Clear Sky Science · he
מיצוי הביצועים בסיווג קרצינומה של הלבלב באמצעות Vision Transformer מותאם על ידי תוכנית 'תוכי'
מדוע זה חשוב למטופלים ולרופאים
סרטן הלבלב הוא אחד מסוגי הסרטן הקטלניים ביותר משום שלרוב מאבחנים אותו רק לאחר שגדל בשקט לאורך זמן רב. המחקר הזה בוחן כיצד מערכת בינה מלאכותית מתוכננת בקפידה יכולה לקרוא סריקות CT של הבטן ולעזור לרופאים לזהות גידולי לבלב באמינות ובעקיבות רבה יותר. על ידי שילוב כמה כלים מודרניים לעיבוד תמונה בצנרת אחת, החוקרים מראים שמחשבים יכולים לתמוך באבחון מוקדם ומדויק יותר, דבר שקריטי לשיפור הסיכויים לטיפול מוצלח.
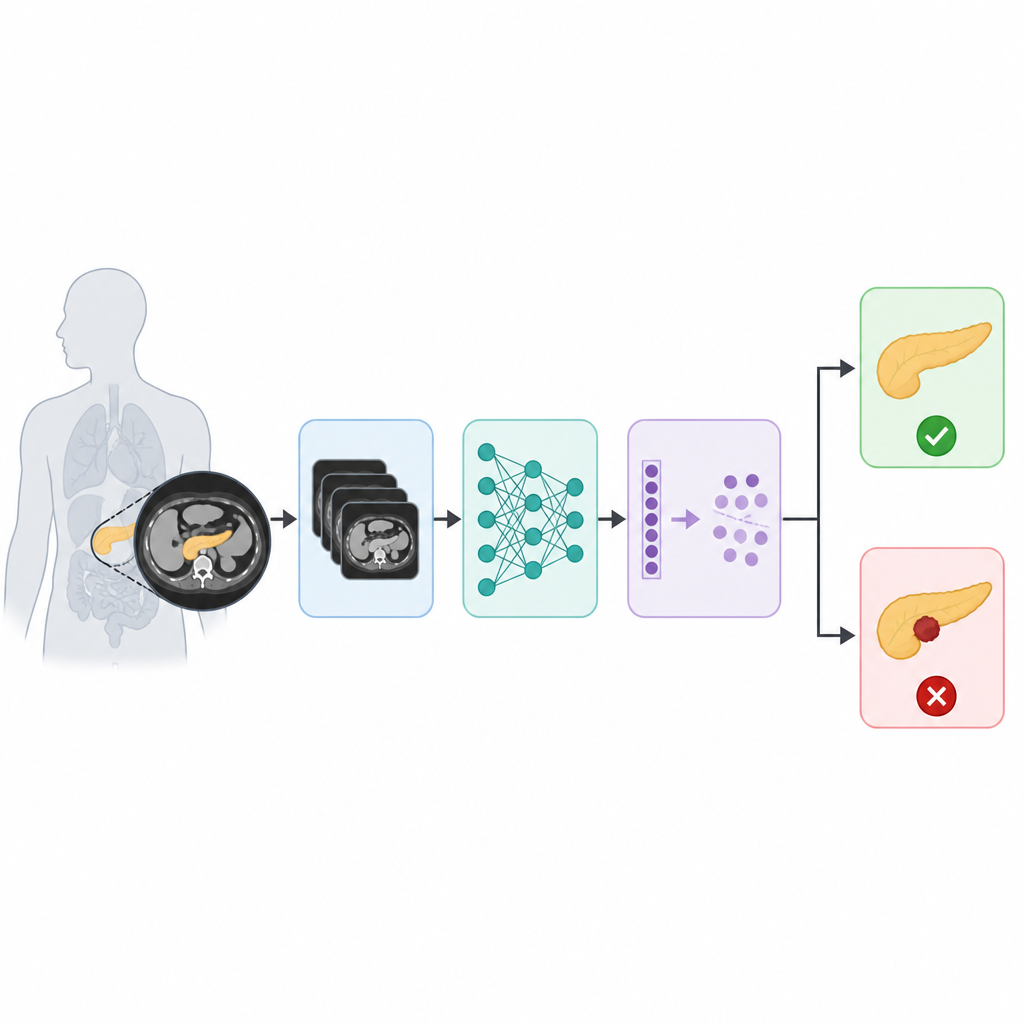
הפיכת סריקות גולמיות לתמונות ברורות יותר
המסע מתחיל באוסף של 1,811 תמונות CT של הלבלב, שנלקחו ממאגר מקוון פתוח וסווגו כתקין או כגידול. מאחר שתרשימי רפואיים עלולים להיות רעשיים ומעט שונים מסריקה לסריקה, הצוות הגדיל וניקּה תחילה את הנתונים. הם יצרו דוגמאות אימון נוספות על ידי סיבוב, השתקה וקנה מידה של התמונות המקוריות, מה שעוזר למערכת ללמוד להתמודד עם שונות טבעית בין מטופלים ומכשירים. לאחר מכן הוחל סוג מיוחד של מסנן הרגיש לקצוות ומרקמים כדי לחדד פרטים חשובים בלבלב ולהפחית רעשי רקע מטיעים. ההכנה הקפדנית הזו מקלה על השלבים הבאים להתמקד בשינויים עדינים שעלולים להעיד על גידול.
