Clear Sky Science · fr
Modèles de langage multimodaux, images Street View et intelligence pour les politiques urbaines : reconstituer les effets durables du redlining
Pourquoi les rues de la ville et les vieilles cartes comptent encore aujourd’hui
De nombreuses villes tentent de réduire la pauvreté et de protéger les habitants contre la chaleur, mais elles manquent souvent d’informations actualisées, quartier par quartier, pour savoir où l’aide est la plus nécessaire. Cette étude montre comment l’intelligence artificielle moderne peut lire des photos de rue ordinaires pour révéler où faibles revenus et faible couverture arborée se concentrent encore, en particulier dans des quartiers de Phoenix, en Arizona, façonnés par la pratique historique du redlining.
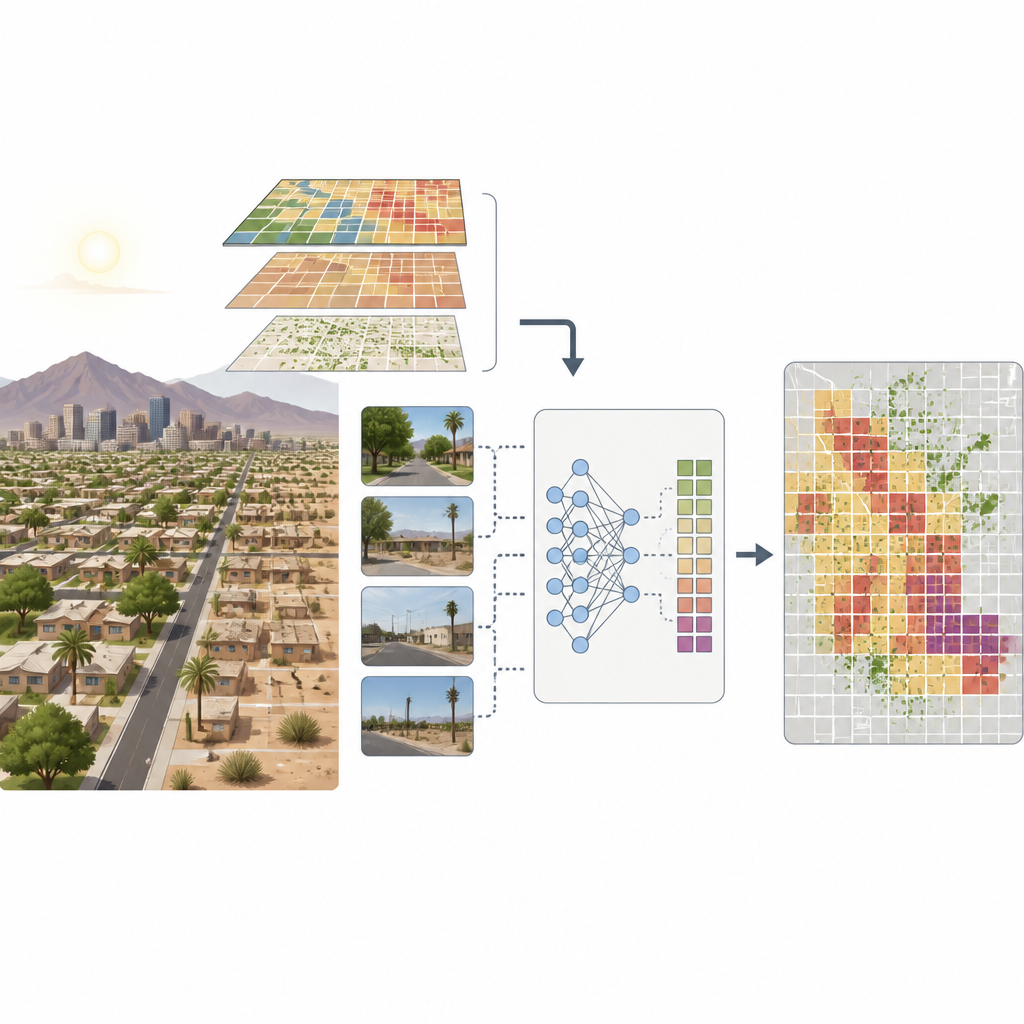
Anciennes classifications de logements et rues inégales aujourd’hui
Dans les années 1930, des cartes fédérales du logement ont étiqueté certains quartiers comme « dangereux » pour l’octroi de prêts hypothécaires, un processus connu sous le nom de redlining. Ces endroits, souvent peuplés davantage de personnes de couleur et de logements plus anciens, ont reçu moins d’investissements publics et privés pendant des décennies. À Phoenix, la grande ville la plus chaude des États-Unis, cette histoire compte encore parce que les zones les moins bien dotées en ressources et en arbres subissent une chaleur plus dangereuse et des conditions de vie plus difficiles. Les auteurs se concentrent sur deux piliers simples de la santé des quartiers : la part de résidents vivant sous le seuil de pauvreté et l’étendue de la canopée arborée fournissant de l’ombre.
