Clear Sky Science · fr
Évaluation systématique des performances et validation d’application d’une station de travail NGS de bout en bout
Pourquoi des tests génétiques plus rapides comptent
De la prise en charge du cancer à la surveillance des nouvelles épidémies infectieuses, la médecine moderne dépend de plus en plus de la lecture rapide et précise de l’ADN. Pourtant, le travail de laboratoire en coulisses qui prépare l’ADN pour le séquençage est encore souvent réalisé manuellement, prenant de nombreuses heures et laissant place à des erreurs humaines. Cet article décrit et teste rigoureusement une station de travail entièrement automatisée conçue pour gérer l’ensemble de ce processus de préparation, dans le but de rendre les tests génétiques de haute qualité plus rapides, plus homogènes et plus faciles à industrialiser.
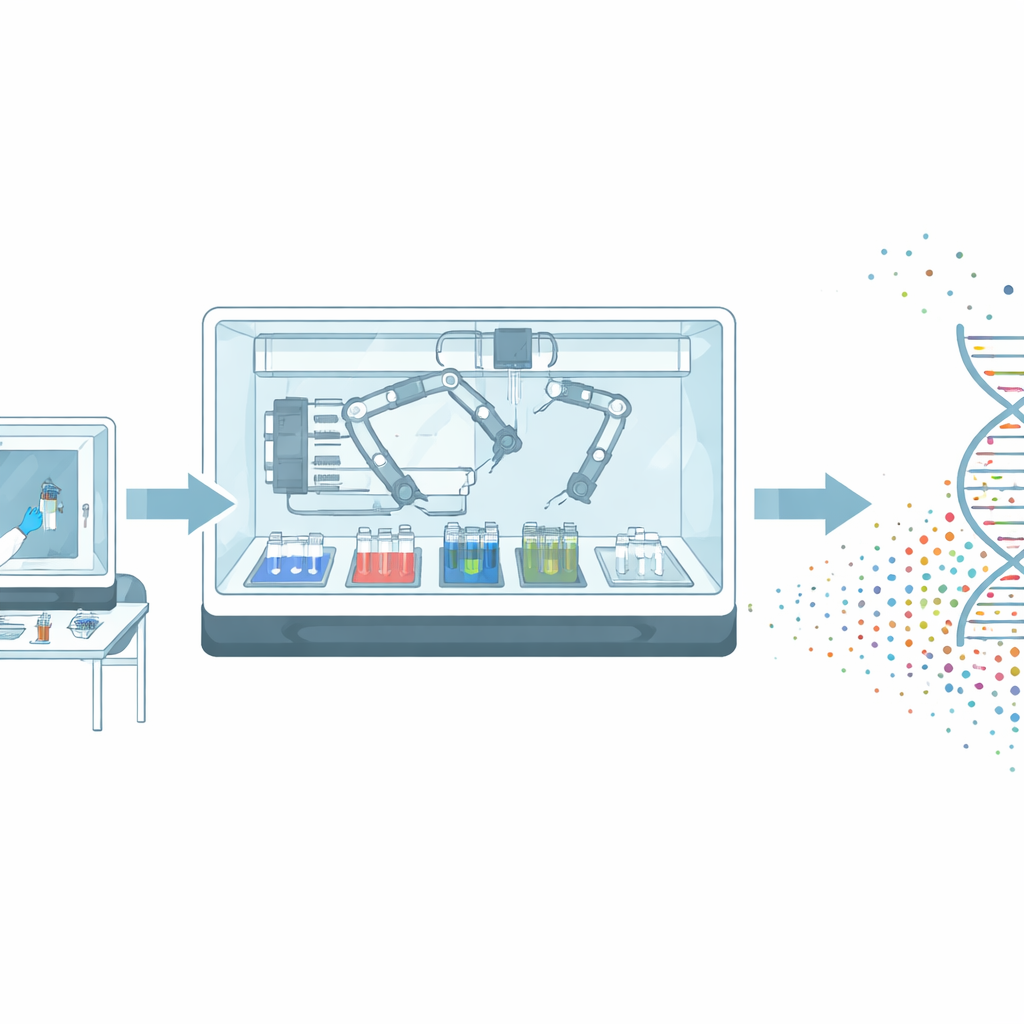
