Clear Sky Science · en
Mistranslation suppresses mistranscription in eukaryotes
When Cells Misread Their Own Instructions
Every cell depends on reading its genetic instructions accurately, but those readings are not perfect. Like typos in a book, small errors can slip in when DNA is copied into RNA or when RNA is used to build proteins. These mistakes were long studied mostly one at a time. This paper reveals an unexpected twist: two different kinds of errors, long treated as separate problems, actually interact in a way that helps cells keep at least one of them under tighter control.
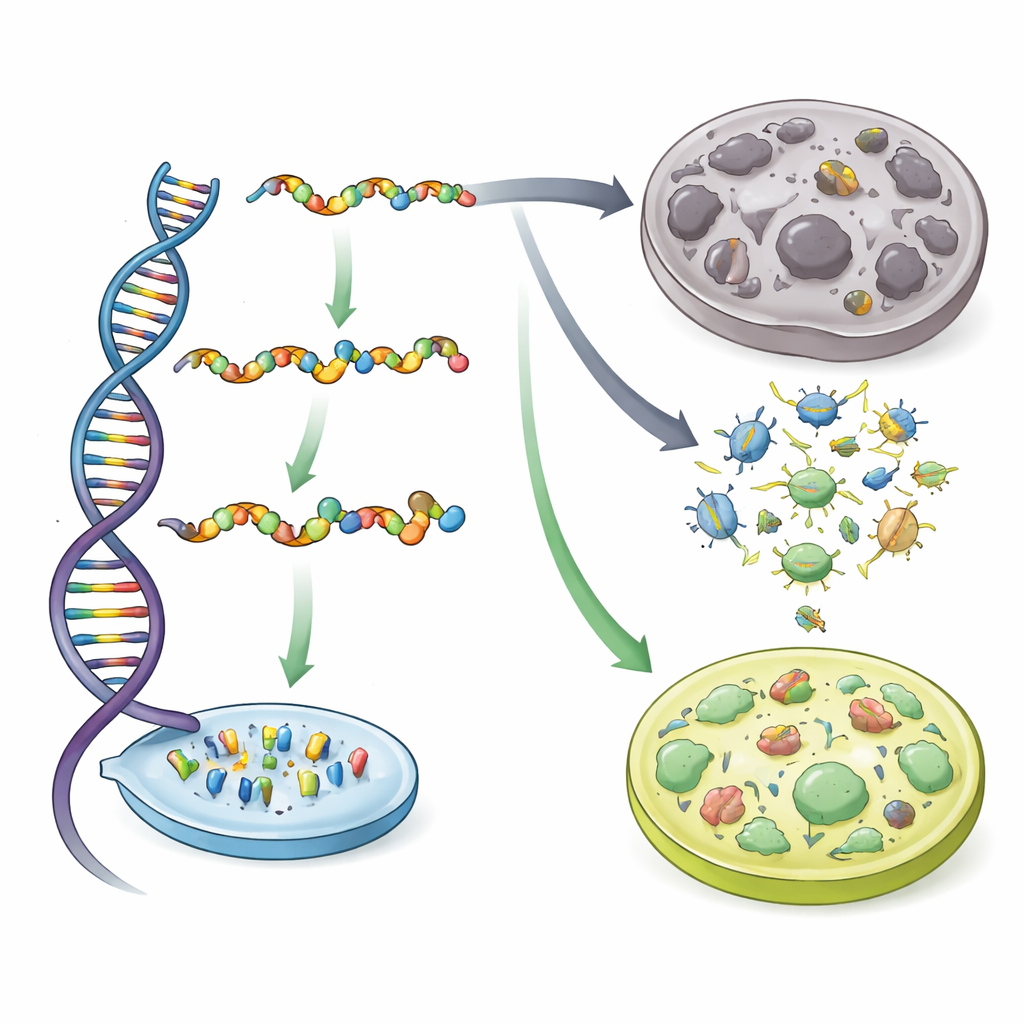
Two Kinds of Biological Typos
The authors focus on two stages of the genetic “information pipeline.” First, during transcription, a cell copies DNA into RNA; sometimes the wrong RNA letter is inserted, a mishap called mistranscription. Second, during translation, the cell’s protein-making machinery may plug the wrong building block (an amino acid) into a growing protein chain, known as mistranslation. Both errors create faulty proteins, which can misfold, clump together, stress the cell, and are linked to cancer, neurodegeneration, and aging. On a per-letter basis, translation is much sloppier than transcription. Yet when the authors convert these per-letter error rates into the chance that an entire gene’s product contains at least one mistake, the gap narrows: mistranslation is only about three times more likely than mistranscription for a typical gene, underscoring that both error types matter.