Transformer des photos de rue en bulletins de quartier
Les chercheurs ont collecté près de vingt mille images Google Street View à travers plus d’un millier de petits quartiers. Ils ont ensuite construit deux types d’outils pour « lire » ces images. Un outil utilise un grand modèle de langage multimodal, GPT-4o, qui observe une scène entière et raisonne en langage clair sur des indices tels que la qualité du logement, l’entretien visible et la végétation avant de convertir ce raisonnement en scores numériques de pauvreté et de couverture arborée. L’autre outil est un modèle de vision par ordinateur standard qui classe les pixels individuels en catégories comme route, bâtiment ou arbre, puis compte la part de chaque catégorie présente. Pour chaque quartier, l’équipe a moyenné les résultats de nombreuses images et comparé ces mesures basées sur l’IA aux données officielles du recensement américain sur la pauvreté et aux informations de Google Environmental Insights Explorer sur la canopée arborée.
Comparer l’IA aux chiffres officiels et à l’héritage du redlining
L’équipe a ensuite testé si les estimations de l’IA racontaient la même histoire que les statistiques officielles sur les effets persistants du redlining. En utilisant plusieurs types de modèles statistiques prenant en compte les caractéristiques locales, les différences de services municipaux et les effets de voisinage entre quartiers proches, ils ont comparé les zones historiquement redlinées à deux groupes de référence : des zones « idéales » à revenus élevés et des zones « stables ou en déclin » qui n’étaient pas marquées comme dangereuses. Dans presque toutes les versions des modèles, les deux approches d’IA ont reproduit un schéma familier : les quartiers redlinés présentent encore une pauvreté plus élevée et une couverture arborée plus faible que les zones de comparaison. De façon cruciale, les estimations de GPT-4o des écarts étaient presque identiques aux données officielles, tandis que le modèle de comptage de pixels avait tendance à sous-estimer la force du lien entre pauvreté et redlining.
Pourquoi la compréhension holistique des rues fonctionne mieux
Pour comprendre pourquoi, les auteurs ont examiné dans quelle mesure chaque méthode expliquait la variation des chiffres officiels de pauvreté et de canopée. GPT-4o seul capturait à peu près autant du schéma de pauvreté qu’un ensemble riche de statistiques démographiques et éducatives, et bien plus que le modèle de segmentation. Son avantage était particulièrement marqué dans les quartiers les plus défavorisés ou les plus riches en arbres, là où les questions de politique publique sont souvent les plus urgentes. Cela suggère que la pauvreté laisse une empreinte non seulement dans des objets isolés, comme le nombre d’arbres, mais aussi dans des indices plus larges tels que l’entretien, la forme des bâtiments et la négligence des infrastructures. La capacité de GPT-4o à considérer la scène dans son ensemble lui permet de détecter ces signaux subtils que de simples comptes de pixels peuvent manquer, tout en restant performant pour la couverture arborée, où le comptage de la canopée reste essentiel.

De nouveaux outils pour des villes plus justes et plus vertes
La conclusion de l’étude est que des instructions soigneusement conçues pour un grand modèle de langage multimodal peuvent transformer des images de rue courantes en indicateurs de pauvreté et d’ombrage arboré, à l’échelle des quartiers et de façon opportune, qui concordent étroitement avec des sources fiables. Parce que cette approche ne nécessite pas d’entrainer un nouveau modèle pour chaque ville et peut être utilisée par des non-spécialistes avec des contrôles appropriés, elle offre une voie pratique pour les urbanistes, les agences et les groupes communautaires afin de cartographier où les écarts sociaux et environnementaux se superposent, suivre l’efficacité des programmes locaux et réallouer les ressources au fur et à mesure que les besoins évoluent, tout en maintenant une supervision humaine.
Citation: Howell, A., Wu, N., Bagchi-Sen, S. et al. Multimodal large language models, street view images and urban policy-intelligence: recovering the sustainability effects of redlining. npj Urban Sustain 6, 79 (2026). https://doi.org/10.1038/s42949-026-00380-7
Mots-clés: durabilité urbaine, redlining, imagerie Street View, IA multimodale, canopée arborée