Un robot pour préparer l’ADN avant lecture
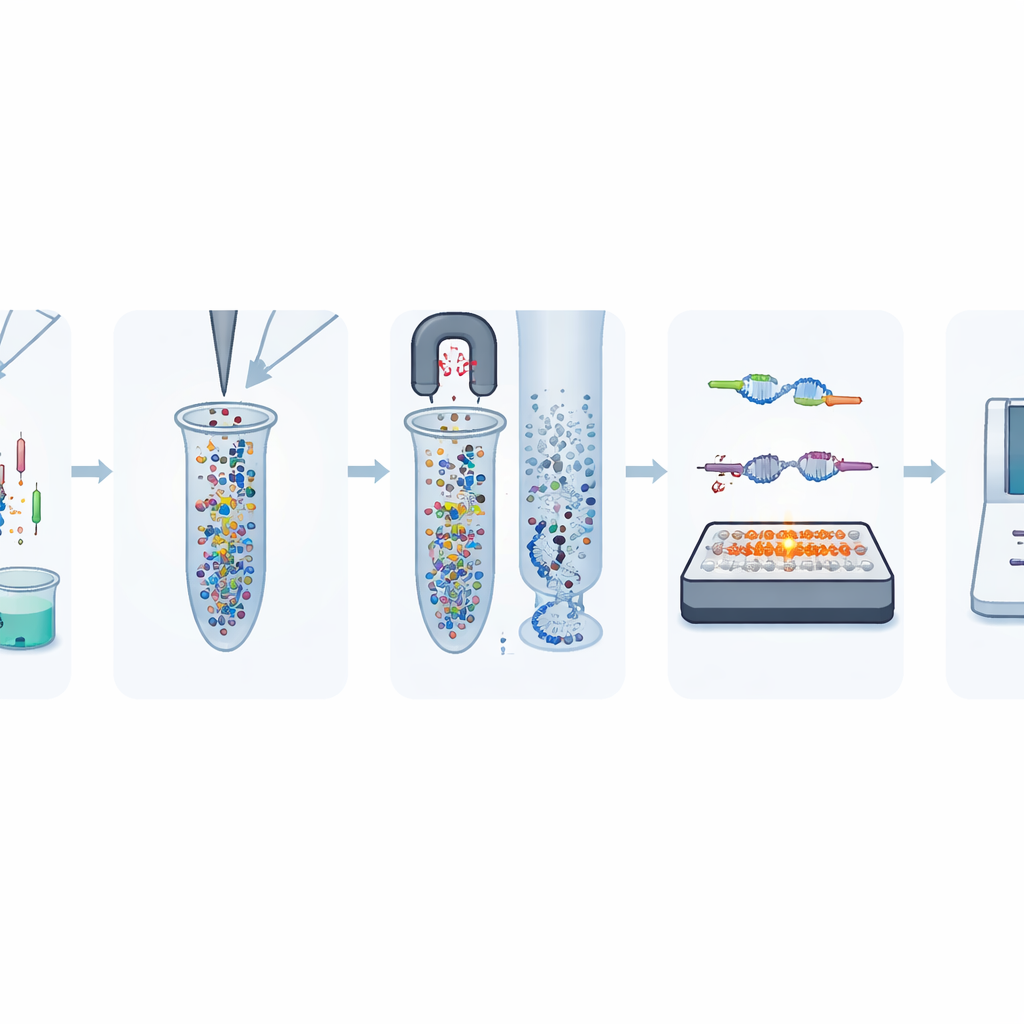
Les chercheurs présentent une famille de machines appelées stations NadAuto qui réalisent les étapes clés nécessaires avant le séquençage de l’ADN. Plutôt que des techniciens déplaçant de minuscules volumes entre tubes et appareils, le système utilise des bras robotiques, des distributeurs de liquides précis et des blocs de chauffage/refroidissement finement contrôlés à l’intérieur d’une enceinte filtrée. Les réactifs sont fournis dans des plaques scellées en portions à usage unique, ce qui simplifie la mise en place et réduit les manipulations susceptibles d’entraîner des erreurs. Un écran tactile et une interface logicielle permettent de concevoir et de simuler les flux de travail, tandis que des journaux électroniques suivent chaque série pour les besoins de qualité et de conformité réglementaire.
