Clear Sky Science · fr
Un modèle d’apprentissage automatique pour prédire la septicémie postopératoire chez des patients chirurgicaux aigus : étude multicentrique prospective
Pourquoi cela compte pour les patients et les familles
La septicémie est une réaction potentiellement mortelle à une infection qui peut survenir après une chirurgie d’urgence, en particulier chez les personnes âgées. Les médecins savent que détecter tôt le risque de septicémie peut sauver des vies, mais il est difficile d’évaluer qui est le plus vulnérable dans la précipitation précédant une opération urgente. Cette étude examine si la reconnaissance de motifs par ordinateur, un domaine de l’intelligence artificielle appelé apprentissage automatique, peut passer au crible des données hospitalières routinières pour signaler les patients âgés susceptibles de développer une septicémie après une chirurgie d’urgence, donnant ainsi aux équipes plus de temps pour agir.
La septicémie et les dangers après une chirurgie d’urgence
La septicémie est une des principales causes de décès dans le monde, associée à des millions de cas et à plusieurs millions de décès chaque année. La chirurgie d’urgence ajoute une contrainte supplémentaire : les patients sont souvent plus âgés, plus fragiles et déjà très malades lorsqu’ils arrivent au bloc opératoire. Les infections peuvent se développer ou s’aggraver rapidement après l’intervention, et les symptômes peuvent ressembler à une récupération postopératoire normale jusqu’à ce que le patient se détériore soudainement. Les listes de contrôle et scores traditionnels aident, mais ils n’ont pas été conçus spécifiquement pour les personnes âgées nécessitant des opérations urgentes, et ils peuvent manquer ceux qui sont les plus à risque.
Transformer les données hospitalières routinières en signaux d’alerte précoces
Les chercheurs ont utilisé des informations d’une vaste étude italienne portant sur des patients âgés de 65 ans et plus ayant subi des interventions en urgence dans 29 hôpitaux. Parmi plus de 150 éléments enregistrés, ils se sont concentrés uniquement sur les détails disponibles avant la chirurgie, tels que l’âge, les maladies préexistantes, le statut fonctionnel, les signes vitaux, les analyses sanguines de base et les mesures de fragilité. Ils ont étiqueté les patients comme septiques ou non sur la base d’un score à la chevet appelé qSOFA, qui utilise la fréquence respiratoire, la tension artérielle et l’état mental pour signaler une infection dangereuse. Au total, 2563 patients ont été analysés, dont 119 répondaient aux critères de septicémie après l’intervention.
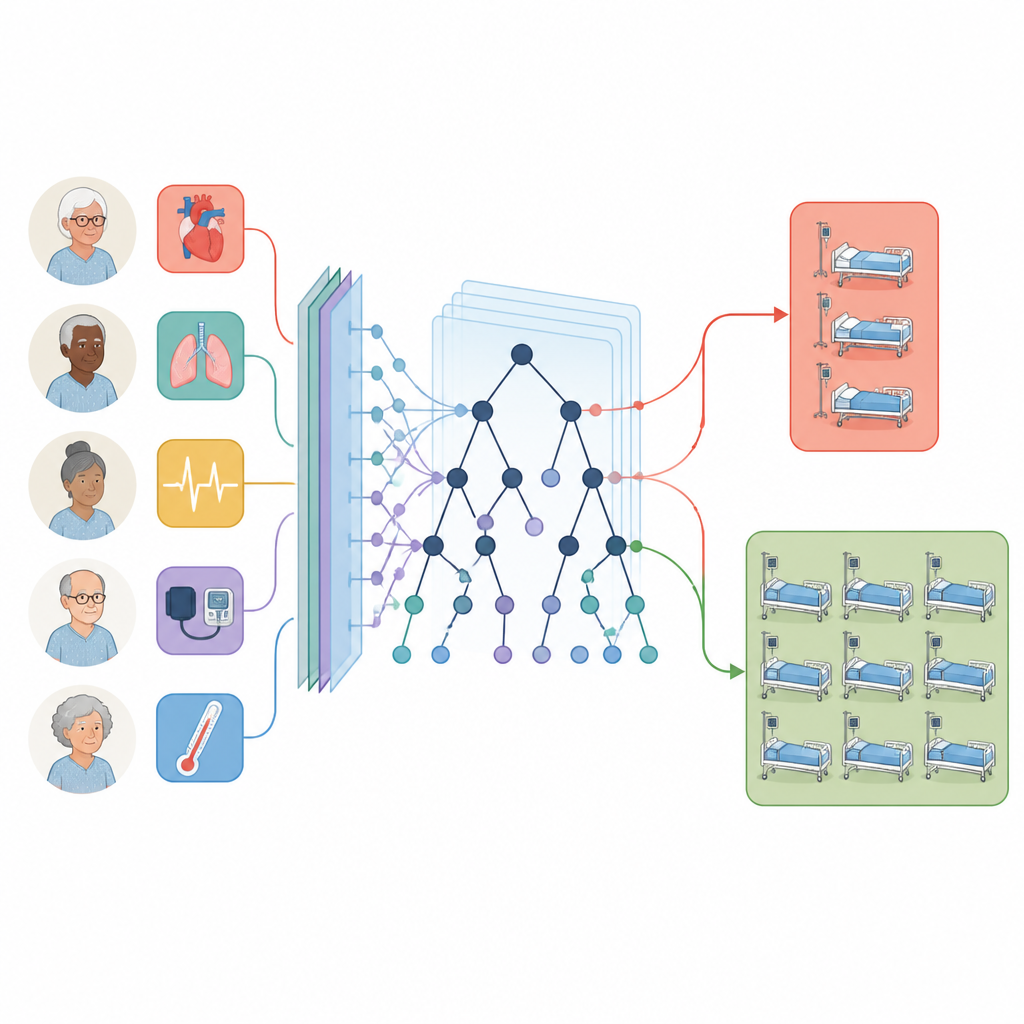
Comment les modèles informatiques ont été construits et testés
