informazione per patch attraverso i quattro sensori. Gli autori hanno testato diversi modelli di reti neurali su questo compito, addestrandoli su sensori singoli oppure su tutti i sensori combinati. I modelli che usavano solo immagini a colori hanno ottenuto risultati ragionevoli, ma quelli che fondevano le informazioni provenienti da tutti e quattro i sensori hanno performato meglio e in modo più consistente. Sebbene i dati termici e terahertz da soli fossero più difficili da apprendere, sono risultati preziosi quando combinati con le viste a colori e nel vicino infrarosso, soprattutto in scene complesse in cui il legno è verniciato, impilato o nasconde parti metalliche.
Dare senso all’occlusione e alle scene complesse
Una caratteristica distintiva di WoodVIT è l’attenzione a situazioni realistiche e “non ideali”. Il dataset include pannelli in cui viti metalliche sono incorporate nel legno, o dove telai in legno sono avvolti in schiuma o tessuto. Per questi casi coperti, i ricercatori hanno costruito il ground truth in due fasi: prima hanno immaginato e etichettato lo strato di base, poi hanno aggiunto la copertura, hanno ri‑immaginato e hanno fuso le etichette. Questa progettazione accurata rende possibile valutare quanto bene diverse combinazioni di sensori rivelino ciò che si trova sotto la superficie. Gli autori hanno inoltre esplorato la segmentazione a livello di pixel usando un’architettura di rete neurale popolare che delimita le regioni di legno all’interno di ogni patch. Sia gli input a colori sia quelli nel vicino infrarosso hanno prodotto contorni accurati, dimostrando che i dati supportano non solo decisioni sì/no, ma anche mappe dettagliate di dove si trova effettivamente il legno.
Cosa significa per il riciclo futuro
Per i non specialisti, il messaggio chiave è che un riciclo più intelligente non riguarda solo la costruzione di una fotocamera migliore — riguarda la combinazione di molte modalità di visione in una singola visione coerente. WoodVIT fornisce la materia prima per questo: una raccolta pubblica e accuratamente etichettata di immagini che cattura come i rifiuti ingombranti appaiono attraverso le bande visibili, infrarosse e terahertz. Consentendo ai ricercatori di addestrare e confrontare algoritmi avanzati sugli stessi dati multimodali e difficili, questo lavoro pone le basi per sistemi di selezione di nuova generazione in grado di recuperare più legno utilizzabile, individuare contaminanti metallici nascosti e, in ultima analisi, rendere il riciclo dei rifiuti ingombranti più pulito, sicuro ed efficiente.
Citazione: Bihler, M., Roming, L., Čibiraitė-Lukenskienė, D. et al. Multimodal and Hyperspectral Dataset for Segmentation of Bulky Waste using VIS, IR, NIR, and Terahertz Imaging. Sci Data 13, 498 (2026). https://doi.org/10.1038/s41597-026-07053-1
Parole chiave: riciclo rifiuti ingombranti, imaging multimodale, dati iperspettrali, selezione del legno, fusione di sensori