Assurer la séparation des échantillons
Une crainte en matière de tests génétiques à haut débit est que des traces d’ADN d’un échantillon contaminent un autre, produisant de faux résultats. Pour explorer ce risque, l’équipe a réalisé une série de tests en « échiquier » où des puits contenant de l’ADN humain alternaient avec des puits contenant uniquement de l’eau propre, ou avec de l’ADN bactérien, sur la même plaque. Même après avoir perturbé volontairement le système pendant une étape critique d’amplification, ils ont constaté que les puits censés être négatifs n’affichaient que des signaux au niveau du bruit de fond. Lors du séquençage de plaques mixtes d’ADN humain et bactérien, presque toutes les lectures se sont mappées sur la bonne espèce, la contamination croisée maximale étant de seulement trois sur un million de lectures — preuve que l’installation automatisée maintient efficacement l’isolement des échantillons.
Des résultats cohérents selon la charge de travail
Les auteurs ont ensuite vérifié si le robot pouvait produire des « bibliothèques » d’ADN — les fragments d’ADN préparés prêts pour le séquençage — avec la même fiabilité qu’un technicien expérimenté. En utilisant des échantillons d’ADN humain standards, ils ont comparé plusieurs séries à différents débits, depuis de petits lots de 8 ou 16 échantillons jusqu’à des lots plus importants de 24 ou 48. Dans toutes ces conditions, les rendements de bibliothèques étaient élevés et étroitement regroupés, la variation d’un lot à l’autre restant généralement inférieure à 8 %, soit moins que pour les flux de travail manuels typiques. Les tailles des fragments d’ADN se situaient clairement dans la plage exigée par les séquenceurs courants, sans excès de fragments très courts ou très longs susceptibles de dégrader la qualité des données.
Tester des panels ciblés de gènes
Au‑delà de la préparation basique, de nombreux tests cliniques et de recherche se concentrent sur des ensembles spécifiques de gènes, comme des régions liées au cancer. La station a été évaluée avec de tels panels ciblés utilisant une étape de capture qui prélève les régions d’ADN choisies. En mode haut débit comme en mode moyen débit, les données de séquençage obtenues présentaient une qualité globale élevée, un fort alignement sur le génome de référence humain et une couverture homogène des gènes ciblés, y compris des régions plus difficiles à capturer en raison d’une composition en bases atypique. Fait important, le système a réduit la proportion de lectures dupliquées par rapport aux méthodes manuelles, ce qui indique des bibliothèques plus diverses et plus informatives.
Les résultats automatisés correspondent‑ils au travail humain ?
Pour déterminer si ces gains techniques se traduisent par des réponses utiles en pratique, l’équipe a comparé les performances du robot à la préparation manuelle sur des échantillons de référence contenant des mutations liées au cancer et des variations du nombre de copies de gènes. Les deux approches ont correctement détecté toutes les mutations ponctuelles attendues et les petites insertions/délétions, avec des fréquences de mutation très proches entre elles et des valeurs de référence, y compris pour des variants rares présents autour d’un pour cent. Les mesures d’amplification génique, comme des copies supplémentaires de MET et ERBB2, concordaient également étroitement entre les runs manuels et automatisés, avec des différences de seulement quelques pourcents et sans incidence sur l’interprétation.
Ce que cela signifie pour les tests futurs
Globalement, l’étude montre qu’une station de travail entièrement automatisée peut réduire d’environ moitié le temps de traitement total tout en maintenant, et à certains égards en améliorant, la qualité et la fiabilité des préparations pour le séquençage de l’ADN. Pour les cliniciens et les équipes de santé publique, cela signifie des tests génétiques plus rapides, moins sujets à la variabilité humaine et plus faciles à standardiser entre laboratoires. Si des travaux supplémentaires sont nécessaires pour des types d’échantillons plus difficiles, comme des tissus tumoraux dégradés, les résultats suggèrent que l’automatisation de bout en bout est prête à soutenir la demande croissante d’analyses génomiques précises et à grande échelle.
Citation: Xie, W., Yang, C. & Ren, S. Systematic performance evaluation and application validation of an end-to-end NGS workstation. Sci Rep 16, 13115 (2026). https://doi.org/10.1038/s41598-026-43941-7
Mots-clés: séquençage automatisé de l’ADN, préparation de bibliothèques NGS, diagnostic génomique, flux de travail en génomique clinique, automatisation de laboratoire