L’équipe a comparé plusieurs types de modèles d’apprentissage automatique, notamment la régression logistique, les k plus proches voisins, les forêts aléatoires et les arbres à gradient boosté. Pour éviter de se tromper eux-mêmes, ils ont utilisé une méthode de test stricte à deux niveaux connue sous le nom de validation croisée emboîtée : pour chaque itération, ils ont mis de côté certains patients comme groupe de test et n’ont ajusté les modèles que sur les cas restants. Ils ont également géré le fait que la septicémie était relativement rare en équilibrant soigneusement les données, en comblant les petites lacunes d’information et en standardisant les mesures. Les performances ont été évaluées avec des notions familières telles que la précision, la fréquence à laquelle le modèle avait raison globalement, ainsi que la sensibilité et la spécificité, qui indiquent à quelle fréquence il détecte correctement ou écarte la septicémie.
Ce que les modèles ont révélé sur le risque de septicémie
Tous les modèles d’apprentissage automatique ont nettement surpassé une stratégie simple consistant à supposer qu’aucun patient ne développerait de septicémie. Parmi les modèles individuels, les forêts aléatoires et les arbres à gradient boosté ont offert le meilleur compromis entre détection correcte de la septicémie et minimisation des fausses alertes, avec une précision globale supérieure à 95 % et une forte capacité à distinguer les patients à haut risque des patients à faible risque. Les chercheurs ont également combiné les quatre principaux modèles en un seul ensemble qui prenait une décision par vote majoritaire parmi leurs prédictions. Cette approche combinée a atteint une très haute précision, une bonne sensibilité et une excellente valeur rassurante lorsqu’elle déclarait un patient à faible risque, ce qui signifie que très peu de personnes ayant ensuite développé une septicémie avaient été manquées par le système d’alerte précoce.
Ce que cela pourrait signifier à l’hôpital
Si cela est confirmé par des études futures, ce type d’outil de risque préopératoire pourrait fournir aux équipes chirurgicales une liste pratique alimentée par les données. Avant qu’une personne âgée n’entre au bloc opératoire, le modèle pourrait analyser discrètement ses informations routinières et suggérer qui pourrait nécessiter une surveillance plus étroite, des antibiotiques plus précoces ou une prise en charge postopératoire différente. Il pourrait orienter les décisions sur le lieu de récupération du patient, comme un service standard ou une unité à plus haute intensité, et aider les hôpitaux à concentrer le personnel et les ressources limités sur ceux les plus susceptibles de développer une infection grave. L’étude ne prétend pas que le modèle soit prêt pour un usage courant, mais elle montre que l’apprentissage automatique peut transformer des informations déjà collectées en chirurgie d’urgence en alertes précoces significatives concernant le risque de septicémie.
Citation: Fransvea, P., Liuzzi, P., Costa, G. et al. A machine learning model for post-operative sepsis prediction in acute surgical patients: a multi-centre, prospective study. Sci Rep 16, 15651 (2026). https://doi.org/10.1038/s41598-026-46040-9
Mots-clés: septicémie postopératoire, chirurgie d’urgence, patients âgés, apprentissage automatique, prédiction du risque