Clear Sky Science · it
La traduzione errata sopprime la trascrizione errata negli eucarioti
Quando le cellule interpretano male le proprie istruzioni
Ogni cellula dipende dalla lettura accurata delle proprie istruzioni genetiche, ma queste letture non sono perfette. Come refusi in un libro, piccoli errori possono insinuarsi quando il DNA viene copiato in RNA o quando l’RNA viene usato per costruire proteine. Questi errori sono stati a lungo studiati per lo più uno alla volta. Questo articolo rivela una svolta inattesa: due diversi tipi di errori, a lungo considerati problemi separati, in realtà interagiscono in modo che aiuti le cellule a mantenere almeno uno di essi sotto un controllo più rigoroso.
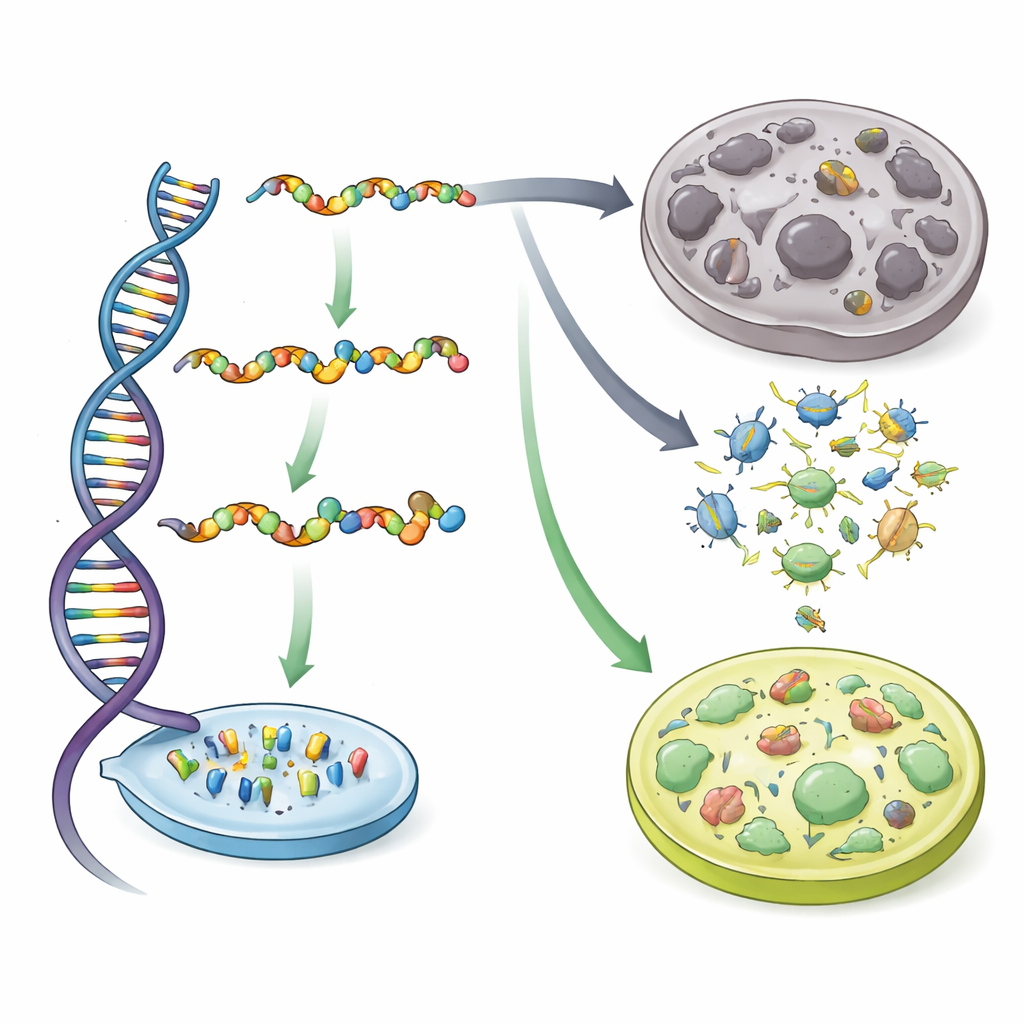
Due tipi di refusi biologici
Gli autori si concentrano su due fasi della “catena dell’informazione” genetica. Primo, durante la trascrizione, una cellula copia il DNA in RNA; a volte viene inserita la lettera RNA sbagliata, un errore chiamato mistranscrizione. Secondo, durante la traduzione, la macchina cellullare che produce proteine può inserire il blocco costitutivo sbagliato (un amminoacido) in una catena proteica in crescita, noto come mistraduzione. Entrambi gli errori generano proteine difettose, che possono ripiegarsi in modo errato, aggregarsi, mettere in stress la cellula e sono collegati a cancro, neurodegenerazione e invecchiamento. Su base per-lettera, la traduzione è molto più imprecisa della trascrizione. Tuttavia, quando gli autori convertono questi tassi di errore per-lettera nella probabilità che il prodotto di un intero gene contenga almeno un errore, il divario si riduce: la mistraduzione è solo circa tre volte più probabile della mistranscrizione per un gene tipico, sottolineando che entrambi i tipi di errore sono rilevanti.