Measuring Errors Across the Tree of Life
To see how often these errors happen in real cells, the team combined two powerful technologies. A method called Circ-Seq lets them detect genuine transcription errors by repeatedly re-reading the same RNA molecule and separating true mismatches from sequencing noise. Mass spectrometry, a technique that weighs peptide fragments, lets them pick out subtle mass shifts that can only be explained by the wrong amino acid being built into a protein. Applying unified analysis pipelines to humans, mice, fruit flies, worms, and yeast, they mapped where and how frequently mistranscription and mistranslation occur in thousands of genes. The patterns they saw matched earlier work, giving confidence that they were looking at real biological signals rather than technical artifacts.
A Surprising Trade-Off Between Error Types
With these genome-wide maps in hand, the researchers asked how the two error types relate for each gene. A simple expectation would be that some genes are generally “sloppy” and others “precise,” leading to a positive correlation between mistranscription and mistranslation. Instead, they found the opposite: genes that are often mistranslated tend to be transcribed more accurately. This negative relationship appeared consistently in all five species and remained when they controlled for gene expression and statistical noise. The result hints at a trade-off: where translation errors are common, evolution seems to have pushed transcription errors down.
When Two Mistakes Are Worse Than One
To explain this trade-off, the authors turned to the idea of negative epistasis, where the combined effect of two defects is worse than the sum of each defect alone. Using large libraries of yeast strains carrying single and double mutations in a reporter gene, they directly measured how pairs of point changes affect growth. Across many conditions, double mutants typically hurt fitness more than expected from adding up the effects of the two single mutants, demonstrating pervasive negative epistasis at the level of protein sequence. The team then used computer simulations of evolving populations to ask whether this kind of interaction, scaled down to the rare events of transcription and translation errors, could be strong enough for natural selection to “notice.” The models showed that if proteins containing both kinds of errors are especially harmful, evolution favors gene variants that reduce transcription errors in those genes already prone to mistranslation, naturally generating the observed trade-off.
Real-World Signs of Error Control
Beyond simulations, the authors looked for genomic fingerprints of this mechanism. In genes that are frequently mistranslated, they found that harmful transcription errors—those that change a protein’s amino acids—are under stronger purifying pressure than in genes with fewer mistranslation events. They also observed that genes translated very efficiently, producing many protein copies from each RNA, tend to show fewer transcription errors. This makes intuitive sense: a mistranscribed message that is heavily translated spews out many bad proteins, so even rare transcription slips are especially damaging. Together, these lines of evidence support the view that mistranslation, by making combined errors more toxic, indirectly forces down mistranscription rates where it matters most.
Why This Matters for Health and Evolution
By revealing that translation mistakes can help suppress transcription mistakes, this study uncovers a hidden coordination in the cell’s error-control system. Rather than independently minimizing each type of error, evolution appears to balance them so that the total burden of faulty proteins does not overwhelm the cell. This has implications for how organisms age, how diseases like cancer and Alzheimer’s emerge, and how cells adapt under stress. It suggests that modest levels of one kind of error may be tolerated—or even maintained—because they help keep other, more dangerous mistakes in check.
Citation: Zhang, X., Yu, G., Guo, Z. et al. Mistranslation suppresses mistranscription in eukaryotes. Nat Commun 17, 3181 (2026). https://doi.org/10.1038/s41467-026-69969-x
Keywords: transcription errors, translation fidelity, protein quality control, molecular evolution, cellular stress