לאתר את האיבר לפני לשפוט את מצבו
במקום לבקש מהמחשב להבין את כל פרוסת ה-CT בבת אחת, החוקרים מלמדים אותו תחילה לאתר ולשרטט את הלבלב עצמו. הם משתמשים ברשת סגמנטציה מבוססת ארכיטקטורת U, מוכחת ומנוסה, שלומדת להפריד את האיבר מהרקמות והאיברים הסובבים בבטן. לאחר שאזור הלבלב מבודד, החיתוך הממוקד הזה מוזן למאתר חזק המיומן בזיהוי עצמים בגדלים שונים. המאתר מתרגם את הלבלב לתכונות מספריות עשירות שמתארות את צורתו, מרקמו והדפוסים הפנימיים בסולמות שונים, תוך התעלמות מרוב הרקע. על ידי צמצום תשומת הלב באופן זה, המערכת מפחיתה בלבול שנגרם ממבנים אחרים בחזות התמונה.
לאפשר למודל מבוסס תשומת-לב לקבל את ההחלטה
התכונות המופקדות עוברות אז ל-Vision Transformer, סוג חדש של מודל תמונה שמקורו במחקר תרגום שפה. במקום לסרוק את התמונה חתיכה אחר חתיכה באמצעות מסננים נגללים, המודל הזה מסתכל על הלבלב בחתיכות קטנות ולומד כיצד כל חתיכה קשורה לכל שאר החתיכות. במילים פשוטות, הוא מקדיש תשומת לב לאופן שבו דפוסים בחלק אחד של האיבר מתקשרים לדפוסים בחלקים אחרים, מה שעוזר לו לקלוט גם פרטים מקומיים וגם הקשר כוללני. הטרנספורמר מייצר החלטה ראשונית האם הלבלב נראה תקין או סרטני. כדי לדחוף את הביצועים עוד יותר, המחברים מוסיפים שלב שיפור סופי בהשראת התנהגות קבוצתית של תוכים המחפשים מזון, שבו בוחנים ומחדדים בהדרגה מספר מועמדויות כדי להפחית טעויות.

העמדת הצנרת למבחן
המערכת המלאה, שלפי המחברים נקראת ViT-PO, הוערכה בעזרת מדדים סטנדרטיים החשובים ברפואה: עד כמה היא צודקת בסך הכל, עד כמה היא מצליחה לזהות גידולים, ועד כמה היא נמנעת מהפעלת תראות שווא. על תמונות המבחן, המודל מגיע לכ-99 אחוז דיוק כולל ומראה איזון חזק בין איתור מקרים סרטניים אמיתיים לבין אי־תיוג שגוי של סריקות בריאות. הוא גם מציג ביצועים טובים יותר ממספר חלופות ידועות, כולל שיטות קלאסיות של למידת מכונה, רשתות עצביות עמוקות סטנדרטיות ועיצובי טרנספורמר אחרים שאינם עושים שימוש באותה צנרת משולבת. בדיקות רוחב עם חלוקי נתונים שונים והרצות חוזרות מרמזות שהתנהגות המערכת יציבה ולא רק תוצאה של מזל במדגם מסוים.
מה משמעות הדבר לטיפול עתידי
לקורא שאינו מקצועי, המסקנה המרכזית היא ששילוב כמה שלבים חכמים—ניקוי התמונה, בידוד האיבר, תיאורו בפרטי פרטים, שיפוט בעזרת מודל מבוסס תשומת-לב ולאחר מכן כיוונון סופי של ההחלטה—יכול להפוך את התמיכה הממוחשבת באבחון סרטן הלבלב ליותר מדויקת ואמינה. למרות שעבודה זו עדיין משתמשת במאגר יחיד ומתמקדת בבחירה פשוטה בין תקין לגידול, היא מצביעה על כלים שעשויים יום אחד לסייע לרדיולוגים לזהות סרטן לבלב מוקדם יותר ובביטחון גדול יותר, בתנאי שיוודאו אותם בקפידה על אוכלוסיות מטופלים רחבות ומגוונות יותר.
ציטוט: Mallika, C., Dinesh, E., Alsolai, H. et al. Maximizing pancreatic carcinoma classification performance using parrot optimized vision transformer. Sci Rep 16, 16277 (2026). https://doi.org/10.1038/s41598-026-53240-w
מילות מפתח: סרטן הלבלב, הדמיית CT, למידה עמוקה, Vision Transformer, אבחון רפואי