Misurare gli errori attraverso l’albero della vita
Per vedere quanto spesso si verificano questi errori nelle cellule reali, il gruppo ha combinato due tecnologie potenti. Un metodo chiamato Circ-Seq consente di rilevare veri errori di trascrizione rileggendo ripetutamente la stessa molecola di RNA e separando le vere discrepanze dal rumore di sequenziamento. La spettrometria di massa, una tecnica che pesa frammenti peptidici, permette di individuare sottili spostamenti di massa che possono essere spiegati solo dall’inserimento dell’amminoacido sbagliato in una proteina. Applicando pipeline di analisi unificate a umani, topi, moscerini della frutta, vermi e lievito, hanno mappato dove e con quale frequenza si verificano mistranscrizione e mistraduzione in migliaia di geni. I modelli osservati corrispondevano a lavori precedenti, dando fiducia che stavano osservando segnali biologici reali piuttosto che artefatti tecnici.
Un sorprendente compromesso tra tipi di errore
Con queste mappe genomiche a disposizione, i ricercatori hanno chiesto come i due tipi di errore si relazionino per ciascun gene. Un’aspettativa semplice sarebbe che alcuni geni siano generalmente “imprecisi” e altri “precisi”, portando a una correlazione positiva tra mistranscrizione e mistraduzione. Invece, hanno trovato l’opposto: i geni che vengono spesso mistradotti tendono a essere trascritti più accuratamente. Questa relazione negativa è apparsa in modo consistente in tutte e cinque le specie e è rimasta anche dopo aver controllato per l’espressione genica e il rumore statistico. Il risultato suggerisce un compromesso: dove gli errori di traduzione sono comuni, l’evoluzione sembra aver spinto verso una riduzione degli errori di trascrizione.
Quando due errori sono peggio di uno
Per spiegare questo compromesso, gli autori hanno fatto riferimento all’idea di epistasi negativa, dove l’effetto combinato di due difetti è peggiore della somma dei singoli difetti. Usando grandi biblioteche di ceppi di lievito portatori di mutazioni singole e doppie in un gene reporter, hanno misurato direttamente come coppie di cambi puntiformi influenzano la crescita. In molte condizioni, i doppi mutanti tipicamente nuocciono alla fitness più di quanto ci si aspetterebbe sommando gli effetti dei due singoli mutanti, dimostrando un’epistasi negativa pervasiva a livello di sequenza proteica. Il gruppo ha poi utilizzato simulazioni al computer di popolazioni in evoluzione per chiedersi se questo tipo di interazione, ridimensionata agli eventi rari di errori di trascrizione e traduzione, potesse essere abbastanza forte da essere “nota” dalla selezione naturale. I modelli hanno mostrato che se le proteine contenenti entrambi i tipi di errore sono particolarmente dannose, l’evoluzione favorisce varianti geniche che riducono gli errori di trascrizione in quei geni già inclini alla mistraduzione, generando in modo naturale il compromesso osservato.
Segni nel mondo reale del controllo degli errori
Oltre alle simulazioni, gli autori hanno cercato impronte genomiche di questo meccanismo. Nei geni frequentemente mistradotti hanno trovato che gli errori di trascrizione dannosi—quelli che cambiano gli amminoacidi di una proteina—sono sottoposti a una pressione purificatrice più intensa rispetto ai geni con meno eventi di mistraduzione. Hanno inoltre osservato che i geni molto efficientemente tradotti, che producono molte copie proteiche da ogni RNA, tendono a mostrare meno errori di trascrizione. Questo ha senso intuitivo: un messaggio mistrascritto che viene molto tradotto produce molte proteine difettose, quindi anche rari scivoloni di trascrizione sono particolarmente dannosi. Nel complesso, queste linee di evidenza supportano l’idea che la mistraduzione, rendendo più tossici gli errori combinati, spinga indirettamente verso la riduzione dei tassi di mistranscrizione dove conta di più.
Perché questo conta per la salute e l’evoluzione
Svelando che gli errori di traduzione possono contribuire a sopprimere gli errori di trascrizione, questo studio mette in luce una coordinazione nascosta nel sistema di controllo degli errori della cellula. Piuttosto che minimizzare indipendentemente ogni tipo di errore, l’evoluzione sembra bilanciarli in modo che l’onere totale delle proteine difettose non sopraffaccia la cellula. Ciò ha implicazioni su come gli organismi invecchiano, su come emergono malattie come il cancro e l’Alzheimer e su come le cellule si adattano sotto stress. Suggerisce che livelli modesti di un tipo di errore possono essere tollerati—o persino mantenuti—perché aiutano a tenere sotto controllo altri errori più pericolosi.
Citazione: Zhang, X., Yu, G., Guo, Z. et al. Mistranslation suppresses mistranscription in eukaryotes. Nat Commun 17, 3181 (2026). https://doi.org/10.1038/s41467-026-69969-x
Parole chiave: errori di trascrizione, fedeltà della traduzione, controllo qualità delle proteine, evoluzione molecolare, stress cellulare